Intro
Recently I wanted to deepen my understanding of bash by researching as much of it as possible. Because I felt bash is an often-used (and under-understood) technology, I ended up writing a book on it.
A preview is available here.
You don’t have to look hard on the internet to find plenty of useful one-liners in bash, or scripts. And there are guides to bash that seem somewhat intimidating through either their thoroughness or their focus on esoteric detail.
Here I’ve focussed on the things that either confused me or increased my power and productivity in bash significantly, and tried to communicate them (as in my book) in a way that emphasises getting the understanding right.
Enjoy!

1) `` vs $()
These two operators do the same thing. Compare these two lines:
$ echo `ls` $ echo $(ls)
Why these two forms existed confused me for a long time.
If you don’t know, both forms substitute the output of the command contained within it into the command.
The principal difference is that nesting is simpler.
Which of these is easier to read (and write)?
$ echo `echo \`echo \\\`echo inside\\\`\``
or:
$ echo $(echo $(echo $(echo inside)))
If you’re interested in going deeper, see here or here.
2) globbing vs regexps
Another one that can confuse if never thought about or researched.
While globs and regexps can look similar, they are not the same.
Consider this command:
$ rename -n 's/(.*)/new$1/' *
The two asterisks are interpreted in different ways.
The first is ignored by the shell (because it is in quotes), and is interpreted as ‘0 or more characters’ by the rename application. So it’s interpreted as a regular expression.
The second is interpreted by the shell (because it is not in quotes), and gets replaced by a list of all the files in the current working folder. It is interpreted as a glob.
So by looking at man bash can you figure out why these two commands produce different output?
$ ls * $ ls .*
The second looks even more like a regular expression. But it isn’t!
3) Exit Codes
Not everyone knows that every time you run a shell command in bash, an ‘exit code’ is returned to bash.
Generally, if a command ‘succeeds’ you get an error code of 0. If it doesn’t succeed, you get a non-zero code. 1 is a ‘general error’, and others can give you more information (eg which signal killed it, for example).
But these rules don’t always hold:
$ grep not_there /dev/null $ echo $?
$? is a special bash variable that’s set to the exit code of each command after it runs.
Grep uses exit codes to indicate whether it matched or not. I have to look up every time which way round it goes: does finding a match or not return 0?
Grok this and a lot will click into place in what follows.
4) if statements, [ and [[
Here’s another ‘spot the difference’ similar to the backticks one above.
What will this output?
if grep not_there /dev/null
then
echo hi
else
echo lo
fi
grep’s return code makes code like this work more intuitively as a side effect of its use of exit codes.
Now what will this output?
a) hihi
b) lolo
c) something else
if [ $(grep not_there /dev/null) = '' ] then echo -n hi else echo -n lo fi if [[ $(grep not_there /dev/null) = '' ]] then echo -n hi else echo -n lo fi
The difference between [ and [[ was another thing I never really understood. [ is the original form for tests, and then [[ was introduced, which is more flexible and intuitive. In the first if block above, the if statement barfs because the $(grep not_there /dev/null) is evaluated to nothing, resulting in this comparison:
[ = '' ]
which makes no sense. The double bracket form handles this for you.
This is why you occasionally see comparisons like this in bash scripts:
if [ x$(grep not_there /dev/null) = 'x' ]
so that if the command returns nothing it still runs. There’s no need for it, but that’s why it exists.
5) sets
Bash has configurable options which can be set on the fly. I use two of these all the time:
set -e
exits from a script if any command returned a non-zero exit code (see above).
This outputs the commands that get run as they run:
set -x
So a script might start like this:
#!/bin/bash set -e set -x grep not_there /dev/null echo $?
What would that script output?
6) <()
This is my favourite. It’s so under-used, perhaps because it can be initially baffling, but I use it all the time.
It’s similar to $() in that the output of the command inside is re-used.
In this case, though, the output is treated as a file. This file can be used as an argument to commands that take files as an argument.
Confused? Here’s an example.
Have you ever done something like this?
$ grep somestring file1 > /tmp/a $ grep somestring file2 > /tmp/b $ diff /tmp/a /tmp/b
That works, but instead you can write:
diff <(grep somestring file1) <(grep somestring file2)
Isn’t that neater?
This is based on some of the contents of my book Learn Bash the Hard Way

Preview available here.
7) Quoting
Quoting’s a knotty subject in bash, as it is in many software contexts.
Firstly, variables in quotes:
A='123' echo "$A" echo '$A'
Pretty simple – double quotes dereference variables, while single quotes go literal.
So what will this output?
mkdir -p tmp cd tmp touch a echo "*" echo '*'
Surprised? I was.
8) Top three shortcuts
There are plenty of shortcuts listed in man bash, and it’s not hard to find comprehensive lists. This list consists of the ones I use most often, in order of how often I use them.
Rather than trying to memorize them all, I recommend picking one, and trying to remember to use it until it becomes unconscious. Then take the next one. I’ll skip over the most obvious ones (eg !! – repeat last command, and ~ – your home directory).
!$
I use this dozens of times a day. It repeats the last argument of the last command. If you’re working on a file, and can’t be bothered to re-type it command after command it can save a lot of work:
grep somestring /long/path/to/some/file/or/other.txt vi !$
!:1-$
This bit of magic takes this further. It takes all the arguments to the previous command and drops them in. So:
grep isthere /long/path/to/some/file/or/other.txt egrep !:1-$ fgrep !:1-$
The ! means ‘look at the previous command’, the : is a separator, and the 1 means ‘take the first word’, the - means ‘until’ and the $ means ‘the last word’.
Note: you can achieve the same thing with !*. Knowing the above gives you the control to limit to a specific contiguous subset of arguments, eg with !:2-3.
:h
I use this one a lot too. If you put it after a filename, it will change that filename to remove everything up to the folder. Like this:
grep isthere /long/path/to/some/file/or/other.txt cd !$:h
which can save a lot of work in the course of the day.
9) startup order
The order in which bash runs startup scripts can cause a lot of head-scratching. I keep this diagram handy (from this great page):
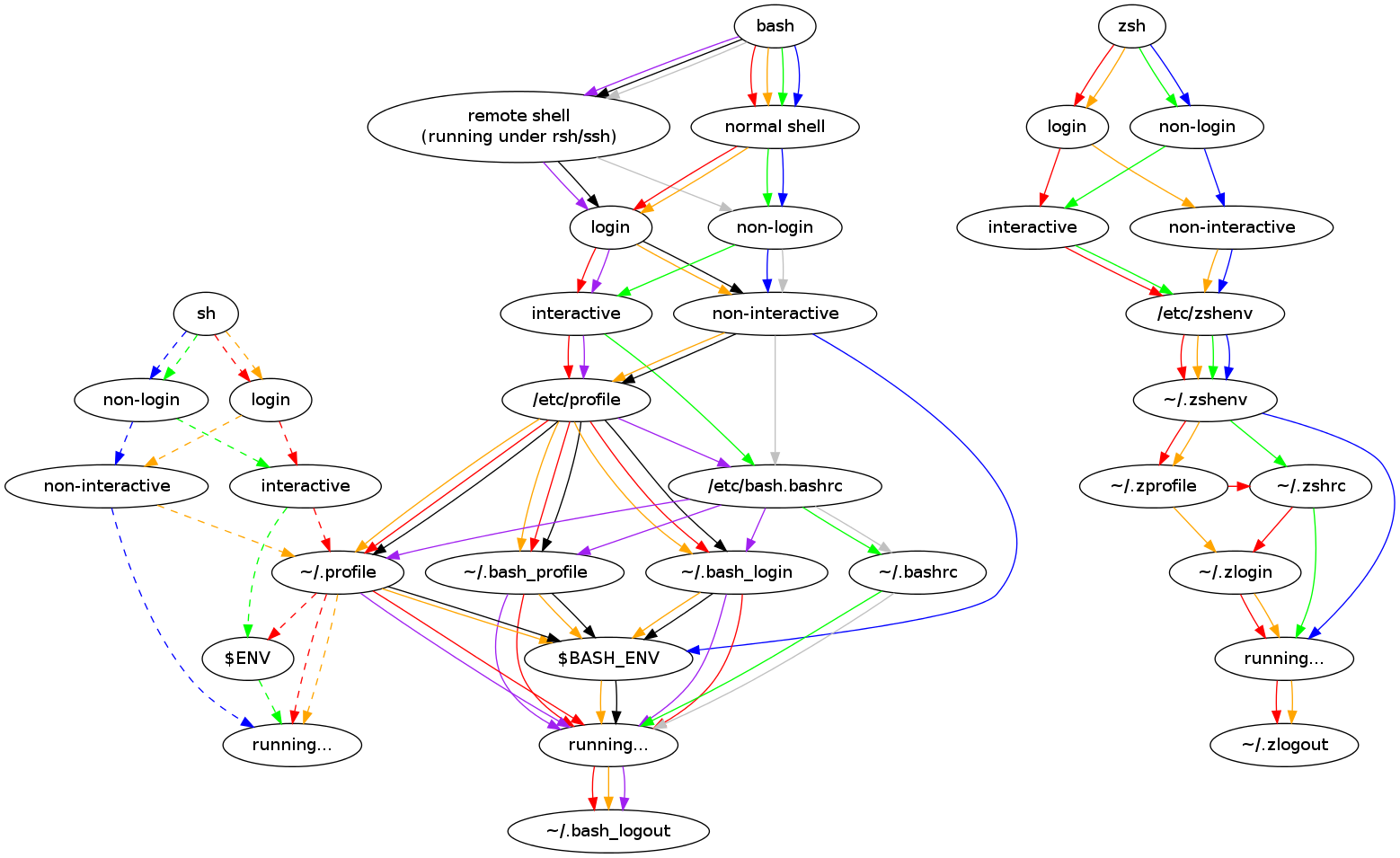
It shows which scripts bash decides to run from the top, based on decisions made about the context bash is running in (which decides the colour to follow).
So if you are in a local (non-remote), non-login, interactive shell (eg when you run bash itself from the command line), you are on the ‘green’ line, and these are the order of files read:
/etc/bash.bashrc ~/.bashrc
[bash runs, then terminates]
~/.bash_logout
This can save you a hell of a lot of time debugging.
10) getopts (cheapci)
If you go deep with bash, you might end up writing chunky utilities in it. If you do, then getting to grips with getopts can pay large dividends.
For fun, I once wrote a script called cheapci which I used to work like a Jenkins job.
The code here implements the reading of the two required, and 14 non-required arguments. Better to learn this than to build up a bunch of bespoke code that can get very messy pretty quickly as your utility grows.
If you enjoyed this, then please consider buying me a coffee to encourage me to do more.

pretty good — and rename(1) was new to me…
in 4, if [ “$(grep not_there /dev/null)” = ” ] works — the [ x”`cmd`” = x ] is from time test(1) could not handle empty strings even in “”
in modern shells (like bash) it is better to replace (nonstandard) “echo -n” with printf …
I use ‘ESC .’ in place of !$ (now that I tried !$ I accidentally wrote $! 😉
In 4, I personally find ‘set -u’ more important than set -e — i actually start my scripts with ‘set -euf’
I can understand why 7 is suprising — but pretty elementary once one thinks it a bit.
Isn’t !* the same as !:1-$ ?
Diagram has like 10 colors, it only says what one of them means. Here’s something else you should know about bash: it’s documentation is licensed under gfdl1.3, meaning anyone can contribute to it and redistribute it among other things. This is documentation is licensed under the default license of all rights reserved and does not give those rights. So for example, if the official documentation wanted to use some of this text, they couldn’t. That’s not nice. Please use a gfdl1.3 compatible license, such as gfdl1.3 or cc-by.
${PIPESTATUS[]} is better than $? because it gets you the status of the pipeline element you really want every time.
Consider what happens to:
$ grep foo /dev/null
$ echo $?
when you decide to try to pipe the output:
$ grep foo /dev/null | some_command
$ echo $?
This is very easy to overlook when modifying something after the fact. Now if instead your original example was:
$ grep foo /dev/null
$ echo ${PIPESTATUS[0]
adding “| some_command” to the first line does not alter the results of the second line.
I was trying to follow your example in section 9 “Startup Order,” and was wondering why you say it’s following the green line, but it doesn’t go through ~/.bash_logout
(It makes sense to me that an interactive session wouldn’t call the logout script, so maybe I misunderstood your example.)
I was trying to follow your example in section 9 “Startup Order,” and was wondering why you say it’s following the green line, but the green line doesn’t go through ~/.bash_logout
(It makes sense to me that an interactive session wouldn’t call the logout script, so maybe I misunderstood your example.)
The green line is for a non-login shell (ie., you’re already logged on and open a bash session). So it doesn’t run ~/.bash_logout when it exits.
!:1-$ can also be written as !*
mnemonic: the glob-asterisk catches all arguments of the last command
excellent bash tips hav you tried Fish by any chance? very powerful shell
2) “The two asterisks are interpreted in different ways.”
Yes, but in a regexp a “*” applies to what it follows. In a regexp, “*” by itself doesn’t mean “0 or more characters”, it means “0 or more occurrences of what precedes it” — so “.*” means “0 or more characters. In a glob, “*” by itself means “0 or more characters”.
3) “I have to look up every time which way round it goes: does finding a match or not return 0?”
If you use grep in a condition think of it as “does the pattern appear?”. Also, when used as a condition both “diff” and “cmp” mean “are the inputs identical (which is admittedly a little confusing in the case of diff).
4) “This is why you occasionally see comparisons like this in bash scripts:
if [ x$(grep not_there /dev/null) = ‘x’ ]”
It’s cleaner to enclose the $(…) expression in double quotes, which forces it to be treated as a single word even if it’s empty.
if [ “$(grep not_there /dev/null)” = “” ] ; then … ; fi
5) sets
Each of the “set -x” commands corresponds to a bash command-line option; executing “set -x” is like invoking “bash -x”. There are also more user-friendly equivalents for most or all of them. For example “set -o xtrace” is equivalent to “set -x”, and “set -o errexit” is equivalent to “set -e”. (The bash manual doesn’t make it particularly easy to find these.)
6) <()
The "<()" construct expands to a file name, so commands don't have to do anything special to refer to it. For example, on my system "echo <(echo foo) <(echo bar)" prints "/dev/fd/63 /dev/fd/62".
7) quoting
I don't find it surprising that
echo "*"
prints a literal '*' character. Single quotes inhibit both wildcard expansions and variable expansions. Double quotes inhibit wildcard expansions but do not inhibit variable expansions.
8) Top three shortcuts
!:1-$ can also be written as !*
The :h expansion only works in history substitutions. Your example
ls /long/path/to/some/file/or/other.txt:h
attempts to list a file whose name literally ends in ":h". (csh and tcsh support ":h" et al on variable expansions; bash doesn't.)
But bash does have a powerful set of modifiers for variable expansion (called "parameter expansion" in the bash manual), documented here:
https://www.gnu.org/software/bash/manual/html_node/Shell-Parameter-Expansion.html
You can also use command substitution for the above example:
$ grep isthere /long/path/to/some/file/or/other.txt
$ ls $(dirname !$)
Great article. Lots of useful tidbits.
Regarding ` !:1-$`. An easier form to use is` !*` (bang splat). It does the same thing and is easier to type.Also, you can add `:p` to any of these to print the result and not execute it. Then, after verifying it is what you want a quick `!!` will execute it.
Keep writing.
:h doesn’t work for me. I’m running bash 4.3.46, and I get “No such file or directory” as if it is literally making :h part of the file name.
I once wrote a one liner to parse out of order arguments in long and short forms. A bash master like you might get a kick out of how this works.
aes-encrypt.sh
eval “declare -A vars=(“$(getopt -a -o i:o:s: –long in:,out:,sec: -n ‘aes-encrypt.sh’ — “$@” | sed ‘s/–$//g; s/-\+/-/g; s/-\([a-z]\)\([a-z]*\)[[:space:]]/[“\1″]=/g’)”)” && openssl enc -aes-128-cbc -in “${vars[i]}” -out “${vars[o]}” -p >> “${vars[s]}” || echo ‘ಠ_ಠ…pls lrn2computar’
Essentially it creates an array of the getopts output that have been sanitized using sed. You can then use the dictionary array that is holding the arguments named by their argument letter. In this case, input is vars[i], output is vars[o] etc. This avoids long and ugly switch statements for argument parsing and is resilient to out of order and and long/short forms.
On [ vs [[ behavior, please execute the command “which [” and take it from there. Some things predate bash and are simply sh
Nice explanation! Thanks!
I was confused with [ all the time, even after reading this article.
Number 7, quoting: In the “echo” section, you should try three things. echo “*” and echo ‘*’ do the same thing, which is to display an asterisk. However, echo * (i.e. without the quotes) will display the files within the folder (in this case, the letter ‘a’), because Bash will expand the unquoted asterisk before calling ‘echo’.
Interesting. Love what you’ve done. With getopt it has had a scared past not being supported in every envirinment. For years I instead would copy paste this bash only solution: https://tritarget.org/static/getopt.sh.html
I disagree with 10).
One could simply shift the arguments and write a `case` for the options to consume the args.
Not that simple if you have a mix of long and short arguments, some of which take mandatory arguments, some optional, and some none!
Fantastic website. Lots of useful information here.
I’m sending it to some pals ans also sharing in delicious.
And obviously, thank you for your effort!
Very good intro. The only bash feature in your list above that I haven’t used is <(), I'll definitely use it in future.
I'd strongly recommend:
set -u
Which will exit on any attempts to use uninitialised variables.
I'm a huge fan of the shebang history. Some more that you might consider using:
– Reference the current command with !# – for example: cp filename !#^.backup
– Print before use !23:p – this will show command 23 without executing it but will put it in history, and if it's the one you want you can just type !!
– Search !?string? – for example (combining with the :p) the last command that contained 'vi': !?vi?:p
Philip
I came here from an O’Reilly email and bought your book.
Thanks!
Hi,
$ if [ x$(grep not_there /dev/null) = ‘x’ ]; then true; fi
Be careful with this, as grep may return spaces:
$ a=’1 2′; if [ x$a = x ]; then echo true; fi
This fails as an example. This is present on ./configure in case the shell used is an antique non-POSIX shell. What about using the safer and POSIX-compatible form:
$ a=’1 2′; if [ “$a” = ” ]; then echo true; fi
or even:
$ a=’1 2′; if [ -z “$a” ]; then echo true; fi
or also
$ a=’1 2′; if ! [ “$a” ]; then echo true; fi
and thank you for taking the time to share what the experience revealed to be useful, it feels that the shell syntax is either perceived as mystical or simply not transmitted at all.
Fortunately, the POSIX manual pages or the more readable man page of each implementation preserve all of it.
Oh shit, I’m sorry, someone already pointed this to you in a previous comment.
re: cheap ci script – it’s worth stating the maintenance of a bash script of any significant size has diminishing returns compared to a programming language like Go or Python. I’ve fallen foul of this in the past (as a bash masochist).
you missed the shortcut I use most: you can search your history with CTRL-R
u made my day with that post!
if [ $(grep not_there /dev/null) = ” ]
then
echo -n hi
else
echo -n lo
fi
This command dummy spits with “-bash: [: =: unary operator expected”
This command returns “hi”
if [ $(grep not_there /dev/null)=” ]
then
echo -n hi
else
echo -n lo
fi
The difference is the white-space around ‘=’ and is the sort of thing that catches me out in BASH
Try using double brackets instead.
[[ $(grep not_there /dev/null) = ” ]] && echo -n hi || echo -n lo
You don’t need the brackets at all, grep returns a success/fail value:
if grep not_there /dev/null
then echo there
else echo “not there
fi