This post is aimed at those interested in continuous compliance, an extension of cloud native principles to the area of software compliance, an under-developed field of software automation.
My consultancy, Container Solutions is working on an open source project to help automate the management and reporting of controls, and this post arose from that work.
OSCAL?
OSCAL stands for “Open Security Controls Assessment Language”.
It’s a standard maintained by NIST. Like many standards, it’s big and full of jargon, difficult for outsiders to grok, and obviously designed by committee, but trying to encompass an area like this across a whole set of industries is hard, and there’s no other game in town.
The OSCAL ‘Schema’
OSCAL was created to be a flexible but complete standard for exchanging information about security controls.
It’s designed to define machine-readable documents that represent different parts of the controls lifecycle, such as assessments, risk identification, and ‘plans of action’. The idea is that participants and software within this lifecycle can exchange information using a common, machine-readable language.
For example, a regulator might publish “Control Catalogs” using OSCAL as a document format. These publications can then be read by software used by various parties involved in compliance to facilitate their work.
To give you an idea, here’s an example, minimal and edited OSCAL document, from the examples repo. It represents an Assessment Plan, one of the phases in the control lifecycle:
You can imagine how that document could be read by a desktop application which presents this information in a way that can be used by someone about to perform an assessment of controls. Note that the ‘uuids’ can be referenced by other documents’ entities, and that there are uuids that could refer to other documents’ entities. This will be relevant later.
Other entities modelled by OSCAL include:
Catalogs (lists of controls and their details)
Profiles (sets of controls derived from catalogs)
Implementations (details of how control is applied)
Assessment Plans (how the controls will be tested)
Assessment Results (findings from the assessment process)
Plan of Action and Milestone (corrective actions for addressing findings)
and here is a visual representation from the OSCAL site:
The Problem
For someone old like me who is used to a more monolithic and relation-oriented schema, OSCAL feels odd. Different documents at different levels may or may not have elements that relate to one another, and might be completely independent. For example, a control definition that exists in one doc might be referenced in another by a UUID being the same, but there’s no definition of whether such a relation needs to exist or not.
However, both in practice and in the examples given by NIST, the data ‘feels’ relational
Visualising OSCAL with Neo4J
While working on this, a colleague mentioned this talk from Alexander Koderman, (slides) where he demonstrated how to use Neo4J to visualise OSCAL documents. Along the way he discovered errors in the documents and could relate, isolate, and more easily visualise parts of the documents he was looking at:
Building on this work, I set up a repo to run up a Neo4J instance in docker, after which I could play with the nodes in an interactive way. This made learning about OSCAL and the relations between the nodes a lot more fun.
An OSCAL example System Security Plan (highlighted) and its related nodes. Where possible, size and colour have been used to distinguish different types of node. The type of node can be inferred from the relation described between them in the arrows, but if you click on them, the details can be reviewed.
Catalog
An OSCAL example catalog (highlighted) and its related nodes.
Assessment Plan and Plan of Action and Milestones
This graph shows how the Plan of Action and Milestones (highlighted, large brown node) is related to the Assessment Plan (the large orange node). Tracing through, you can see that ‘Assessment Plan’ nodes are related to ‘Assessment Result’ nodes via ‘Party’ nodes and ‘Role’ nodes.
Code
The code for running this on your own machine on Docker, along with the above images, is available here. Simply clone it and run make full-rebuild and you will see instructions on how to get the same views on the OSCAL examples.
If you don’t already know, Crossplane is billed as an:
Open source, CNCF project built on the foundation of Kubernetes to orchestrate anything. Encapsulate policies, permissions, and other guardrails behind a custom API line to enable your customers to self-service without needing to become an infrastructure expert.
Another way to view Crossplane is as a tool that uses a commodity, open source, and well-supported control plane (Kubernetes) to support the creation of other control planes.
We’ve been using it at Container Solutions for a while, and have recently been talking about how we think it’s going to become more important in future:
Just as IBM buys Terraform, Crossplane seems to be becoming a default for our client engagements.
Recently I’ve been watching Viktor Farcic’s fantastic set of tutorial videos on Crossplane. If you are an engineer or interested architect, then these primers are ideal for finding out what’s going on in this area.
While following Viktor’s work I saw another Crossplane-related video by Viktor on a subject we both seem to get asked about a lot: does Crossplane replace Terraform/Ansible/Chef/$Tool?
This is a difficult question to answer briefly (aside from just saying “yes and no”), because understanding the answer requires you to grasp what is new and different about Crossplane, and what is not. It doesn’t help that – from the user point of view – they can seem to do the exact same thing.
To get to the answer, I want to reframe a few things Viktor says in that video that confused me, in the hope that the two pieces of content taken together help people understand where Crossplane fits into the Cloud Native firmament. Although Viktor and I agree on the role Crossplane plays now and in the future, we do differ a little on defining and interpreting what is new about Crossplane, and how the industry got here.
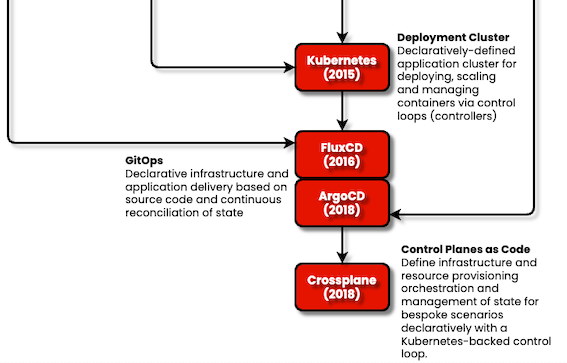
This post follows the logic of our ‘Cloud Native Family Tree’, which seeks to explain the history of devops tooling. It’s recently been updated to include Crossplane.
Three Questions
Before we get into the debate, we may want to ask ourselves two deceptively simple questions:
What is an API?
What is a cloud service?
And one non-simple question:
What is a control plane?
Understanding exactly what the answers to these are is key to defining what’s new and useful about Crossplane.
If you think you know these already, or aren’t interested in the philosophy, skip to the end.
APIs are mechanisms that enable two software components to communicate with each other using a set of definitions and protocols.
Nowadays, most people think of an API as a set of services you can call using technologies like HTTP and JSON. But HTTP and JSON (or YAML, or XML etc) are not necessary. In this context, I like to explain to people that the venerable mkdir command is an API. mkdir conforms in these ways:
enables two software components to communicate with each other [the shell and the Linux API] using
a set of definitions [the standard flags to mkdir] and
protocols [shell standard input/output and exit codes]
Pretty much all code is something that calls an API, down to whatever goes on within the hardware (which, by definition, isn’t a software component). Technically speaking, code is “APIs all the way down”. But this isn’t a very helpful definition if it essentially describes all code.
APIs all the way down: The Linux API calls that mkdir makes in order to create a folder.
It might be argued that mkdir is not an API because it is used by humans, and not for ‘two software components to communicate’. However, you can telnet to a server and call its API by hand (I used to do this via HTTP a lot when debugging). Further, mkdir can (and is also designed to) be used within scripts
APIs are Stable
What people really want and expect from an API is stability. As a rule, the lower down the stack an API is, the more stable it needs to be. The Intel x86 API has had very few breaking changes since it came into being in 1978, and even carries over idiosyncrasies from the Datapoint 2022 terminal in 1970 (such as the 8086’s ‘little endian’ design. Similarly, the Linux Kernel API has also had very few changes (mostly removals) since version 2.6‘s release over 20 years ago (2003).
The Linux CLI, by contrast, is much less stable. This is one of the main reasons shell scripts get such a bad rep. They are notoriously difficult to write in such a way that they can be run on a wide variety of different machines. Who knows if the ifconfig command in my shell script will run in your target shell environment? Even if it’s installed and on the $PATH, and not some other command with the same name, will it have the same flags available? Will those flags do the same thing consistently? Defensively writing code against these challenges are probably the main reason people avoid writing shell scripts, alongside the ease with which you can write frighteningly broken code.
This is why tools like Ansible came into being. They abstracted away the messiness of different implementations of configuration commands, and introduced the notion of idempotence to configuration management. Rather than running a mkdir command which might succeed or fail, in Ansible you simply declare that the folder exists. This code will create a folder on ‘all’ your defined hosts.
- hosts: all tasks: - name: Create a folder file: path: /path/to/your/folder state: directory
Ansible will ssh into them and create the folder if it doesn’t already exist, running mkdir, or whatever it needs to run to get the Linux API to deliver an equivalent result.
Viktor says that Ansible, Chef et al focussed on ‘anything but APIs’, and this is where I disagree. They did focus on APIs, but not http-based (or ‘modern’) APIs; they simplified the various command line APIs into a form that was idempotent and (mostly) declarative. Just as mkdir creates a new API in front of the Linux API, Ansible created a means to use (or create your own) APIs that simplified the complexity of other APIs.
Terraform: An Open Plugin and Cloud First Model
Terraform not only simplified the complexity of other APIs, but then added a rich and open plugin framework and a ‘cloud first’ model (as opposed to Ansible’s ‘ssh environment first’ model). In theory, there was no reason that Ansible couldn’t have done the same things Terraform did, but Ansible wasn’t designed for infrastructure provisioning the way Terraform was (as Viktor points out).
This begs the second question: if Terraform was ‘cloud first’…
What is a Cloud Service?
Many people think of a cloud service as something sold by one of the big three hyperscalers. In fact, a cloud service is the combination of three things:
A remote network connection
An API
A delegation of responsibility to a third party
That’s it. That’s all a cloud service is.
We’ve already established that an API (as opposed to just ‘running software’) is a stable way for two software components to communicate. Cloud simply takes this and places it on the network. Finally – and crucially – it devolves responsibility for delivering the result to a third party.
So, if I ask my Linux desktop (y’know, the one literally on my desk) for more memory, and it can’t give it to me because it’s run out, then that’s my responsibility to resolve, therefore it’s not a cloud service.
A colo is not a cloud service, for example, because the interface is not an API over a network. If I want a new server I’ll send them an email. If they add an API they become a cloud service.
This table may help clarify:
Remote Network Connection
API
Delegation of Responsibility
Abacus
No
No
No
Linux Server
Yes
No
No
mkdir CLI Command on Desktop Linux
No
Yes
No
Outsourced On-Prem Server
No
No
Yes
Self-managed API service
Yes
Yes
No
Windows Operating System on Desktop
No
Yes
Yes
Colo Server
Yes
No
Yes
AWS EKS
Yes
Yes
Yes
GitHub
Yes
Yes
Yes
An abacus is a simple calculation tool that doesn’t use a network connection, has an interface (moving beads), but not an API, and if the abacus breaks, that’s your problem.
A Linux server has a remote network connection, but no API for management. (SSH and the CLI might be considered an API, but it’s certainly not stable).
mkdir has an API (see above), but from mkdir‘s point of view, disk space is your problem.
If you engage a company to supply you with an on-prem server, then it’s their problem if it breaks down (probably), but you don’t generally have an API to the outsourcer.
If you build your own API and manage it yourself then you can’t pick up the phone to get it fixed if it returns an error.
If the Windows API breaks (and you paid for support), then you can call on Microsoft support, but the Windows API doesn’t need a network connection to invoke.
A colo server is supplied by you without an API, but if it doesn’t get power/bandwidth/whatever else the colo supports, you can get them to fix it, and can connect to it over the network.
Some of these may be arguable on detail, but it’s certainly true that only EKS and GitHub qualify as ‘cloud services’ in the above table, as they fulfil all three criteria for a cloud service.
What is a Control Plane?
A less commonly-understood concept that must also be understood is the ‘control plane’. The phrase comes from network routing, which divides the router architecture into three ‘planes’: the ‘data plane’, the ‘control plane’, and the ‘management plane’.
In networking, the data plane is the part of the software that processes the data requests. By contrast, the control plane is the part of the software that maintains the routing table and defines what to do with incoming packets, and the management plane handles monitoring and configuration of the network stack.
You might think of the control plane as the state management of the data that goes through the router, as opposed to the general management and configuration of the system (management plane).
This concept has been co-opted by other technologies, but I haven’t been able to find a formal definition of what a control plane when used outside of networking. I think of it as ‘whatever manages how the useful work will be done by the thing’ rather than the thing that does the actual work. If that doesn’t seem like a rigorous definition to you, then I won’t disagree.
For Kubernetes, the control plane is the etcd database and the core controllers that make sure your workloads are appropriately placed and running.
All cloud services need a control plane. They need something that orchestrates the delivery of services to clients. This is because they have a remote API and a delegation of responsibility.
So Does Crossplane Replace Terraform?
OK, now we know what the following things are:
APIs
Cloud services
Control planes
We can more clearly explain how Crossplane and Terraform (et al) relate.
Resources, APIs, Cloud Services
Crossplane and Terraform both deal with the creation of resources, and are both designed to help manage cloud services. In this sense, Crossplane can replace Terraform. However…
‘One-shot’ vs Continuous
…whereas Terraform is ‘one-shot‘ (you run it once and then it’s done), Crossplane is continuous. Part of its job is to provision resources, but it’s not its only job. Its design, and main purpose, is to give you a framework to ensure that resources remain in a ‘known state’, ultimately deriving its source of truth from the configuration of its own Kubernetes control plane (or Git, if this configuration is synchronised with a Git repository).
Terraform ‘Under’ Crossplane?
If you want, you can run your Terraform code in Crossplane with the Terraform provider. One thing to note here, thought, is that you can’t just take your existing Terraform code or other shell scripts and run it unchanged ‘within’ Crossplane’s control plane just as you would have done before. Some work will need to be done to integrate the code to run under Crossplane’s control. In this sense, Crossplane does replace Terraform, subsuming the code into its own provider.
Control Planes
In a way, Crossplane is quite close to Chef and Puppet. Both those tools had ‘control planes’ (the Chef and Puppet servers) that ensured the targets were in a conformant state. However, Chef and Puppet (along with Ansible) were designed to configure individual compute environments (physical servers, VMs etc), and not orchestrate and compose different APIs and resources into another cloud service-like API.
When I started my career as an engineer in the early noughties, I was very keen on developer experience (devex).
So when I joined a company whose chosen language was TCL (no, really), I decided to ask the engineering mailing list what IDEs they used. Surely the senior engineers, with all their wisdom and experience, would tell which of the many IDEs available at the time made them the most productive? This was decades before ‘developer experience’ had a name, but nonetheless it was exactly what I was talking about, and what people fretted about.
Minutes later, I received a terse one-word missive from the CTO:
From: CTO
Subject: IDEs
> Which IDEs do people recommend using here? Thanks,
> Ian
vim
Being young and full of precocious wisdom, I ignored this advice for a while. I installed Eclipse (which took up more RAM than my machine had, and quickly crashed it), and settled on Kate (do people still use Kate?). But eventually I twigged that I was no more productive than those around me that used vim.
So, dear reader, I married vim. That marriage is still going strong twenty years later, and our love is deeper than ever.
This pattern has been repeated multiple times with various tools:
see the fancy new GUI
try it
gradually realise that the command-line, text-only, steep-learning-curve, low-tech approach is the most productive
Some time ago it got to the point where when someone shows me the GUI, I ask where the command-line version is, as I’d rather use that. I often get funny looks at both this, and when I say I’d rather not use Visual Studio if possible.
I also find looking at gvim makes me feel a bit queasy, like seeing your dad dancing at a wedding.
This is not a vim vs not-vim post. Vim is just one of the oldest and most enduring examples of an approach which I’ve found has served me better as I’ve got older.
I call this approach ‘low-tech devex’, or ‘LTD’. It prefers:
Long-standing, battle-hardened tools that have stood the test of time
Tools with stable histories
Small tools with relatively few dependencies
Text-based input and output
Command-line approaches that exemplify unix principles
Tools that don’t require daemons/engines to run
LTD also is an abbreviation of ‘limited’, which seems appropriate…
Anyone else out there love tools for 'low tech devex'?
I have grown to love shell, make, vim, docker over the years and ignore all the gui-based fashions that tempt.
All LTD tools arguably reflect the aims and principles of the UNIX philosophy, which has been summarised as:
Write programs that do one thing and do it well. Write programs to work together. Write programs to handle text streams, because that is a universal interface.
Portability
LTD is generally very portable. If you can use vim, it will work in a variety of situations, both friendly and hostile. vim, for example can easily be run on Windows, MacOS, Linux, or even that old HPUX server which doesn’t even run bash, yet does run your mission-critical database.
Speed
These tools tend to run fast when doing their work, and take little time to start up. This can make a big difference if you are in a ‘flow’ state when coding. They also tend to offer fewer distractions as you’re working. I just started up VSCode on my M2 Mac in a random folder with one file in it, and it took over 30 seconds until I could start typing.
Power
Although the learning curve can be steep, these tools tend to allow you to do extremely powerful things. The return on the investment, after an initial dip, is steep and long-lasting. Just ask any emacs user.
Composability / Embeddability
Because these tools have fewer dependencies, they tend to be more easily composable with – or embeddable in – one another. This is a consequence of the Unix philosophy.
For example, using vim inside a running Docker container is no problem, but if you want to exec onto your Ubuntu container running in production and run VSCode quickly and easily, good luck with all that. (Admittedly, VSCode is a tool I do use occasionally, as it’s very powerful for certain use cases, very widely used, and seems designed to make engineers’ lives easier rather than collect a fee. But I do so under duress, usually.)
And because they use also typically use standard *nix conventions, these tools can be chained together to produce more and more bespoke solutions quickly and flexibly.
Users’ Needs Are Emphasised
LTD tools are generally written by and for the user’s needs, rather than any purchaser’s needs. Purchasers like fancy GUIs and point-and-click interfaces, and ‘new’ tools. Prettiness and novelty don’t help the user in the long term.
More Sustainable
These tools have been around for decades (in most cases), and are highly unlikely to go away. Once you’ve picked one for a task, it’s unlikely you’ll need a new one.
More Maintainable
Again, because these tools have been around for a long time, they tend to have a very stable interface and feature set. There’s little more annoying than picking up an old project and discovering you have to upgrade a bunch of dependencies and even rewrite code to get your project fired up again (I’m looking at you, node).
Here’s an edited example of a project I wrote for myself which mirrors some of the projects we have built for our more engineering-focussed clients.
Developer experience starts with a Makefile. Traditionally, Makefiles were used for compiling binaries efficiently and accounting for dependencies that may or may not need updating.
In the ‘modern’ world of software delivery, they can be used to provide a useful interface for the engineer for what the project can do. As the team works on the project they can add commands to the list for tasks that they often perform.
docker_build: ## Build the docker image to run in docker build -t data-scraper . | tee /tmp/data-scraper-docker-build docker tag data-scraper:latest docker.io/imiell/data-scraper
get_latest: docker_build ## Get latest data @docker run \ -w="/data-scraper" \ --user="$(shell id -u):$(shell id -g)" \ --volume="$(PWD):/data-scraper" \ --volume="$(HOME)/.local:/home/imiell/.local" \ -- volume="$(HOME)/.bash_history:/home/imiell/.bash_history" \ --volume="/etc/group:/etc/group:ro" \ --volume="/etc/passwd:/etc/passwd:ro" \ --volume="/etc/shadow:/etc/shadow:ro" \ --network="host" \ --name=get_latest_priority \ data-scraper \ ./src/get-latest.sh
It’s a great way of sharing ‘best practice’ within a team.
I then have a make.sh script which wraps calls to make with features such as capturing logs in a standard format and cleaning up any left-over files once a task is done. I then use that script in a crontab in production like this:
A challenge with make is that it has quite a steep learning curve for most engineers to write, and an idiosyncratic syntax (to younger eyes, at least).
Whenever I learn a new technology an old one falls out of my brain.
However, while it can seem tricky to write Makefiles, it’s relatively easy to use them, which makes them quite a useful tool for getting new team members onboarded quickly. And for my personal projects – given enough time passing – new team members can mean me! If I return to a project after a time, I just run make help and I can see instantly what my developer workflow looked like.
Here’s an example make help on a project I’m working on:
This means if I have to onboard a new engineer, they can just run make help to determine what actions they can perform, and because most of the tasks run in containers or use standard tooling, it should work anywhere the command line and Docker is available.
This idea is similar to Dagger, which seeks to be a portable CI/CD engine where steps run in containers. However, running Dagger on Kubernetes requires privileged access and carries with it a Dagger engine, which requires installation and maintenance. make requires none of these moving parts, which makes maintenance and installation significantly simpler. The primitives used in Make can be used in your CI/CD tool of choice to create a similar effect.
What Low-Tech Devex Tools Should You Know About?
Here is a highly opinionated list of LTD tooling that you should know:
shell
Mastery of shells are essential to LTD; they underpin almost all of them.
vim/emacs
Already mentioned above, vim is available everywhere and is very powerful and flexible. Other similar editors are available and inspire similar levels of religious fervour.
make
Make is the cockroach of build tools: it just won’t die. Others have come and gone, some are still here, but make is always there, does the job, and can’t go out of fashion because it’s always been out of fashion.
However, as noted above, the learning curve is rather steep. It also has its limits in terms of whizz-bang features.
Docker
The trendiest of these. I could talk instead of chroot jails and how they can improve devex and delivery a lot on their own, but I won’t go there, as Docker is now relatively ubiquitous and mature. Docker is best enjoyed as a command line interface (CLI) tool, and it’s speed and flexibility composed with some makefiles or shell scripts can improve developer experience enormously.
tmux / screen
When your annoying neighbour bangs on about how the terminal can’t give you the multi-window joy of a GUI IDE, crack your knuckles and show them one of these tools. Not only can they give you windowing capabilities, they can be manipulated faster than someone can move a mouse.
I adore tmux and key sequences like :movew -r and CTRL+B z CTRL+B SPACE are second nature to me now.
git
Distributed source control at the command line. ’nuff said.
curl
cURL is one of my favs. I prefer to use it over GUI tools like Postman, as you can just save command lines in Markdown files for how-to guides and playbooks. And it’s super useful when you want to debug a network request by ‘exporting as cURL command’ from Chrome devtools.
cloud shell
Cloud providers provide in-browser terminals with the provider’s CLI installed. This avoids the need to configure keys (if you are already logged in) and worry about the versioning or dependencies of the CLI. I agree with @hibri here.




 An OSCAL example catalog (highlighted) and its related nodes.
An OSCAL example catalog (highlighted) and its related nodes. This graph shows how the Plan of Action and Milestones (highlighted, large brown node) is related to the Assessment Plan (the large orange node). Tracing through, you can see that ‘Assessment Plan’ nodes are related to ‘Assessment Result’ nodes via ‘Party’ nodes and ‘Role’ nodes.
This graph shows how the Plan of Action and Milestones (highlighted, large brown node) is related to the Assessment Plan (the large orange node). Tracing through, you can see that ‘Assessment Plan’ nodes are related to ‘Assessment Result’ nodes via ‘Party’ nodes and ‘Role’ nodes.


.png?width=1064&height=1703&name=history_devops_tools.drawio%20(1).png)
 APIs all the way down: The Linux API calls that mkdir makes in order to create a folder.
APIs all the way down: The Linux API calls that mkdir makes in order to create a folder.
