Intro
Over time I’ve built up a few different small applications which do simple things like track share prices, or track whether a particular file has changed on GitHub. Little apps that only I use.
While building these I’ve come to use an unorthodox application patterns that allow me to run them ‘serverless’ and without the context of a specific cloud provider.
Since they contain the code and accompanying data, they can be run anywhere that Docker and an internet connection is available.
The key ideas are:
- use Git to store the entire context of the application (including data)
- use Git’s distributed nature to remove a central server requirement
- use Docker to ensure the run context is reproducible
This serverless pattern might be useful as thought-provokers for others who write little one-off apps.
Using Git as a Database
What, essentially, is a database? It is a persistent store of data that you can look up data in.
It doesn’t need to support SQL, be multi-threaded, even have a process running continuously.
For many applications, I use Git as a database. Git has a few useful features that many databases share:
- a logical log (using ‘git log’)
- a backup/restore mechanism (git push/pull)
- ability to do transactions ‘commit’
And a few features that many don’t:
- ability to restore older versions
- ability to arbitrate between forks of data
However, git can’t easily be made to do the following things as a database:
- query data using SQL
- store huge amounts of data
- concurrency (without a lot of pain!)
- performance
For my purposes, this is sufficient for a large proportion of my mini-app use cases.
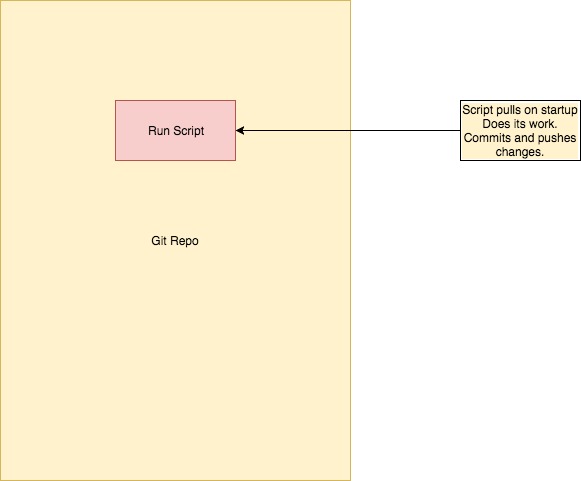
A trivial example of this is available here, using a trivial app that stores the date last run.
A limited form of querying the history is available using ‘git diff’:
$ git diff 'gitdb@{1 minute ago}'
diff --git a/date.txt b/date.txt
index 65627c8..d02c5d8 100644
--- a/date.txt
+++ b/date.txt
@@ -1 +1 @@
-Sat 5 Aug 2017 10:37:33 CEST
+Sat 5 Aug 2017 10:39:47 CEST
Or you can use ‘git log –patch’ to see the history of changes.
$ git log --patch commit ab32781c28e02799e2a8130e251ac1c990389b65 Author: Ian Miell <ian.miell@gmail.com> Date: Sat Aug 5 10:39:47 2017 +0200 Update from app_script.sh diff --git a/date.txt b/date.txt index 65627c8..d02c5d8 100644 --- a/date.txt +++ b/date.txt @@ -1 +1 @@ -Sat 5 Aug 2017 10:37:33 CEST +Sat 5 Aug 2017 10:39:47 CEST commit a491c5ea1c9c1660cc64f88921f43fe0040e3832 Author: Ian Miell <ian.miell@gmail.com> Date: Sat Aug 5 10:37:33 2017 +0200 Update from app_script.sh diff --git a/date.txt b/date.txt index a87844b..65627c8 100644 --- a/date.txt +++ b/date.txt @@ -1 +1 @@ -Sat 5 Aug 2017 10:37:23 CEST +Sat 5 Aug 2017 10:37:33 CEST
Note that the application is stateless – the entire state of the system (including data and code) is stored within the git repo. The application can be stood up anywhere that git and bash are available without ‘interruption’.
This statelessness is a useful property for small applications, and one we will try to maintain as we go on.
When Git Alone Won’t Do
The first limit I hit with this approach is generally the limited querying that I can do on the data that’s stored.
That’s when I need SQL to come to my aid. For this I generally use sqlite, for a few reasons:
- It’s trivial to set up (database is stored in a single file)
- It’s trivial to back up/restore to a text-based .sql file
- It’s a good implementation of SQL for the purposes of basic querying
Again, it has limitations compared to ‘non-lite’ sql databases:
- Does not scale in size (because the db is a single file)
- Data types are simple/limited
- No user manager
- Limited tuning capability
Using sqlite’s backup and restore functionality along with git means we can retain the stateless nature of the application while getting the benefits of SQL querying to mine the data.
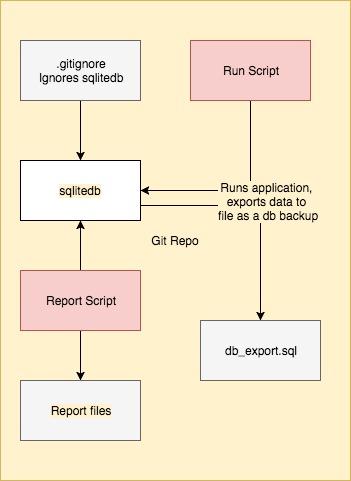
As an example I use this pattern to keep track of my share holdings. I can use this to calculate my position/total profit on a daily basis (including dividends) and look at whether I’m genuinely up or down.
I can query the data using sql and persist these queries to ‘report’ files, which are stored in git also, meaning I can run time-based ‘queries’ like this:
$ git diff 'master@{1 weeks ago}' reports/profits.txt | grep -A10 Overall.profit
Overall profit
================================================================================
current_value profit
------------- ----------
-XXXX.XX NNNN.NNNN
+YYYY.YY MMMM.MMMM
Which tells me how my overall profit looks compared to 1 week ago.
A trivial example of such an app which (continuing from the above example) stores the dates the application was run in a sqlite db, is available here.
Note that we use .gitignore to ignore the actual db file – the sqlite db is a binary object not well stored in git, and the db can be reconstructed from the db_export.sql backup anywhere.
Using Docker for Portability and Statelessness
Sqlite, git, bash… even with our trivial example the dependencies are mounting up.
One way to manage this is to have your application run in a Docker container.
This is where things get a bit more complicated!
The simplified diagram below helps explain what’s going on. The Dockerfile (see below) creates an image which includes the entire git repo as a folder. The application runs within this image as a container, and imports and exports the sqlite database before and after running the application.
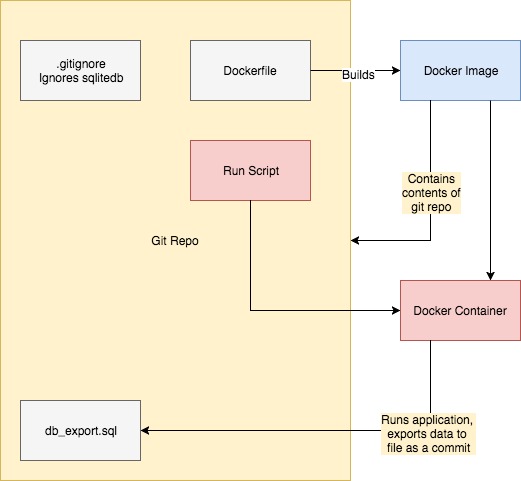
An example application continuing the above ‘date’ one is here.
The files it contains are:
- db_export.sql
- Dockerfile
- access_db.sh
- app_script.sh
- run.sh
db_export.sql
The db_export.sql is the same exported sqlite3 db as in the previous section.
Dockerfile
Here is an annotated Dockerfile:
FROM ubuntu:xenial
# Install the needed applications.
RUN apt-get update -y && apt-get install -y sqlite3 git
# Create the folder we will copy our own contents to.
RUN mkdir /gitdb-sqlite-docker
# This folder should be the default working directory, and the
# working directory from here
WORKDIR /gitdb-sqlite-docker
# Add the contents of the git repo to the image.
ADD . /gitdb-sqlite-docker
# Configure git for me.
RUN git config --global user.email "ian.miell@gmail.com"
RUN git config --global user.name "Ian Miell"
# Expect a github password to be passed in
ARG GITHUB_PASSWORD
# Set the origin so that it can pull/push without logging in
RUN git remote set-url origin \
https://ianmiell:${GITHUB_PASSWORD}@github.com/ianmiell/git-app-patterns
# The image runs the application by default.
CMD /gitdb-sqlite-docker/app_script.sh
run.sh
This script runs the container. Before doing this, it:
- Checks we are not in the container
- Checks the git history is consistent with the remote
- Gets the github password
- Rebuilds the image
- Runs the image
#!/bin/bash
# Exit on error.
set -e
# Only run outside the container
if [ -e /.dockerenv ]
then
echo 'Must be run outside container only'
exit 1
fi
# Pull to check we are in sync and checked in.
git pull --rebase -s recursive -X ours origin gitdb-sqlite-docker
# Make sure a github password is supplied
GITHUB_PASSWORD=${1}
if [[ $GITHUB_PASSWORD == '' ]]
then
echo 'Input github password: '
read -s GITHUB_PASSWORD
fi
IMAGE_NAME='gitdb-sqlite-docker'
# Build the image.
docker build --build-arg GITHUB_PASSWORD=${GITHUB_PASSWORD} -t ${IMAGE_NAME} .
# Run the container.
docker run ${IMAGE_NAME}
app_script.sh
This script is run from the running container. It’s the same as the previous example’s
#!/bin/bash
# Exit on error.
set -e
# Only run inside the container
if [ ! -e /.dockerenv ]
then
echo 'Must be run in container only'
exit 1
fi
# Make sure the code is up to date with the origin, preferring any local
# changes we have made. Rebase to preserve a simpler history.
git pull --rebase -s recursive -X ours origin gitdb-sqlite-docker
DBNAME='dates.db'
DBEXPORTFILE='db_export.sql'
rm -f ${DBNAME}
# Import db from git
cat ${DBEXPORTFILE} | sqlite3 ${DBNAME}
# The trivial 'application' here simply writes the date to a file.
DATE="$(date '+%Y-%m-%d %H:%M:%S')"
echo $DATE
echo "insert into dates(date) values(\"${DATE}\");" | sqlite3 ${DBNAME}
# Export db from sqlite
echo ".dump" | sqlite3 ${DBNAME} > ${DBEXPORTFILE}
# Commit the change made.
git commit -am 'Update from app_script.sh'
# Push the changes to the origin.
git push -u origin gitdb-sqlite-docker
access_db.sh
This script is similar to the others, except that it gives you access to the database should you want to query it directly.
Makefiles for an Application Interface
At this point (especially if your app is getting a little complicated) it can get a little hairy to keep track of all these scripts, especially what should be run in the running container vs the image.
At this point I usually introduce a Makefile, which allows me to consolidate some code and effectively provides me with an application interface.
If I run ‘make’ I get some help by default:
$ make make run - run the dates script make access - access the dates db
Running ‘make run’ will build the docker image and run the container, adding a date to the database. ‘make access’ gives me access to the database directly as before.
Adding this makefile means that I have a standard interface to running the application – if I have an application of this type, just running ‘make’ will tell me what I can and should do.
Here’s what the Makefile looks like:
help: @echo 'make run - run the dates script' @echo 'make access - access the dates db' .PHONY: help run access restore check_host check_container check_nodiff access: check_host check_nodiff restore # Access the db. sqlite3 dates.db # Remove the db. rm -f dates.db run: check_host check_nodiff # run the script ./run.sh @$(MAKE) -f Makefile check_nodiff restore: check_nodiff rm -f dates.db cat db_export.sql | sqlite3 dates.db check_host: # only run in a host if [ -e /.dockerenv ]; then exit 1; fi check_container: # only run in a container if [ ! -e /.dockerenv ]; then exit 1; fi check_nodiff: # Pull to check we do not have local changes git pull --rebase -s recursive -X ours origin gitdb-sqlite-docker-makefile
and the rest of the code is available here.
Summary
As with everything in IT, there is nothing new under the sun.
You could replace git and Docker with a tar file and an extra shell script to manage it all, and you have something that might look similar.
However, I find this a very useful pattern for quickly throwing up a data-based application that I can run and maintain myself without too much hassle or state management. It uses standard tools, has a clean interface and is genuinely portable across providers.
This is based on work in progress from the second edition of Docker in Practice
Get 39% off with the code: 39miell2

Just letting you know I’ve found the place and will be doing the subscribe thing and all that.
I look forward to learning.