Have you ever run a command on one of your hosts and then wanted to retrieve it later? Then couldn’t remember where you ran it, or it’s lost from your history?
This happens to me all the time. The other day I was hunting for a command I was convinced I’d run, but wasn’t sure where it was or whether it was stored.
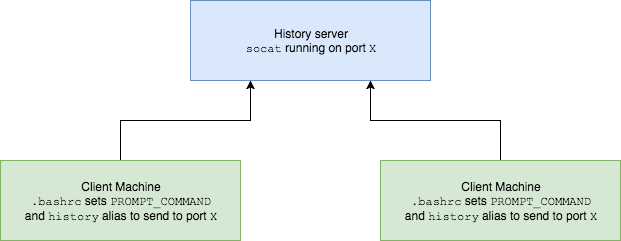
So I finally wrote a service that records my every command centrally.
Here’s an overview of its (simple) architecture.
What?
This stores your bash history on a server in a file.
The service runs on a port of your choosing, and if you have some lines in your ~.bashrc file then it will all work seamlessly for you.
There’s some basic authentication (shared key) to prevent abuse of the service.
Despite my woeful knowledge of networking, I run my own DNS servers on my own websites run from home.
I achieved this through trial and error and now it requires almost zero maintenance, even though I don’t have a static IP at home.
Here I share how (and why) I persist in this endeavour.
Overview
This is an overview of the setup:
This is how I set up my DNS. I:
got a domain from an authority (a .tk domain in my case)
set up glue records to defer DNS queries to my nameservers
set up nameservers with static IPs
set up a dynamic DNS updater from home
How?
Walking through step-by-step how I did it:
1) Set up two Virtual Private Servers (VPSes)
You will need two stable machines with static IP addresses.
If you’re not lucky enough to have these in your possession, then you can set one up on the cloud. I used this site, but there are plenty out there. NB I asked them, and their IPs are static per VPS. I use the cheapest cloud VPS (1$/month) and set up debian on there.
NOTE: Replace any mention of DNSIP1 and DNSIP2 below with the first and second static IP addresses you are given.
Log on and set up root password
SSH to the servers and set up a strong root password.
2) Set up domains
You will need two domains: one for your dns servers, and one for the application running on your host.
I use dot.tk to get free throwaway domains. In this case, I might setup a myuniquedns.tk DNS domain and a myuniquesite.tk site domain.
Whatever you choose, replace your DNS domain when you see YOURDNSDOMAIN below. Similarly, replace your app domain when you see YOURSITEDOMAIN below.
3) Set up a ‘glue’ record
If you use dot.tk as above, then to allow you to manage the YOURDNSDOMAIN domain you will need to set up a ‘glue’ record.
What this does is tell the current domain authority (dot.tk) to defer to your nameservers (the two servers you’ve set up) for this specific domain. Otherwise it keeps referring back to the .tk domain for the IP.
On a Debian machine (for example), and as root, type:
apt install bind9
bind is the domain name server software you will be running.
5) Configure bind on the DNS Servers
Now, this is the hairy bit.
There are two parts this with two files involved: named.conf.local, and the db.YOURDNSDOMAIN file.
They are both in the /etc/bind folder. Navigate there and edit these files.
Part 1 – named.conf.local
This file lists the ‘zone’s (domains) served by your DNS servers.
It also defines whether this bind instance is the ‘master’ or the ‘slave’. I’ll assume ns1.YOURDNSDOMAIN is the ‘master’ and ns2.YOURDNSDOMAIN is the ‘slave.
Part 1a – the master
On the master/ns1.YOURNDSDOMAIN, the named.conf.local should be changed to look like this:
zone "YOURDNSDOMAIN" {
type master;
file "/etc/bind/db.YOURDNSDOMAIN";
allow-transfer { DNSIP2; };
};
zone "YOURSITEDOMAIN" {
type master;
file "/etc/bind/YOURDNSDOMAIN";
allow-transfer { DNSIP2; };
};
zone "14.127.75.in-addr.arpa" {
type master;
notify no;
file "/etc/bind/db.75";
allow-transfer { DNSIP2; };
};
logging {
channel query.log {
file "/var/log/query.log";
// Set the severity to dynamic to see all the debug messages.
severity debug 3;
};
category queries { query.log; };
};
The logging at the bottom is optional (I think). I added it a while ago, and I leave it in here for interest. I don’t know what the 14.127 zone stanza is about.
Part 1b – the slave
On the slave/ns2.YOURNDSDOMAIN, the named.conf.local should be changed to look like this:
zone "YOURDNSDOMAIN" {
type slave;
file "/var/cache/bind/db.YOURDNSDOMAIN";
masters { DNSIP1; };
};
zone "YOURSITEDOMAIN" {
type slave;
file "/var/cache/bind/db.YOURSITEDOMAIN";
masters { DNSIP1; };
};
zone "14.127.75.in-addr.arpa" {
type slave;
file "/var/cache/bind/db.75";
masters { DNSIP1; };
};
Part 2 – db.YOURDNSDOMAIN
Now we get to the meat – your DNS database is stored in this file.
On the master/ns1.YOURDNSDOMAINthe db.YOURDNSDOMAIN file looks like this:
$TTL 4800
@ IN SOA ns1.YOURDNSDOMAIN. YOUREMAIL.YOUREMAILDOMAIN. (
2018011615 ; Serial
604800 ; Refresh
86400 ; Retry
2419200 ; Expire
604800 ) ; Negative Cache TTL
;
@ IN NS ns1.YOURDNSDOMAIN.
@ IN NS ns2.YOURDNSDOMAIN.
ns1 IN A DNSIP1
ns2 IN A DNSIP2
YOURSITEDOMAIN. IN A YOURDYNAMICIP
On the slave/ns2.YOURDNSDOMAIN it’s very similar, but has ns1 in the SOA line, and the IN NS lines reversed. I can’t remember if this reversal is needed or not…:
$TTL 4800 @ IN SOA ns1.YOURDNSDOMAIN. YOUREMAIL.YOUREMAILDOMAIN. (
2018011615 ; Serial
604800 ; Refresh
86400 ; Retry
2419200 ; Expire
604800 ) ; Negative Cache TTL
;
@ IN NS ns1.YOURDNSDOMAIN.
@ IN NS ns2.YOURDNSDOMAIN.
ns1 IN A DNSIP1
ns2IN A DNSIP2
YOURSITEDOMAIN. IN A YOURDYNAMICIP
A few notes on the above:
The dots at the end of lines are not typos – this is how domains are written in bind files. So google.com is written google.com.
The YOUREMAIL.YOUREMAILDOMAIN. part must be replaced by your own email. For example, my email address: ian.miell@gmail.com becomes ianmiell.gmail.com.. Note also that the dot between first and last name is dropped. email ignores those anyway!
YOURDYNAMICIP is the IP address your domain should be pointed to (ie the IP address returned by the DNS server). It doesn’t matter what it is at this point, because….
the next step is to dynamically update the DNS server with your dynamic IP address whenever it changes.
6) Copy ssh keys
Before setting up your dynamic DNS you need to set up your ssh keys so that your home server can access the DNS servers.
NOTE: This is not security advice. Use at your own risk.
First, check whether you already have an ssh key generated:
ls ~/.ssh/id_rsa
If that returns a file, you’re all set up. Otherwise, type:
ssh-keygen
and accept the defaults.
Then, once you have a key set up, copy your ssh ID to the nameservers:
Now ssh to both servers and place this script in /root/update_ip.sh:
#!/bin/bash
set -o nounset
sed -i "s/^(.*) IN A (.*)$/1 IN A $1/" /etc/bind/db.YOURDNSDOMAIN
sed -i "s/.*Serial$/ $(date +%Y%m%d%H) ; Serial/" /etc/bind/db.YOURDNSDOMAIN
/etc/init.d/bind9 restart
Make it executable by running:
chmod +x /root/update_ip.sh
Going through it line by line:
set -o nounset
This line throws an error if the IP is not passed in as the argument to the script.
sed -i "s/^(.*) IN A (.*)$/1 IN A $1/" /etc/bind/db.YOURDNSDOMAIN
Replaces the IP address with the contents of the first argument to the script.
This diffs the contents of /tmp/ip.tmp with /tmp/ip (which is yet to be created, and holds the last-updated ip address). If there is an error (ie there is a new IP address to update on the DNS server), then the subshell is run. This overwrites the ip address, and then ssh’es onto the
The same process is then repeated for DNSIP2 using separate files (/tmp/ip.tmp2 and /tmp/ip2).
Why!?
You may be wondering why I do this in the age of cloud services and outsourcing. There’s a few reasons.
It’s Cheap
The cost of running this stays at the cost of the two nameservers (24$/year) no matter how many domains I manage and whatever I want to do with them.
Learning
I’ve learned a lot by doing this, probably far more than any course would have taught me.
More Control
I can do what I like with these domains: set up any number of subdomains, try my hand at secure mail techniques, experiment with obscure DNS records and so on.
My previous posttook off far more than I expected, so I thought I’d write another piece on less well-known bash features.
As I said before, because I felt bash is an often-used (and under-understood) technology, I ended up writing a book on it while studying it up. It’s really gratifying to know that other people think it’s important too, despite being un-hip.
A preview of the book is available here. It focusses more than these articles on ensuring you are drilled in and understand the concepts you need to take your bash usage to a higher level. This is written more for ‘fun’.
$ grp somestring somefile-bash: grp: command not found
Sigh. Hit ‘up’, ‘left’ until at the ‘p’ and type ‘e’ and return.
Or do this:
$ ^rp^rep^grep 'somestring' somefile
$
One subtlety you may want to note though is:
$ grp rp somefile
$ ^rp^rep^
$ grep rp somefile
If you wanted rep to be searched for, then you’ll need to dig into the man page and use a more powerful history command:
$ grp rp somefile
$ !!:gs/rp/rep
grep rep somefile
$
I won’t try and explain this one here…
2) pushd / popd
This one comes in very handy for scripts, especially when operating within a loop.
Let’s say you’re in a for loop moving in and out of folders like this:
for d1 in $(ls -d */)
do
# Store original working directory.
original_wd="$(pwd)"
cd "$d1"
for d2 in $(ls -d */)
do
pushd "$d2"
# Do something
popd
done
# Return to original working directory
cd "${original_wd}"
done
You can rewrite the above using the pushd stack like this:
for d1 in $(ls -d *)
do
pushd "$d1"
for d2 in $(ls -d */)
do
pushd "$d2"
# Do something
popd
done
popd
done
Which tracks the folders you’ve pushed and popped as you go.
Note that if there’s an error in a pushd you may lose track of the stack and popd too many time. You probably want to set -e in your script as well (see previous post)
There’s also cd -, but that doesn’t ‘stack’ – it just returns you to the previous folder:
cd ~
cd /tmp
cd blah
cd - # Back to /tmp
cd - # Back to 'blah'
cd - # Back to /tmp
cd - # Back to 'blah' ...
3) shopt vs set
This one bothered me for a while.
What’s the difference between set and shopt?
sets we saw before, but shopts look very similar. Just inputting shopt shows a bunch of options:
Essentially, it looks like it’s a consequence of bash (and other shells) being built on sh, and adding shopt as another way to set extra shell options.
But I’m still unsure… if you know the answer, let me know.
4) Here Docs and Here Strings
‘Here docs’ are files created inline in the shell.
The ‘trick’ is simple. Define a closing word, and the lines between that word and when it appears alone on a line become a file.
Type this:
$ cat > afile << SOMEENDSTRING
> here is a doc
> it has three lines
> SOMEENDSTRING alone on a line will save the doc
> SOMEENDSTRING
$ cat afile
here is a doc
it has three lines
SOMEENDSTRING alone on a line will save the doc
$
Notice that:
the string could be included in the file if it was not ‘alone’ on the line
the string SOMEENDSTRING is more normally END, but that is just convention
Lesser known is the ‘here string’:
$ cat > asd <<< 'This file has one line'
5) String Variable Manipulation
You may have written code like this before, where you use tools like sed to manipulate strings:
$ VAR='HEADERMy voice is my passwordFOOTER'
$ PASS="$(echo $VAR | sed 's/^HEADER(.*)FOOTER/1/')"
$ echo $PASS
But you may not be aware that this is possible natively in bash.
This means that you can dispense with lots of sed and awk shenanigans.
One way to rewrite the above is:
$ VAR='HEADERMy voice is my passwordFOOTER'
$ PASS="${VAR#HEADER}"
$ PASS="${PASS%FOOTER}"
$ echo $PASS
The # means ‘match and remove the following pattern from the start of the string’
The % means ‘match and remove the following pattern from the end of the string
Now run chmod +x default.sh and run the script with ./default.sh first second.
Observer how the third argument’s default has been assigned, but not the first two.
You can also assign directly with ${VAR:=defaultval} (equals sign, not dash) but note that this won’t work with positional variables in scripts or functions. Try changing the above script to see how it fails.
7) Traps
The trap builtin can be used to ‘catch’ when a signal is sent to your script.
functioncleanup() {
rm-rf"${BUILD_DIR}"
rm-f"${LOCK_FILE}"
# get rid of /tmp detritus, leaving anything accessed 2 days ago+
find"${BUILD_DIR_BASE}"/* -type d -atime+1|rm-rf
echo"cleanup done"}trap cleanup TERM INT QUIT
Any attempt to CTRL-C, CTRL- or terminate the program using the TERM signal will result in cleanup being called first.
Be aware:
Trap logic can get very tricky (eg handling signal race conditions)
The KILL signal can’t be trapped in this way
But mostly I’ve used this for ‘cleanups’ like the above, which serve their purpose.
Note that there are two ‘lines’ above, even though you used ; to separate the commands.
TMOUT
You can timeout reads, which can be really handy in some scripts
#!/bin/bash
TMOUT=5
echo You have 5 seconds to respond...
read
echo${REPLY:-noreply}
9) Extglobs
If you’re really knee-deep in bash, then you might want to power up your globbing. You can do this by setting the extglob shell option. Here’s the setup:
Now, potentially useful as it is, it’s hard to think of a situation where you’d absolutely want to do it this way. Normally you’d use a tool better suited to the task (like sed) or just drop bash and go to a ‘proper’ programming language like python.
10) Associative Arrays
Talking of moving to other languages, a rule of thumb I use is that if I need arrays then I drop bash to go to python (I even created a Docker container for a tool to help with this here).
What I didn’t know until I read up on it was that you can have associative arrays in bash.
Recently I wanted to deepen my understanding of bash by researching as much of it as possible. Because I felt bash is an often-used (and under-understood) technology, I ended up writing a book on it.
You don’t have to look hard on the internet to find plenty of useful one-liners in bash, or scripts. And there are guides to bash that seem somewhat intimidating through either their thoroughness or their focus on esoteric detail.
Here I’ve focussed on the things that either confused me or increased my power and productivity in bash significantly, and tried to communicate them (as in my book) in a way that emphasises getting the understanding right.
Enjoy!
1) `` vs $()
These two operators do the same thing. Compare these two lines:
$ echo `ls`
$ echo $(ls)
Why these two forms existed confused me for a long time.
If you don’t know, both forms substitute the output of the command contained within it into the command.
The principal difference is that nesting is simpler.
Which of these is easier to read (and write)?
$ echo `echo \`echo \\\`echo inside\\\`\``
or:
$ echo $(echo $(echo $(echo inside)))
If you’re interested in going deeper, see here or here.
2) globbing vs regexps
Another one that can confuse if never thought about or researched.
While globs and regexps can look similar, they are not the same.
Consider this command:
$ rename -n 's/(.*)/new$1/' *
The two asterisks are interpreted in different ways.
The first is ignored by the shell (because it is in quotes), and is interpreted as ‘0 or more characters’ by the rename application. So it’s interpreted as a regular expression.
The second is interpreted by the shell (because it is not in quotes), and gets replaced by a list of all the files in the current working folder. It is interpreted as a glob.
So by looking at man bash can you figure out why these two commands produce different output?
$ ls *
$ ls .*
The second looks even more like a regular expression. But it isn’t!
3) Exit Codes
Not everyone knows that every time you run a shell command in bash, an ‘exit code’ is returned to bash.
Generally, if a command ‘succeeds’ you get an error code of 0. If it doesn’t succeed, you get a non-zero code. 1 is a ‘general error’, and others can give you more information (eg which signal killed it, for example).
But these rules don’t always hold:
$ grep not_there /dev/null
$ echo $?
$? is a special bash variable that’s set to the exit code of each command after it runs.
Grep uses exit codes to indicate whether it matched or not. I have to look up every time which way round it goes: does finding a match or not return 0?
Grok this and a lot will click into place in what follows.
4) if statements, [ and [[
Here’s another ‘spot the difference’ similar to the backticks one above.
What will this output?
if grep not_there /dev/null
then
echo hi
else
echo lo
fi
grep’s return code makes code like this work more intuitively as a side effect of its use of exit codes.
Now what will this output?
a) hihi
b) lolo
c) something else
if [ $(grep not_there /dev/null) = '' ]
then
echo -n hi
else
echo -n lo
fi
if [[ $(grep not_there /dev/null) = '' ]]
then
echo -n hi
else
echo -n lo
fi
The difference between [ and [[ was another thing I never really understood. [ is the original form for tests, and then [[ was introduced, which is more flexible and intuitive. In the first if block above, the if statement barfs because the $(grep not_there /dev/null) is evaluated to nothing, resulting in this comparison:
[ = '' ]
which makes no sense. The double bracket form handles this for you.
This is why you occasionally see comparisons like this in bash scripts:
if [ x$(grep not_there /dev/null) = 'x' ]
so that if the command returns nothing it still runs. There’s no need for it, but that’s why it exists.
5) sets
Bash has configurable options which can be set on the fly. I use two of these all the time:
set -e
exits from a script if any command returned a non-zero exit code (see above).
This outputs the commands that get run as they run:
set -x
So a script might start like this:
#!/bin/bash
set -e
set -x
grep not_there /dev/null
echo $?
What would that script output?
6) <()
This is my favourite. It’s so under-used, perhaps because it can be initially baffling, but I use it all the time.
It’s similar to $() in that the output of the command inside is re-used.
In this case, though, the output is treated as a file. This file can be used as an argument to commands that take files as an argument.
Quoting’s a knotty subject in bash, as it is in many software contexts.
Firstly, variables in quotes:
A='123'echo"$A"
echo'$A'
Pretty simple – double quotes dereference variables, while single quotes go literal.
So what will this output?
mkdir -p tmp
cd tmp
touch a
echo "*"
echo '*'
Surprised? I was.
8) Top three shortcuts
There are plenty of shortcuts listed in man bash, and it’s not hard to find comprehensive lists. This list consists of the ones I use most often, in order of how often I use them.
Rather than trying to memorize them all, I recommend picking one, and trying to remember to use it until it becomes unconscious. Then take the next one. I’ll skip over the most obvious ones (eg !! – repeat last command, and ~ – your home directory).
!$
I use this dozens of times a day. It repeats the last argument of the last command. If you’re working on a file, and can’t be bothered to re-type it command after command it can save a lot of work:
grep somestring /long/path/to/some/file/or/other.txt
vi !$
!:1-$
This bit of magic takes this further. It takes all the arguments to the previous command and drops them in. So:
The ! means ‘look at the previous command’, the : is a separator, and the 1 means ‘take the first word’, the - means ‘until’ and the $ means ‘the last word’.
Note: you can achieve the same thing with !*. Knowing the above gives you the control to limit to a specific contiguous subset of arguments, eg with !:2-3.
:h
I use this one a lot too. If you put it after a filename, it will change that filename to remove everything up to the folder. Like this:
grep isthere /long/path/to/some/file/or/other.txt
cd !$:h
which can save a lot of work in the course of the day.
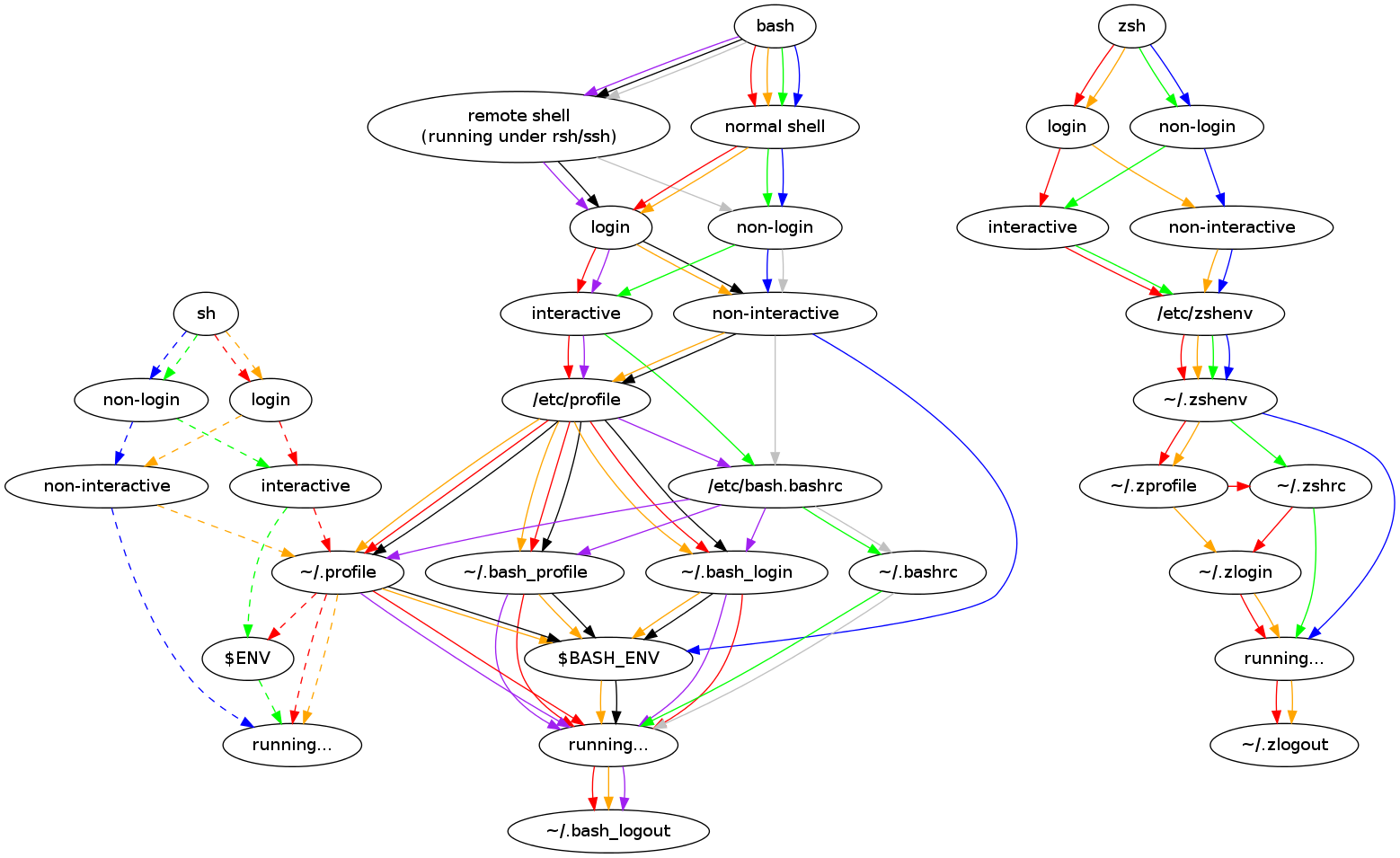
9) startup order
The order in which bash runs startup scripts can cause a lot of head-scratching. I keep this diagram handy (from this great page):
It shows which scripts bash decides to run from the top, based on decisions made about the context bash is running in (which decides the colour to follow).
So if you are in a local (non-remote), non-login, interactive shell (eg when you run bash itself from the command line), you are on the ‘green’ line, and these are the order of files read:
/etc/bash.bashrc
~/.bashrc
[bash runs, then terminates]
~/.bash_logout
This can save you a hell of a lot of time debugging.
10) getopts (cheapci)
If you go deep with bash, you might end up writing chunky utilities in it. If you do, then getting to grips with getopts can pay large dividends.
For fun, I once wrote a script called cheapci which I used to work like a Jenkins job.
The code here implements the reading of the two required, and 14 non-required arguments. Better to learn this than to build up a bunch of bespoke code that can get very messy pretty quickly as your utility grows.
If you enjoyed this, then please consider buying me a coffee to encourage me to do more.
Recently I’ve had to take on some project management tasks, managing engineering for a relatively large-scale project in a large enterprise covering a wide variety of use cases and demands.
One of the biggest challenges was how to express the dependencies that needed to be overcome to get the business outcomes the stakeholders wanted. Cries of ‘we just want x’ were answered by me with varying degrees of quality repeatedly, and generally left the stakeholders unsatisfied.
Being a software engineer – and not a project manager – by background or training, I naturally used graphviz instead to create dependency diagrams, and git to manage them.
The examples here are in source here and I welcome PRs and are based on the ‘project’ of preparing for a holiday.
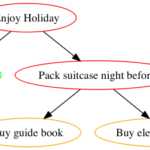
Simple
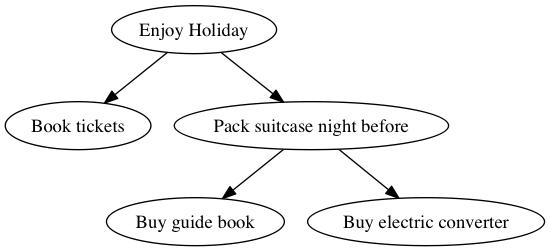
We start with a simple graph with a couple of dependencies:
digraph G {
"Enjoy Holiday" -> "Book tickets"
"Enjoy Holiday" -> "Pack suitcase night before"
"Pack suitcase night before" -> "Buy guide book"
"Pack suitcase night before" -> "Buy electric converter"
}
The emboldening is mine for illustration; the file is plain text.
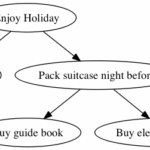
This file can be saved as simple.gv (.gv is for ‘graphviz’) and will generate this graph as a .png if you run dot -Tpng simple.gv > simple.png:
Looking closer at simple.gv:
digraph – Tells graphviz that this is a directed graph, ie the relationships have a direction, indicated by the -> arrows. The arrow can be read as ‘depends on’.
Enjoy Holiday is the name of a node. Whenever this node is referenced in future it is the ‘same’ node. In the case of Pack suitcase the night before you can see that two nodes depend on it, and it depends on one. These relationships are expressed through the arrows in the file.
The dot program is part of the graphviz package. Other commands include neato, circo and others. Check man dot to read more about them.
This shows how easy it is to create a simple graph from a text file easily stored in git.
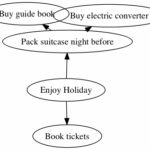
Layouts
That top-down layout can be a bit restrictive to some eyes. If so, you can change the layout by using another command in the graphviz package. For example, running neato -Tpng simple.gv > simple.png produces this graph:
Note how:
Enjoy holiday is now nearer the ‘centre’ of the graph
The nodes are overlapping (we’ll deal with this later)
The arrows have shortened (we’ll deal with this later too)
If you’re fussy about your diagrams you can spend a lot of time fiddling with them like this, so it’s useful to get a feel for what the different commands do.
Two things have changed here. Referring to the full description of the node can get tiresome, so ‘Enjoy holiday’ has been referenced with ‘EH’, and associated with a ‘label’, and ‘color’.
Similarly, you can change the attributes of nodes in the graph, and their relationships in code.
I find that with a complex graph with some text in each node, a rectangular node makes for better layouts. Also, I like to specify the distance between nodes, and prevent them from overlapping (two ‘problems’ we saw before).
By adding the ranksep and nodesep attributes, we can influence the layout of the graph by specifying the distance between nodes in their rank in the hierarchy, and separation between them. Similarly, overlap prevents the problem we saw earlier with overlapping nodes.
The node line specifies the characteristics of the nodes – in this case rectangular and black by default.
Running the same dot command as above results in this graph:
which is arguably uglier than previous ones, but these changes help us as the graphs become more complex.
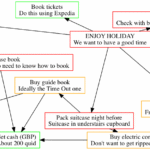
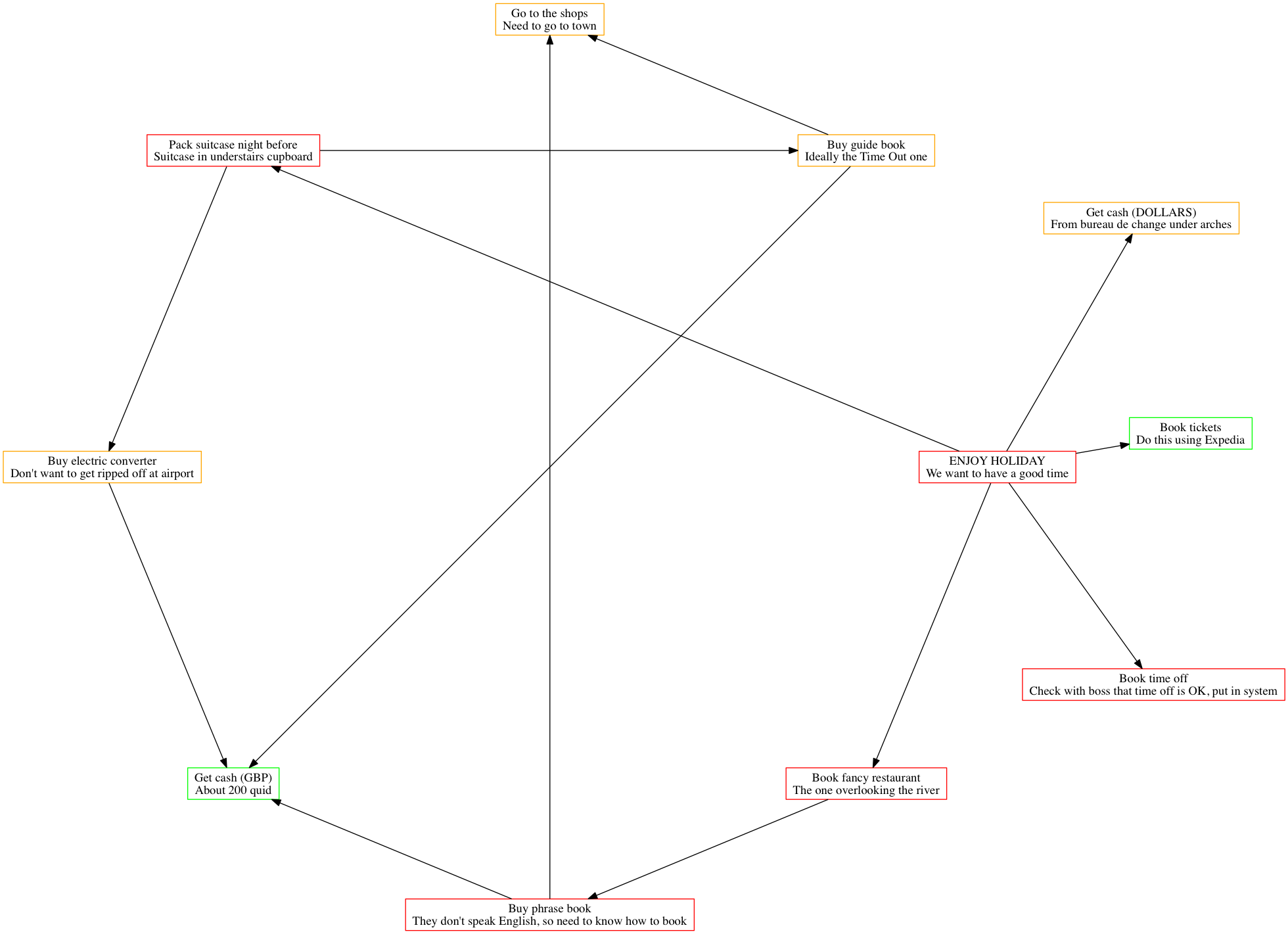
More Complex Graphs
Compiling this more complex graph with dot:
digraph G {
ranksep=2.0
nodesep=2.0
overlap="false"
node [color="black", shape="rectangle"]
"EH" [label="ENJOY HOLIDAY\nWe want to have a good time",color="red"]
"BTOW" [label="Book time off\nCheck with boss that time off is OK, put in system",color="red"]
"BFR" [label="Book fancy restaurant\nThe one overlooking the river",color="red"]
"BPB" [label="Buy phrase book\nThey don't speak English, so need to know how to book",color="red"]
"BT" [label="Book tickets\nDo this using Expedia",color="green"]
"PSNB" [label="Pack suitcase night before\nSuitcase in understairs cupboard",color="red"]
"BGB" [label="Buy guide book\nIdeally the Time Out one",color="orange"]
"BEC" [label="Buy electric converter\nDon't want to get ripped off at airport",color="orange"]
"GTS" [label="Go to the shops\nNeed to go to town",color="orange"]
"GCG" [label="Get cash (GBP)\nAbout 200 quid",color="green"]
"GCD" [label="Get cash (DOLLARS)\nFrom bureau de change under arches",color="orange"]
"EH" -> "BT"
"EH" -> "BFR"
"EH" -> "BTOW"
"BFR" -> "BPB"
"BPB" -> "GTS"
"BPB" -> "GCG"
"EH" -> "PSNB"
"EH" -> "GCD"
"PSNB" -> "BGB"
"BGB" -> "GTS"
"PSNB" -> "BEC"
"BGB" -> "GCG"
"BEC" -> "GCG"
}
gives this graph:
And with neato:
You can see the graphs look quite different depending on which layout engine/binary you use. Some may suit your purpose better than others.
Project Planning with PRs
Now that you have a feel for graphing as code, you can check these into git and share them with your team. In our team, each node represents a JIRA ticket, and shows its ID and summary.
A big benefit of this is that project updates can be asynchronous. Like many people, I work with engineers across the world, and their ability to communicate updates by this method reduces communication friction considerably.
For example, the other day we had a graph representing our next phase of work that was looking too heavy for one sprint. Rather than calling a meeting and go over each line item, I just asked him to update the graph file and raise a PR for me to review.
We then workshopped the changes over the PR, and only discussed a couple of points over the phone. Fewer meetings, and more content-rich discussions.
Surface Assumptions
Beyond fewer and more effective meetings, another benefit is the objective recording of assumptions within the team. Surprisingly often, I have discovered hidden dependencies through this method that had either not been fully understood or discussed.
It’s also surfaced further items of work required to reach the solution, which has resulted in more and more clear tickets being raised that relate to the target solution. The discipline of coding these up helps force these into the open.
Happier Stakeholders
While inside the team, the understanding of what needs to happen is clearer, stakeholders clamouring for updates are clearer on what’s blocking the outcomes they want.
Another benefit is an increased confidence in the process. There’s a document that’s readily comprehensible they can dig into if they want to find out more. But the fact that there’s a transparent graph of dependencies usually suffices to persuade people that things are under control.
Alternate Views
Finally, here are some alternate views of the same graph. We’ve already seen dot and neato. Here are the others. I’m not going to explain them technically as I’ve read the man page definitions and am none the wiser. They use words like ‘outerplanar’ and ‘force-directed’. Graph rendering is a complicated affair.
I see a lot of posts like this or this or this on HackerNews asking about time management
I was disorganised until my 30s.
Then I got organised and changed my life with:
JIRA
Notes in Git
Automating environment setup
What I’ve ‘got done’ since is listed below.
The Phone Call
About 6 years ago I missed something important at work. While working in ops, a customer had asked me to do something while I was busy, I’d moved onto another fire and clean forgot to do it.
Monday I got a phone call from her: “Ian, the payments went through over the weekend. Did you remember to switch off the cron job?”
Fuck.
She had to go and sort it out. I could only give my apologies to help her with the grief she was going to get.
I had the excuse that I was busy, that I’d been distracted, that I’ve got two kids and lots on.
But deep down I know something was wrong, that it was my fault. That I’d made a contract with someone and not honoured it.
It hurt.
A Chance
A few weeks later I was on a rare day off, and happened to be in a bookshop, and in this bookshop I saw Getting Things Done. I guess my unconscious led me to it, and though I’d always mocked books like this, I picked it up and scanned it. To my surprise, the advice was flexible, human, and practicable. I inhaled it, and my life changed from there.
What Happened?
It’s fair to say a lot in my life changed since that phone call 6 years ago. Since then, I’ve:
Also (and no less importantly), I’ve still got a job, and am a happily married father of two (I overlook the fact that my wife refuses to use JIRA).
I also generally feel less stressed, and more productive. I don’t know if all of it can be attributed to getting organised, but it certainly feels that way. Here’s what I did.
What I Did – JIRA
The first thing I did was set up a home JIRA instance. I’m a dinosaur, a control freak, and a cheapskate, so I buy the license and run it from home.
It doesn’t matter that it’s JIRA, the point is that all the things that impinge on my consciousness get put in here, and get out of my mind, giving me a clear head.
When the board gets too full, I start ditching things. Most of these are articles I intended to read, or little ideas my ardour has cooled on. That stops me getting overwhelmed.
Over time, I made a few tweaks that helped me be a little more efficient:
I created my own workflow that matched the way I thought about tasks:
Open/New
To-Do
Waiting for Something
Reminder Set
Closed
I set up a gmail account and linked it to JIRA so I could create tickets
I use mail this link to send links I’m interested in to my JIRA
I use send to kindle to mail articles directly to my kindle, so I can batch-read them asynchronously
There’s no separation between work and home tasks. Tax returns and birthday reminders sit right next to work tasks I want to stay on top of.
If it takes up space in your head, it goes in one place.
What I Did – Notes
That’s what I did for tasks – I had another frustration that I wanted to address. I would work on something, then either:
forget it
make notes and forget where they were
make notes, remember where they were, but couldn’t find them
I did something really simple to solve this: I created a git repo for all my notes.
imiell@Ians-Air-2:/space/git/work/notes ⑂ master + ls | head
R
X
actiona
aircrack-ng
algorithms
alpacajs
angularjs
ansible
ant
anyorigin
[...]
Then, I wrote some helper scripts. For example, mk_notes.sh creates a folder in this repo with some file pre-created:
#!/bin/bash
if [[ $1 = '' ]]
then
echo folder name needed
exit 1
fi
BASE=/space/git/work
NOTES=${BASE}/notes
LEARNING=${BASE}/learning
mkdir -p ${NOTES}/$1
mkdir -p ${LEARNING}/$1
touch ${NOTES}/$1/cheat_sheet.asciidoc
touch ${NOTES}/$1/links
touch ${NOTES}/$1/git_repos
touch ${NOTES}/$1/$1.asciidoc
touch ${LEARNING}/$1/$1.asciidoc
git add ${NOTES}/$1
git add ${LEARNING}/$1
This creates a folder and adds it to git with a file for related links, a cheat_sheet, any related git_repos and a file that has the subject name in it.
Now if I pick up a new skill and then pick up my learning later, I can track my notes up to where I left off. I’ve used these notes to compiled blog postslikethese.
I create asciidocs because I like the format, and it works well with vim.
I did try other methods (google docs, email, JIRA tickets), but this works best for me because:
It is available offline (git being a distributed note-taking tool)
It is text only
The current content is easily searched (grep)
A history is maintained that I can also search if needed
I can control/extend this system the way that makes sense to me
These things are important to me. They might be more or less important to you, so choose a tool accordingly. The vital thing is that it’s all in one place.
Another constant niggle was setting up work environments. Like many people, I work on Linux servers, Mac laptops, and occasionally a Windows machine.
Mostly I dial into my home servers, but not infrequently I have to work on other servers.
To save time I wrote a ShutitFile to set up a server the way I like it. Here’s an abbreviated version of the full version:
# We assert here that we are running as root
SEND whoami
ASSERT_OUTPUT root
SEND lsb_release -d -s | awk '{print $1}'
ASSERT_OUTPUT Ubuntu
# We assert here the user imiell was set up by the OS installation process
SEND cut -d: -f1 /etc/passwd | grep imiell | wc -l
ASSERT_OUTPUT 1
# Install required packages
INSTALL openssh-server
INSTALL run-one
[...]
# Install docker
IF_NOT RUN docker version
INSTALL apt-transport-https
INSTALL ca-certificates
INSTALL curl
INSTALL software-properties-common
RUN curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
RUN add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable"
RUN apt-get update
RUN apt install -y docker-ce
ENDIF
# Add imiell to the docker user group
RUN usermod -G docker -a imiell
# Create space folder and chown it to imiell
RUN mkdir -p /space && chown imiell: /space
RUN mkdir -p /space/git
# Generate an ssh key
IF_NOT FILE_EXISTS /home/imiell/.ssh/id_rsa.pub
RUN ssh-keygen
# Note that the response to 'already exists' below prevents overwrite here.
EXPECT_MULTI ['file in which=','empty for no passphrase=','Enter same passphrase again=','already exists=n']
ENDIF
# Log me in as imiell
USER imiell
# If it's not been done before, check out my dotfiles and set it up
IF_NOT FILE_EXISTS /home/imiell/.dotfiles
RUN cd /home/imiell
RUN git clone --depth=1 https://github.com/ianmiell/dotfiles ~imiell/.dotfiles
RUN cd .dotfiles
RUN ./script/bootstrap
EXPECT_MULTI ['What is your github author name=Ian Miell','What is your github author email=ian.miell@gmail.com','verwrite=O']
ENDIF
LOGOUT
ShutIt is a tool I wrote for simple automation of interactive sessions. Like traditional CM tools, but simpler.
Exceptions/Difficulties/Lessons Learned
This method works, for me, but there are limitations. I can’t keep all my work Confluence notes and JIRAs on my home JIRA or Git repo (not least for security reasons), so there is some separation between work and home notes and information.
That can’t be helped, but what’s more interesting are the downsides of this approach.
Is It Productive?
Sometimes it feels like managing this is a tax on my attention. I do wonder whether sometimes I’m just shuffling tickets around rather than tackling the hard stuff that happens over much longer time periods than individual tasks.
I Have to Remember to Let Go
Managing your workload more formally like this can make it hard to let go. There’s always something to do, but sometimes you need to take time out and smell the flowers. That’s when other good things can happen. Being productive is not everything, by a long chalk.
Or, as Lennon didn’t put it: Life is what happens when you are busy grooming your backlog.
Any Suggestions?
I’m always open to improving my workflow, so please let me know below if you have any suggestions.
This sounds obvious, but is important to call out.
Chef’s structure can be bewildering to newcomers. There are so many concepts that may be new to you to get to grips with all at once. Server, chef-client, knife, chefdk, recipe, role, environment, run list, node, cookbook… the list goes on and on.
I don’t have great advice here, but I would avoid doing too many theoretical tutorials, and just focus on getting an environment that you can experiment on to embed the concepts in your mind. I automated an environment in Vagrant for this purpose for myself here. Maybe you’ve got a test env at work you can use. Either way, unless you’re particularly gifted you’re not going to get conversant with these things overnight.
Then keep the chef docs close to hand, and occasionally browse them to pick up things you might need to know about.
2) A Powerful Debugger in Two Lines
This is less well known than it should be, and has saved me a ton of time. Adding these two lines to your recipes will give you a breakpoint when you run chef-client.
require 'pry'
binding.pry
You’re presented with a ruby shell you can interact with mid-run. Here’s a typical session:
root@chefnode1:~# chef-client
Starting Chef Client, version 12.16.42
resolving cookbooks for run list: ["chef-repo"]
Synchronizing Cookbooks:
- chef-repo (0.1.0)
Installing Cookbook Gems:
Compiling Cookbooks...
Frame number: 0/22
From: /opt/chef/embedded/lib/ruby/gems/2.3.0/gems/chef-12.16.42/lib/chef/cookbook_version.rb @ line 234 Chef::CookbookVersion#load_recipe:
220: def load_recipe(recipe_name, run_context)
221: unless recipe_filenames_by_name.has_key?(recipe_name)
222: raise Chef::Exceptions::RecipeNotFound, "could not find recipe #{recipe_name} for cookbook #{name}"
223: end
224:
225: Chef::Log.debug("Found recipe #{recipe_name} in cookbook #{name}")
226: recipe = Chef::Recipe.new(name, recipe_name, run_context)
227: recipe_filename = recipe_filenames_by_name[recipe_name]
228:
229: unless recipe_filename
230: raise Chef::Exceptions::RecipeNotFound, "could not find #{recipe_name} files for cookbook #{name}"
231: end
232:
233: recipe.from_file(recipe_filename)
=> 234: recipe
235: end
[1] pry(#<Chef::CookbookVersion>)>
The last line above is a prompt from which you can inspect the local state, similar to other breakpoint debuggers.
I spent a long time being frustrated by my inability to re-run chef-client with a slightly modified set of cookbooks in the local cache (in /var/chef/cache...).
Then the chef client we were using was upgraded, and the --skip-cookbook-sync option was available. This did exactly what I wanted: use the cache, but run the recipes in exactly the same way, run list and all.
The -z flag can do similar, but you need to specify the run-list by hand. --skip-cookbook-sync ‘just works’ if you want to keep everything exactly the same and add a log line or something.
It isn’t immediately obvious how you avoid re-using the same code recipe after recipe.
Here’s a sample of a ‘ruby library’ embedded in a Chef recipe. It handles the figuring out of the roles of the nodes.
One thing to note is that because you are outside the Chef recipe, to access the standard Chef functions, you need to explicitly refer to its namespace. For example, this line calls the standard search:
Similarly, you can introspect the client’s node using its attributes and standard Ruby functions.
For example, to introspect a node’s run list to determine whether it has the webserver role assigned to it, you can run:
node.run_list.roles.include?("webserver")
This technique is also used in the example code mentioned above.
8) Attribute precedence and force_override
Attribute precedence becomes important pretty quickly.
Quite often I have had to refer to this section of the docs to remind myself of the order that attributes are set.
Also, force_override is something you should never have to use as it’s a filthy hack, but occasionally it can get you out of a spot. But it can’t override everything (see 10 below)!
9) Chef’s Two-Pass model
This can be the cause of great confusion. If the order of events in Chef seems counter-intuitive in a run, it’s likely that you’ve not understood the way Chef processes its code.
The best explanation of this I’ve found is here. For me, this is the key sentence:
This also means that any Ruby code in the file not explicitly delayed (ruby_block, lazy, not_if/only_if) is run when the file is run, during the compile phase.
Don’t feel you need to understand this from day one, just keep it in mind when you’re scratching your head about why things are happening in the wrong order, and come back to that page.
10) Ohai and IP Addresses
This one caused me quite a lot of grief. I needed to override the IP address that ohai (the tool that gathers information about each Chef node and places in the node object) gets from the node.
It takes the default route’s interface’s IP address by default, but this caused me lots of grief when using Vagrant. force_override (see 8) above) doesn’t work because it’s an automatic ohai variable.
I am nottheonlyonewith this problem, but I never found a ‘correct’ solution.
In the end I used this hack.
Find the ruby file that sets the ip and mac address. Depending on the version this may differ for you: