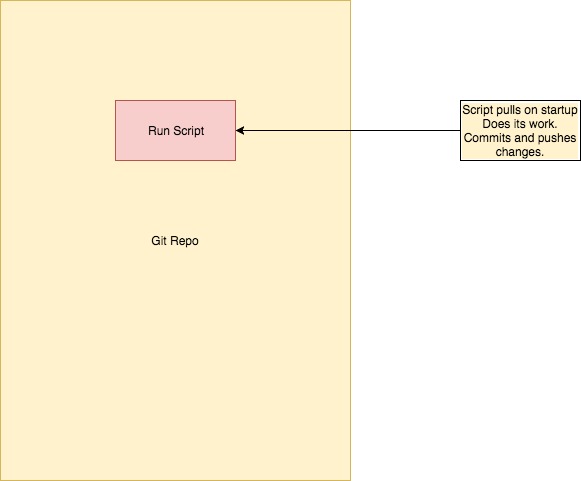
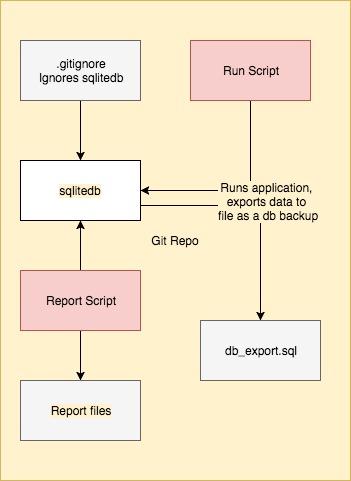
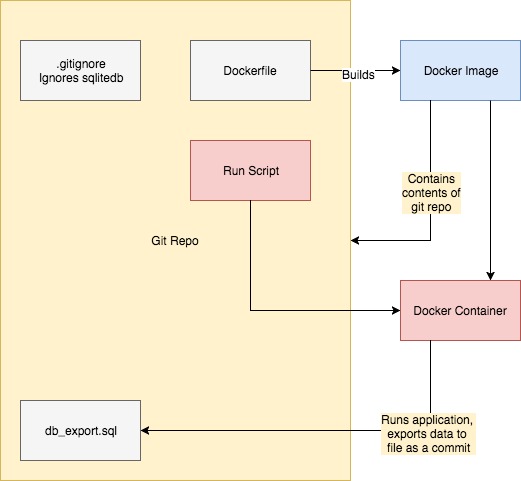
Overview
Docker is extremely popular with developers, having gone as a product from zero to pretty much everywhere in a few years.
I started tinkering with Docker four years ago, got it going in a relatively small corp (700 employees) in a relatively unregulated environment. This was great fun: we set up our own registry, installed Docker on our development servers, installed Jenkins plugins to use Docker containers in our CI pipeline, even wrote our own build tool to get over the limitations of Dockerfiles.
I now work for an organisation working in arguably the most heavily regulated industry, with over 100K employees. The IT security department itself is bigger than the entire company I used to work for.
There’s no shortage of companies offering solutions that claim to meet all the demands of an enterprise Docker platform, and I seem to spend most of my days being asked for opinions on them.
I want to outline the areas that may be important to an enterprise when considering developing a Docker infrastructure.
Images
Registry
You will need a registry. There’s an open source one (Distribution), but there’s numerous offerings out there to choose from if you want to pay for an enterprise one.
- Does this registry play nice with your authentication system?
- Does it have role-based access control (RBAC)?
Authentication and authorization is a big deal for enterprises. While a quick and cheap ‘free for all’ registry solution will do the job in development, if you have security or RBAC standards to maintain, these requirements will come to the top of your list.
- Does it have a means of promoting images?
All images are not created equal. Some are ‘quick and dirty’ dev experiments where ‘correctness’ is not a requirement, while others are intended for bullet-proof production usage. Your organisation’s workflows may require that you distinguish between the two, and a registry can help you with this, by managing a process via separate instances, or through gates enforced by labels.
- Does it cohere well with your other artefact stores?
You likely already have an artefact store for tar files, internal packages and the like. In an ideal world, your registry would simply be a feature within that. If that’s not an option, integration or management overhead will be a cost you should be aware of.
Image Scanning
An important one.
When images are uploaded to your registry, you have a golden opportunity to check that they conform to standards. For example, could these questions be answered:
- Is there a shellshock version of bash on there?
- Is there an out of date ssl library?
- Is it based on a fundamentally insecure or unacceptable base image?
- Are the ‘wrong’ or out of date (based on your org’s standards) development libraries, or tools being used?
Static image analysers exist and you probably want to use one.
What’s particularly important to understand here is that these scanners are not perfect, and can miss very obviously bad things that end up within images. So you have to decide whether paying for a scanner is worth the effort, and what you want to get out of the scanning process.
In particular, are you wanting to:
- Prevent malicious actors inserting objects into your builds?
- Enforce company-wide standards on software usage?
- Quickly patch known and standard CVEs?
These questions should form the basis of your image scanning evaluations. As usual, you will need to consider integration costs also.
Image Building
How are images going to be built? Which build methods will be supported and/or are strategic for your organisation? How do these fit together?
Dockerfiles are the standard, but some users might want to use S2I, Docker + Chef/Puppet/Ansible or even hand-craft them.
- Which CM tool do you want to mandate (if any)
- Can you re-use your standard governance process for your configuration management of choice?
- Can anyone build an image?
Real-world experience suggests that the Dockerfile approach is one that is deeply ingrained and popular with developers. The overhead of learning a more sophisticated CM tool to conform to company standards for VMs is often not one they care for. Methods like S2I or Chef/Puppet/Ansible are more generally used for convenience or code reuse. Supporting Dockerfiles will ensure that you will get fewer questions and pushback from the development community.
It is also a useful way round limitations with whatever build method you support: ‘you can always do it yourself with a Dockerfile if you want’.
Image Integrity
You need to know that the images running on your system haven’t been tampered with between building and running.
- Have you got a means of signing images with a secure key?
- Have you got a key store you can re-use?
- Can that key store integrate with the products you choose?
Image integrity is still an emergent area, even after a few years. There is generally a ‘wait and see’ approach from most vendors. Docker Inc. have done some excellent work in this area, but Notary (their open source signing solution) is considered difficult to install outside of their Datacentre product, and is a significant value-add there.
Third Party Images
Vendors will arrive with Docker images expecting there to be a process of adoption.
- Do you have a governance process already for ingesting vendor technology?
You will need to know not only whether the image is ‘safe’, but also who will be responsible for updates to the image when required?
- Can it be re-used for other Docker images?
There are potential licensing issues here! Do you have a way to prevent images available to be re-used by other projects/teams?
- Do you need to mandate specific environments (eg DMZs) for these to run on?
- Will Docker be available in those environments?
For example, many network-level applications operate on a similar level to network appliances, and require access that means it must be run isolated from other containers or project work. Do you have a means of running images in these contexts?
SDLC
If you already have software development lifecycle (SDLC) processes, how does Docker fit in?
- How will patches be handled?
- How do you identify which images need updating?
- How do you update them?
- How do you tell teams to update?
- How do you force them to update if they don’t do so in a timely way?
This is intimately related to the scanning solutions mentioned above. Integration of these items with your existing SDLC processes will likely need to be considered at some point.
Secrets
Somehow information like database passwords need to be passed into your containers. This can be done at build time (probably a bad idea), or at run time.
- How will secrets be managed within your containers?
- Is the use of this information audited/tracked and secure?
Again, this is an emergent area that’s still fast-changing. Integrations of existing solutions like OpenShift/Origin with Hashicorp’s Vault exist (eg see here), and core components like Docker Swarm have secrets support, while Kubernetes 1.7 beefed up its security features recently.
Base Image?
If you run Docker in an enterprise, you might want to mandate the use of a company-wide base image:
- What should go into this base image?
- What standard tooling should be everywhere?
- Who is responsible for it?
Be prepared for lots of questions about this base image! Developers get very focussed on thin images (a topic dealt with at length in my book Docker in Practice).
Security and Audit
The ‘root’ problem
By default, access to the docker command (and specifically access to the Docker UNIX socket) implies privileges over the whole machine. This is explicitly called out in the Docker documentation. This is unlikely to be acceptable to most sec teams in production.
You will need to answer questions like these:
- Who (or what) is able to run the docker command?
- What control do you have over who runs it?
- What control do you have over what is run?
Solutions exist for this, but they are relatively new and generally part of other larger solutions.
OpenShift, for example, has robust RBAC control, but this comes with buying into a whole platform. Container security tools like Twistlock and Aquasec offer a means of managing these, so this might be factored into consideration of those options.
Monitoring what’s running, aka ‘runtime control’
A regulated enterprise is likely to want to be able to determine what is running across its estate. What can not be accounted for?
- How do you tell what’s running?
- Can you match that content up to your registry/registries?
- Have any containers changed critical files since startup?
Again, this comes with some other products that might form part of your Docker strategy, so watch out for them.
Another frequently-seen selling point in this space is anomaly detection. Security solutions offer fancy machine learning solutions that claim to ‘learn’ what a container is supposed to do, and alert you if it appears to do something out of the ordinary, like connect out to a foreign application port unrelated to the application.
While this sounds great, you need to think about how this will work operationally – you can get a lot of false positives, and these may require a lot of curation – are you equipped to handle that?
Forensics
When things go wrong people will want to know what happened. In the ‘old’ world of physicals and VMs there were a lot of safeguards in place to assist post-incident investigation. A Docker world can become one without ‘black box recorders’.
- Can you tell who ran a container?
- Can you tell who built a container?
- Can you determine what a container did once it’s gone?
- Can you determine what a container might have done once it’s gone?
In this context you might want to mandate the use of specific logging solutions, to ensure that information about system activity persists across container instantiations.
Sysdig and their Falco is another interesting and promising product in this area.
Operations
Logging
Application logging is likely to be a managed or controlled area of concern:
- Do the containers log what’s needed for operations?
- Do they follow standards for logging?
- Where do they log to?
Container usage can follow very different patterns from traditional machine/VM deployments. Logging volume may increase, causing extra storage demands.
Orchestration
Containers can quickly proliferate across your estate, and this is where orchestration comes in. Do you want to mandate one?
- Does your orchestrator of choice play nicely with other pieces of your Docker infrastructure?
- Do you want to bet on one orchestrator, hedge with a mainstream one, or just sit it out until you have to make a decision?
Kubernetes seems to be winning the orchestration war. These days, not choosing Kubenetes (assuming you need to choose one) needs a good reason to back it up.
Operating System
Enterprise operating systems can lag behind the latest and greatest.
- Is your standard OS capable of supporting all the latest features? For example, some orchestrators and Docker itself require kernel versions or packages that may be more recent than is supported. This can come as a nasty surprise…
- Which version of Docker is available in your local package manager?
Docker versions sometimes have significant differences between them (1.10 was a big one), and these can take careful management to navigate through. There can also be differences between vendors’ Docker (or perhaps we should say ‘Moby‘ versions), which can be significant. RedHat’s docker binary calls out to RedHat’s registry before Docker’s, for example!
Development
Dev environments
- Developers love having admin. Are you ready to effectively give them admin with Docker?
There are options here to give developers a VM in which to run Docker builds locally, or just the docker client, with the server running elsewhere.
- Are their clients going to be consistent with deployment?
If they’re using docker-compose on their desktop, they might resent switching to Kubernetes pods in UAT and production!
CI/CD
Jenkins is the most popular CI tool, but there’s other alternatives popular in the enterprise, such as TeamCity.
Docker brings with it many potential plugins that developers are eager to use. Many of these are not well-written safe, or even consistent with other plugins.
- What’s your policy around CI/CD plugins?
- Are you ready to switch on a load of new plugins PDQ?
- Does your process for CI cater for ephemeral Jenkins instances as well as persistent, supported ones?
Infrastructure
Shared Storage
Docker has in its core the use of volumes that are independent of the running containers, in which persistent data is stored.
- Is shared storage easy to provision?
NFS servers have their limitations but are mature and generally well-supported in larger organisations.
- Is shared storage support ready for increased demand?
- Is there a need for shared storage to be available across deployment locations?
You might have multiple data centres and/or cloud providers. Do all these locations talk to each other? Do they need to?
Networking
Enterprises often have their own preferred Software Defined Networking (SDN) solutions, such as Nuage, or new players like Calico.
- Do you have a prescribed SDN solution?
- How does that interact with your chosen solutions?
- Does SDN interaction create an overhead that will cause issues?
aPaaS
Having an aPaaS such as OpenShift or Tutum Cloud can resolve many of the above questions by centralising and making supportable the context in which Docker is run.
- Have you considered using an aPaaS?
- Which one answers the questions that need answering?
Cloud Providers
If you’re using a cloud provider such as Amazon or Google:
- How do you plan to deliver images and run containers on your cloud provider?
- Do you want to tie yourself into their Docker solutions, or make your usage cloud-agnostic?
A Note on Choosing Solutions
Finally, it’s worth discussing two approaches that can be taken to solve your Docker needs. You can go all-in with a single supplier, or piece together a solution from smaller products that fulfil each (or subsets) of your requirements separately.
The benefits of going all-in with a single supplier include:
- Single point of support
- Less integration effort and overhead
- Faster delivery
- Greater commitment and focus from the supplier
- Influence over product direction
- Easier to manage
Single supplier solutions often demand payment per node, which can result in escalating costs that can lead to regret, or constraints on your architectures which might not be appreciated at first.
The benefits of ‘piecing together’ a solution include:
- More flexible solutions can be delivered at different rates, depending on organisational need
- A less monolithic approach can allow you to back out of ‘mistakes’ made in the product acquisition process
- It can be cheaper in the long run, not least because…
- You are not ‘locked-in’ to one supplier that can hold you to ransom in future
Conclusion
The enterprise Docker field is confusing and fast-changing. Developing a strategy that is cost-effective, safe, complete, adaptive, delivered fast, and coming without lock-in is one of the biggest challenges facing large-scale organisations today.
Best of luck!
This is based on work in progress from the second edition of Docker in Practice
Get 39% off with the code: 39miell2














 It’s just not that easy, like the book says:
‘Telling effective stories is not easy. The difficulty lies not in telling the story, but in convincing everyone else to believe it. Much of history revolves around this question: how does one convince millions of people to believe particular stories about gods, or nations, or limited liability companies? Yet when it succeeds, it gives Sapiens immense power, because it enables millions of strangers to cooperate and work towards common goals. Just try to imagine how difficult it would have been to create states, or churches, or legal systems if we could speak only about things that really exist, such as rivers, trees and lions.’
Let’s rephrase that:
‘Coming up with useful software methodologies is not easy. The difficulty lies not in defining them, but in convincing others to follow it. Much of the history of software development revolves around this question: how does one convince engineers to believe particular stories about the effectiveness of requirements gathering, story points, burndown charts or backlog grooming? Yet when adopted, it gives organisations immense power, because it enables distributed teams to cooperate and work towards delivery. Just try to images how difficult it would have been to create Microsoft, Google, or IBM if we could only speak about specific technical challenges.’
Anyway, does the world need more methodologies? It’s not like some very smart people haven’t already thought about this.
http://imgs.xkcd.com/comics/standards.png
It’s just not that easy, like the book says:
‘Telling effective stories is not easy. The difficulty lies not in telling the story, but in convincing everyone else to believe it. Much of history revolves around this question: how does one convince millions of people to believe particular stories about gods, or nations, or limited liability companies? Yet when it succeeds, it gives Sapiens immense power, because it enables millions of strangers to cooperate and work towards common goals. Just try to imagine how difficult it would have been to create states, or churches, or legal systems if we could speak only about things that really exist, such as rivers, trees and lions.’
Let’s rephrase that:
‘Coming up with useful software methodologies is not easy. The difficulty lies not in defining them, but in convincing others to follow it. Much of the history of software development revolves around this question: how does one convince engineers to believe particular stories about the effectiveness of requirements gathering, story points, burndown charts or backlog grooming? Yet when adopted, it gives organisations immense power, because it enables distributed teams to cooperate and work towards delivery. Just try to images how difficult it would have been to create Microsoft, Google, or IBM if we could only speak about specific technical challenges.’
Anyway, does the world need more methodologies? It’s not like some very smart people haven’t already thought about this.
http://imgs.xkcd.com/comics/standards.png