For those of us obsessed with automation, the PhantomJS library was manna from heaven, allowing you to programmatically automate web interactions against a ‘real’ web browser without need a screen to interact with.
Headless Chrome is still new, and there isn’t much material to chew on yet, but I came across this blog post, which shows how to set up an Ubuntu Trusty server with a simple screen grabber script.
I thought I’d transfer this to a Docker container, as lightweight spinning up of these processes will be a boon for testing.
Here’s a video of the script getting screenshots of two randomly-chosen websites:
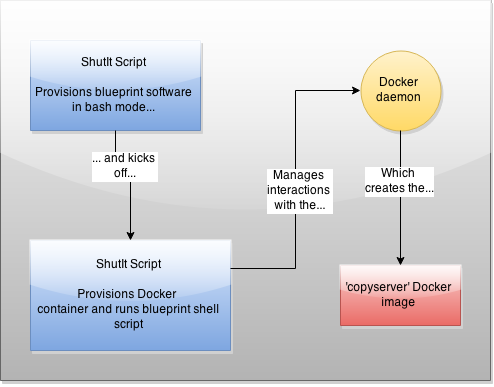
Let’s say you have a server that has been lovingly hand-crafted that you want to containerize.
Figuring out exactly what software is required on there and what config files need adjustment would be quite a task, but fortunately blueprint exists as a solution to that.
What I’ve done here is automate that process down to a few simple steps. Here’s how it works:
You kick off a ShutIt script (as root) that automates the bash interactions required to get a blueprint copy of your server, then this in turn kicks off another ShutIt script which creates a Docker container that provisions the container with the right stuff, then commits it. Got it? Don’t worry, it’s automated and only a few lines of bash.
There are therefore 3 main steps to getting into your container:
– Install ShutIt on the server
– Run the ‘copyserver’ ShutIt script
– Run your copyserver Docker image as a container
Step 1
Install ShutIt as root:
sudo su -
pip install shutit
The pre-requisites are python-pip, git and docker. The exact names of these in your package manager may vary slightly (eg docker-io or docker.io) depending on your distro.
You may need to make sure the docker server is running too, eg with ‘systemctl start docker’ or ‘service docker start’.
If you’ve used Jenkins for a while in production, then you will be aware that Jenkins frequently publishes updates to its server for security and functionality changes.
On a dedicated, non-dockerized host, this is generally managed for you through package management. With Docker it can get slightly more complicated to reason about upgrades, as you’ve likely separated out the context of the server from its data.
Problem
You want to reliably upgrade your Jenkins server.
Solution
This technique is delivered as a Docker image composed of a number of parts. First we will outline the Dockerfile that builds the image. This Dockerfile draws from the library docker image (which contains a docker client) and adds a script that manages the upgrade.
The image is run in a docker command that mounts the docker items on the host, giving it the ability to manage any required Jenkins upgrade.
Dockerfile
We start with the Dockerfile:
FROM docker <1>ADD jenkins_updater.sh /jenkins_updater.sh<2>RUN chmod +x /jenkins_updater.sh<3>ENTRYPOINT /jenkins_updater.sh<4>
<1> – Use the ‘docker’ standard library image
<2> – Add in the ‘jenkins_updater.sh’ script (see below)
<3> – Ensure that the ‘jenkins_updater.sh’ script is runnable
<4> – Set the default entrypoint for the image to be the ‘jenkins_updater.sh’ script
The above Dockerfile encapsulates the requirements to back up Jenkins in a runnable Docker image. It uses the ‘docker’ standard library image. We use this to get a Docker client to run within a container. This container will run the script in the next listing to manage any required upgrade of Jenkins on the host.
NOTE: If your docker daemon version differs from the version in the ‘docker’ Docker image, then you may run into problems. Try to use the same version.
jenkins_updater.sh
This is the shell script that manages the upgrade within the container:
<1> – This script uses the ‘sh’ shell (not the ‘/bin/bash’ shell) because only ‘sh’ is available on the ‘docker’ Docker image
<2> – This ‘set’ command ensures the script will fail if any of the commands within it fail
<3> – This ‘set’ command logs all the commands run in the script to standard output
<4> – The ‘if’ block only fires if ‘docker pull jenkins’ does not output ‘up to date’
<5> – When upgrading, begin by stopping the jenkins container
<6> – Once stopped, rename the jenkins container to ‘jenkins.bak.’ followed by the time to the minute
<7> – Copy the Jenkins container image state folder to a backup
<8> – Run the docker command to start up Jenkins, and run it as a daemon
<9> – Set the jenkins container to always restart
<10> – Mount the jenkins state volume to a host folder
<11> – Give the container the name ‘jenkins’ to prevent multiple of these containers running simultaneously by accident
<12> – Publish the 8080 port in the container to the 8080 port on the host
<13> – Finally, the jenkins image name to run is given to the docker command
The above script tries to pull jenkins from the docker hub with the ‘docker pull’ command. If the output contains the phrase ‘up to date’, then the ‘docker pull | grep …’ command returns true. However, we only want to upgrade when we did _not_ see ‘up to date’ in the output. This is why the ‘if’ statement is negated with a ‘!’ sign after the ‘if’.
The result is that the code in the ‘if’ block is only fired if we downloaded a new version of the ‘latest’ Jenkins image. Within this block, the running Jenkins container is stopped and renamed. We rename it rather than delete it in case the upgrade did not work and we need to reinstate the previous version.
Further to this rollback strategy, the mount folder on the host containing Jenkins’ state is backed up also.
Finally, the latest-downloaded Jenkins image is started up using the docker run command.
NOTE: You may want to change the host mount folder and/or the name of the running Jenkins container based on personal preference.
The attentive reader might be wondering how this Jenkins image is connected to the host’s Docker daemon. To achieve this, the image is run using a commonly-used method in the book:
NOTE: The above is all on one line because crontab does not ignore newlines if there is a backslash in front in the way that shellscripts do.
The end result is that a single crontab entry can safely manage the upgrade of your Jenkins instance without you having to worry about it. The task of automating the cleanup of old backed up containers and volume mounts is left as an exercise for the reader.
Discussion
This technique exemplifies a few things which we come across throughout the book which can be applied in similar contexts to situations other than Jenkins.
First, it uses the core docker image to communicate with the Docker daemon on the host. Other portable scripts might be written to manage Docker daemons in other ways. For example, you might want to write scripts to remove old volumes, or report on the activity on your daemon.
More specifically, the ‘if’ block pattern could be used to update and restart other images when a new one is available. It is not uncommon for images to be updated for security reasons, or to make minor upgrades.
If you are concerned with difficulties in upgrading versions, it’s also worth pointing out that you need not take the ‘latest’ image tag (which this technique does). Many images have different tags that track different version numbers.
For example, your image ‘exampleimage’ might have a exampleimage:latest tag, as well as an exampleimage:v1.1 tag, and a exampleimage:v1. Any of these might be updated at any time, but the :v1.1 tag is less likely to move to a new version than the :latest one. The :latest one could move to the same version as a new :v1.2 one (which might require steps to upgrade) or even a :v2.1 one, where the new major version ‘2’ indicates a change more likely to be disruptive to any upgrade process.
This technique also outlines a rollback strategy for docker upgrades. The separation of container and data (using volume mounts) can create tension about the stability of any upgrade. By retaining the old container and a copy of the old data at the point where the service was working, it is easier to recover from failure.
Database Upgrades and Docker
Database upgrades are a particular context in which these stability concerns are germane.
If you want to upgrade your database to a new version, you have to consider whether the upgrade requires a change to the data structures and storage of the database’s data. It’s not enough simply to run the new version’s image as a container and expect it to work.
It gets a bit more complicated if the database is ‘smart’ enough to know which version of the data it is ‘seeing’, and can perform the upgrade itself accordingly. In these cases, you might be more comfortable upgrading.
Many factors feed into your upgrade strategy. Your app might tolerate an ‘optimistic’ approach (as we see here in the Jenkins example) which assumes everything will be OK, and prepares for failure when (not if) it occurs. On the other hand, you might demand 100% uptime, and not tolerate failure of any kind at all. In such cases, a fully-tested upgrade plan and a deeper knowledge of the platform than running ‘docker pull’ is generally desired (with or without the involvement of Docker).
Although Docker does not remove the upgrade problem, the immutability of the versioned images can make it simpler to reason about them. Docker can also help you prepare for failure in two ways: backing up state in host volumes, and making testing predictable state more easy. The hit you take in managing and understanding what Docker is doing can give you more control and certainty about the upgrade process.
This technique is taken from the upcoming second edition of my book Docker in Practice:
It’s a good idea to keep stages discrete, as they can be isolated from one another – for example, you could switch one stage to another node (see below) if you want (but then you might want to look into stash()ing files…).
2) Wrap Steps in a Node
All code that does steps in a pipeline should be wrapped in a node block:
node() {
sh('env')
}
If the node is not specified, eg:
def myvariable='blah'
then by default it will run on the master.
You can specify the node by supplying an argument:
node('mynode') {
[...]
}
If the pipeline code is not in a node block, then it’s run on the master in some kind of lightweight node/thread.
3) Checkout scm doesn’t work in browser UI!
This was a gotcha for me. ‘checkout scm’ is a great single line to add to your script that checks out the source the Jenkinsfile is taken from.
But when updating the script in the Jenkins browser interface this won’t work!
When storing your source in source control, you can then switch to using ‘checkout scm’. Otherwise use the ‘git’ function.
Handy, eg for seeing whether a node is available (see next tip)…
5) Use try / catch to dynamically decide what to do
Your code can be wrapped in a try/catch block.
I use this along witha function and timeout() to see whether a node is available before using it:
def nodetest() {
sh('echo alive on $(hostname)')
}
// By default we use the 'welles' node, which could be offline.
usenode='welles'
try {
// Give it 5 seconds to run the nodetest function
timeout(time: 5, unit: 'SECONDS') {
node(usenode) {
nodetest()
}
}
} catch(err) {
// Uh-oh. welles not available, so use 'cage'.
usenode='cage'
}
// We know the node we want to use now.
node(usenode) {
[...]
}
6) WTF is the Deal with Pipeline Syntax vs Groovy?
Pipeline syntax may be preferable to groovy, but is newer. See here:
The docs confusingly assume a familiarity with both, and it’s not clear to the casual user why there’s these two ways of doing the same thing.
7) It’s Still a Bit Buggy
In one memorable evening I tried to change the branch a Jenkinsfile was pulled from, but the old branch persisted in my Jenkins build. It wouldn’t pick up changes from the branch I’d change to.
I ended up having to create a new job and delete the old one.
Sometimes you have to kick off a job that fails in order to get the ‘new’ pipeline to be picked up by Jenkins.
8) Input
Want to force user input before continuing?
Simple:
input('OK to continue?')
But – seemed to work better for me when I had defined stages first!
If you’re running jobs in branches and want to ensure they don’t interfere with each other on the same Jenkins node, then locks are a simple way to ensure the serial running of jobs.
These are the bomb. They allow you to parameterize your job so you can do more surgical builds when necessary. You can allow for defaults (like the BRANCH_NAME below), while giving users an interface to run their builds.
We use this internally to build test environments on demands.
Here is a list of books that have helped and changed not only my career, but also my life.
If there’s a theme to them, it’s that they are less about IT than how people interact with technology, and how an understanding of that can make you and your organisation more efficient.
Published in 1984, before Windows 1.0 was released, The Goal is still read by many and recommended by the likes of Jeff Bezos.
Unusually for a business book, it’s a novel. A manager of a factory that is threatened with closure has three months to turn around its dysfunctional organisation. After going on a bender and having a row with his wife, he sobers up and bumps into an old friend that guides him on how to debug his business. He makes it up with his wife and figures out how to turn things around at work.
Many readers will already be aware of The Phoenix Project, a book popular among the DevOps community. TPP is based on The Goal, and has a similar plot. Personally, I prefer The Goal over The Phoenix Project for a couple of reasons.
First, it’s really well-written. It’s a good enough novel that my wife (a mental health nurse with zero interest in IT) read it and enjoyed it in a couple of sittings.
Second, the fact that it’s not about 21st-century software encourages you to think about your work in terms of systems rather than our specific local terms. Continuous improvement, problems of delivery flow, disaffected staff, and angry spouses have always been with us, and the solutions can be surprisingly similar.
For me, this book emphasised and backed up my instinct that in an imperfect world, the importance of focussing on the biggest problems first and the human factor are vital in improving any delivery environment.
Atul Gawande is a surgeon and public health researcher who here looks at three fields: medicine, construction, and aviation. All these fields have little tolerance for failure (buildings that fall down, planes that fall out of the sky, and doctors that kill tend to attract headlines and unwanted attention).
What becomes clear is that there is a maturity model for dealing with failure – first a ‘hero’ model is espoused (think of the aviation heroes of early 20th century adventure and wars, or 18th century doctors), and then complexity ensues, reducing the pool of ‘heroes’ to zero. Following that there’s a crisis, and the implementation of simple processes helps manage the chaos. Aviation went from having the ‘fighter ace’ to ‘too much plane to fly’ and moved to a training model using checklists and human-friendly processes. In medicine, simple checklists help reduce error (and the cost of lawsuits). Standard processes along with creativity – applied reliably and when required – helps buildings stay up.
This book stiffened my resolve to improve documentation and process in a growing business, which I wrote about at more length here.
Another oldie, this time from 1954, it discusses businesses of the day and their challenges in a timeless way (aside from the complete absence of the feminine pronoun).
A glance through it will reveal the same concerns we have always had – the section on ‘Automation’ is itself a fascinating historical document, and applies to today just as much as it did 60 years ago. There is a section on the importance of ‘innovation’ that reads like a contemporary call to arms. If you thought Google was the first organisation to try and do without middle management, there’s a chapter headed ‘Ford’s Attempt To Do Without Managers’.
If last century is so last century, then he looks to the Roman army and the Jesuits (‘the oldest elite corps) for how management training has been shown to work.
This book is a great mind-expander for those who need to start thinking about human organisations and their challenges in delivering what we now call ‘value’.
This is more a work of practical philosophy than about business. Mark Schwartz is a CIO working in the field, who here deconstructs some of the lazy assumptions and rhetoric surrounding what has come to be known as capital a ‘Agile’.
Practical and down-to-earth, he first breaks down what ‘business value’ might mean, and shows that there is little clarity about what this often taken-for-granted concept stands for. Other terms get similar treatment: who is the ‘customer’ in agile; is profit and business success the same thing; how granular can the organisation be?
This book gives you the courage to ask simple questions and not take for granted that the messages you’re getting about how to work are based on solid foundations.
I talked about trusting your local knowledge a while back here and wrote the talk up here.
It’s not often you get a book that’s lucid, useful, and quotes French philosophy while making it relevant.
I picked up this book almost by accident in a bookstore while on holiday. I’d read so many stories and references to it on HackerNews I was ready to mock its easy slogans and trite advice.
Damn, was I wrong! This book didn’t so much change my life as turn it upside down. I was a stressed out, time-poor SRE who couldn’t possibly fulfil all his obligations, and using the advice and guidance here I have since transformed my career by writing a book, developing this blog, and moving jobs.
Again, this is less about technology than the human element to improving efficiency.
Its advice was so pragmatic and sensible that I rue the fact that I didn’t read it decades before.
Did I Miss One?
I’m always on the lookout for good and classic works to read and make me think. If I missed any, let me know.
For several years I managed the 3rd line site reliability operation for many of the world’s busiest gambling sites, working for a little-known company that built and ran the core backend online software for several businesses that each at peak could take tens of millions of pounds in revenue per hour. I left a couple of years ago, so it’s a good time to reflect on what I learned in the process.
In many ways, what we did was similar to what’s now called an SRE function (I’m going to call us SREs, but the acronym didn’t exist at the time). We were on call, had to respond to incidents, made recommendations for re-engineering, provided robust feedback to developers and customer teams, managed escalations and emergency situations, ran monitoring systems, and so on.
The team I joined was around 5 engineers (all former developers and technical leaders), which grew to around 50 of more mixed experience across multiple locations by the time I left.
I’m going to focus here on process and documentation, since I don’t think they’re talked about usefully enough where I do read about them.
If you want to read something far longer Google’s SRE book is a great resource.
Process
Process is essential to running and scaling an SRE operation. It’s the core of everything we achieved. When I joined the team, habits were bad – there was a ticketing system, but one-journal resolutions were not uncommon (‘Site down. Fixed, closing.’).
An SRE operation is basically a factory processing information and should act accordingly. You wouldn’t have a factory running without processes to take care of the movement of goods, and by the same token you shouldn’t have a knowledge-intensive SRE operation running without processes to take care of the movement of knowledge.
One frequent objection to process I heard is that it ‘stifles creativity’. In fact, effective process (bad process implemented poorly can mess anything up!) clears your mind to allow creative thought.
A great book on this subject is ‘The Checklist Manifesto’, which inspired many of the changes we made, and was widely read within the team. It cites the examples of the aviation industry’s approach to process, which enables remarkable creativity under stressful conditions by mental automation of routine operations. There’s even a film about one incident discussed and the pilot himself cited checklists and routine as an enabler of his fast-thinking creativity and control in that stressful situation. In fact, we used a similar process ourselves: in emergency situations, an experienced engineer would dive into finding a solution, while a more junior one would follow the checklist.
Another critique of process is that process can inhibit effective working and collaboration. It absolutely can if process is treated as an entity justified by its own existence rather than another living asset. The only thing that can guard against this is culture. More on that later.
Process – Tooling
The first thing to get right is the ticketing system. Like monitoring solutions, people obsess over which ticketing system is best. And they are wrong to. The ticketing system you use you will generally end up preferring simply due to familiarity. The ticketing system is only bad if it drives or encourages bad processes. What a bad process is depends on the constraints of your business.
It’s far more important to have a ticketing system that functions reliably and supports your processes than the other way round.
Here’s an example. We moved from RT to JIRA during my tenure. JIRA offered many advantages over RT, and I would generally recommend JIRA as a collaborative tool. The biggest problem we had switching, however, was the loss of some functionality we’d built into RT, which was critical to us. RT allowed us to get real-time updates on tickets, which meant that collaboration on incidents was somewhere between chat and ticketing. This record was invaluable in post-incident review. RT also allowed us to hide entries from customers, which again was really hard to lose. We got over it, but these things were surprisingly important because they’d become embedded in our process and culture.
When choosing or changing your ticketing system, think about what’s really important to operations, not specific features that seem nice when on a list. What’s important to you can vary from how nice it looks (seriously – your customers might take you more seriously, and your brand might be about good design), to whether the reporting tools are powerful.
Documentation
After process, documentation is the most important thing, and the two are intimately related.
There’s a book in documentation, because, again, people focus on the wrong things. The critical thing to understand is that documentation is an asset like any other. Like any business assets, documentation:
If properly looked after, will return investment many times over
Requires investment to maintain (like the fabric of a factory)
If out of date, costs money simply because it’s there (like out-of-date inventory)
If of poor quality, or not usable is a liability, not an asset
But this is not controversial – few people disagree with the idea that good documentation is useful. The point is: what do you do about it?
Documentation – Where We Were
We were in a situation where documentation provided to us was not useful (eg from devs: ‘a network partition is not covered here as it is highly unlikely’. Well, guess what happened! And that was documentation they kindly bothered to write…), or we simply relied on previously-journalled investigations (by this time we were writing things down) to figure out what to do next time something similar happened.
This was frustrating all of us, and we spent a long time complaining about the documentation fairy not visiting us before we took responsibility for it ourselves.
Documentation – What I Did
Here’s what I did.
I took two years’ worth of priority incidents (ie those that triggered – or would have triggered – an out of hours call), and listed them. There were over 1700 of them.
Then I categorised them by type of issue.
Then I went through each type of issue and summarised the steps needed to either resolve, or get to a point where escalation was required
This took seven months of my full-time attention. I was a senior employee and I was costing my company lots of money to sit there and write. And because I had a clueful boss, I never got questioned about whether this was a good use of time. I was trusted (culture, again!). I would say it took four months before any dividends at all were seen from this effort. I remember this four-month period as a nerve-wracking time, as my attention was taken away from operations to what could have been a complete waste of my time and my employer’s money and an embarrassing failure.
Why not give it to an underling to do? For a few reasons. This was so important, and we had not done it before so I needed to know it was being done properly. I knew exactly what was needed, so I knew I could write it in such a way that it would be useful to me at the very least. I was also a relatively experienced writer (arts grad, former journalist), so I liked to think that that would help me write well.
We called these ‘Incident Models’ as per ITIL, but they can also be called ‘run books’, ‘crib sheets’, whatever. It doesn’t matter. What mattered was:
They were easy to find/search for
It was easy to identify whether you got a match
They were not duplicated
They could be trusted
We put this documentation in plain text within the ticketing system, under a separate JIRA project.
The documentation team got wind of what we were up to and tried to pressure us to use an internal wiki for this. We flat-out refused, and that was critical: the documentation system’s colocation with the ticketing system meant that searching and updating the documentation had no impedance mismatch. Because it was plain text it was fast, simple to update, and uncluttered. We resisted process that jeopardised the utility of what we were doing.
Documentation and the Criticality of De-cluttering
When we started, we designed a schema for these Incident Models which was a thing of beauty, covering every scenario and situation that could crop up.
In the end it was almost a complete waste of time. What we ended up using was a really dumb structure of:
Statement of problem
Steps 1-n of what to do
Further/deeper discussion, related articles
That was it. Attempts to structure it more thoroughly all failed as it was either confusing to newcomers, created too much administrative overhead, or didn’t cover enough. Some articles developed their own schema over time that was appropriate to the task, and new categories (eg the ‘jump-off’ article that told you which article to go to next) evolved over time. We couldn’t design for these things in advance because we didn’t know what would work or what would not.
Call it ‘agile documentation’ if you want – agile’s what sells these days (it was ITIL back then). Again, what was critical was that simplicity and utility trumped everything else.
There Is No Documentation Fairy
Having spent all this time and effort a couple of other things became clear regarding documentation.
First, we gave up accepting documentation from other teams. If they commented code, great, if there was something useful on the wiki for us to find, also great. But when it came to handing over projects we stopped ‘asking for documentation’. Instead we’d arrange sessions with experienced SREs where the design of the project would be discussed.
Invariably (assuming they had no ops experience), the developer would focus on the things they’d built and how it worked – and these things were often the most thoroughly tested and least likely to fail.
By contrast, the SRE would focus on the weak points, the things that would go wrong. ‘What happens if the network gets partitioned? What if the database runs out of disk? Can we work out from the logs why the user didn’t get paid?’
We’d then go away and write our own documentation and get the engineer to sign off on it – the reverse of the traditional flow! They’d often make useful comments and give us added insights in the process.
The second thing we noticed was that our engineers were still reluctant to update the docs that only they were using. There was still a sense that documentation should be given to them. The leadership had to constantly reinforce that this was their documentation, not tablets of stone handed down from on high, and if they didn’t constantly maintain this, they would become useless.
This was a cultural problem and took a long time to undo. Undoing it also required the documentation changes to be reinforced by process.
In the end, I’d say about 10% of the ongoing working time was spent maintaining and writing documentation. After the initial 7-month burst, most of that 10% was spent on maintenance rather than producing new material.
After getting all this documentation done, we experienced benefits far in excess of the 10% ongoing cost. To call out a few:
Easier onboarding
Before this process started we were reluctant to take on less experienced staff. After, onboarding became a breeze. Among other things the training involved following incidents as they happened and shadowing more experienced staff. New staff were tasked with helping maintain docs, which helped them understand what gaps they had in their knowledge.
Better training
The docs gave us a resource that allowed us to identify training requirements. This ended up being a curriculum of tools and techniques that any engineer could aim to get a working knowledge of.
Less stress through simpler escalation
These was a big one. Before we had the step-by-step incident models, when to escalate was a stressful decision. Some engineers had a reputation for escalating early, and all were insecure about whether they’d ‘missed something obvious’ before calling a responsible tech lead out of hours. SREs would also get called out for not escalating early enough as well!
The incident models removed that problem. Pretty soon, the first question an escalated-to techie asked was ‘have you followed the incident model’? If so, and there something obvious was missed, then gaps in it became clear and quickly-fixed. Soon, non-SREs were busy updating and maintaining the docs themselves for when they were escalated-to. It became a virtuous circle.
Better discipline
The obvious value of documentation to the team helped improve discipline in other respects. Interestingly, SREs previously had the reputation for being the ‘loudest’ team – there was often a lot of ‘lively’ debate, and the team was very social – which made sense, as we relied on each other as a team to cover a large technical area, dealt with often non-technical customer execs, and sharing knowledge and culture was critical.
As time progressed, the team became quieter and quieter – partly due to the advent of chatrooms, increased remote working, and international teams, but also due to the fact that so much of the work became routine: follow the incident model, when you’re done, or don’t understand something, escalate to someone more senior.
Automation
Automating the investigations this way meant that the way was clear to further automate them with software.
Having metrics on which tickets were linked to which incident models meant that we knew where best to focus our effort. We wrote scripts to comb through log files in the background, make encoding issues quicker and simpler to figure out, automate responses to customers (‘Issue was caused by a change made by app admin user XXX’), and a lot more.
These automations inspired an automation tool we built for ourselves based on pexpect: http://ianmiell.github.io/shutit/ But that’s another story. Basically, once we got going it was a virtuous circle of continuous improvement.
Back to Process
Given you have all these assets, how do you prevent them from degrading in value over time? This is where process is critical.
Two processes were critical in ensuring everything continued smoothly: triage and post-incident review.
Process – Triage
5%-10% of time was spent on the triage process. Again, it took a long time to get the process right, but it resulted in massive savings:
Reduce the steps to the minimum useful steps
It’s so tempting to put as much as possible into your triage process, but it’s vital to keep the value in the process over completeness. Any step that is not often useful tends to get skipped over and ignored by the triager.
Focus on saving cost in the process
Looking for duplicates, finding the relevant incident model, reverting quickly to the customer, and escalating early all reduced the cost per ticket significantly. It also saved other engineers the context switch of being asked a question while they’re thinking about something else. It’s hard to evaluate the benefits of these items, but we were able to deal with increased volumes of incidents with fewer people and less difficulty. Senior management and customers noticed.
Recording the details of these efforts also saved time, as (for example) engineers given a triaged ticket could see that the triager searched for previous incidents with a string that maybe they could improve on. It also meant that more experienced staff could review the triage quality.
Review triage
Experienced staff need to review the triage process regularly to ensure it’s actually being applied effectively.
When I moved to another operations team (in a domain I knew far less about), I cut the incident queue in half in about 3 days, just by applying these techniques properly. The triage process was there, but it wasn’t being followed with any thought or oversight, and was given to a junior member of staff who was not the most capable. Big mistake. Triage must be done – or overseen – by someone with a lot of experience, as while it looks routine and mechanical it involves a lot of significant decisions that rest on experience in the field.
And yes, I was the new boss, and I chose to spend my first week doing the ‘lowly’ task of triage. That’s how important I thought it was.
Rota the task
No-one wants to do triage for long, so we rota’d it per week. This allowed some continuity and consistency, but stopped engineers from going crazy by spending too long doing the same task over and over.
Process – Post-Incident Review
The mirror image of triage was the ‘post incident review’. Every ticket was reviewed by an experienced team member. Again, this was a process that took up about 5% of effort, but was also significant.
A standard form was filled out and any recommendations were added to a list of backlog ‘improvement’ tasks which could be prioritised. This gave us a number for technical/process debt that we wanted to look at.
Culture
I’ve mentioned culture a few times, and it’s what you always return to if you’re trying to enact any kind of change at all, since culture is at root a set of conceptual frameworks that underlie all our actions.
I’ve also mentioned that people often focus on the ‘wrong thing’. Time and again I hear people focus on tools and technology rather than culture. Yes, tools and technology are important, but if you’re not using them effectively then they are worse than useless. You can have the best golf clubs in the world, but if you don’t know how to swing and you’re playing baseball then they won’t help much.
Culture requires investment far more than technology does (I invested over half a year just writing documentation, remember). If the culture is right, people will look for the right tools and technology when they need to.
When given a choice about what to spend time and money on, always go for culture first. It cost me a lot of budget, but forcibly removing an ‘unhelpful’ team member was the best thing I did when I took over another team. The rest of the team flowered once he left, no longer stifled by his aggressive behaviour, and many things got done that didn’t before.
We also built a highly effective team with a budget so small that recruiters would phone me up to yell at me what I was looking for was ‘impossible’, but by focussing on the right behaviours, investing time in the people we found, and having good processes in place, we got an extremely effective and loyal team that all went on to bigger and better things within and outside the company (but mostly within!).
Politics
A quick word on politics. You’ve got to pick your battles. You’re unlikely to get the resources you need, so drop the stuff that wont get done to the floor.
Yes, you need a monitoring solution, better documentation, better trained staff, more testing… you are not going to get all these things unless you have a money machine, so pick the most important and try and solve that first. If you try and improve all these things at once, you will likely fail.
After process, and documentation, I tried to crack the ‘reproducible environment’ puzzle. That led me to Docker, and a complete change of career. I talk about these things a little here and here.
I thought that there must be a standard way to test multi-node VM setups, but asking around at work, and on github yielded no answers.
So I came up with my own solution, which I outline here.
ShutItFile
A ShutItFile is a superset of a Dockerfile that allows straighforward automation of automation tasks.
Here’s an example of a ShutItFile that manipulates two VMs, and tests network connectivity between them.
It creates two machines (machine1 and machine2) and logs into them in turn using the ‘VAGRANT_LOGIN’ directive. On each machine it installs python, sets up a simple python http server which serves the text: ‘Hi from machine1’ (from machine1) or ‘Hi from machine2’ from machine2.
It then tests that the output matches expectation from both machines using the ‘ASSERT_OUTPUT’ directive.
To demonstrate the ‘testing’ nature of the ShutItFile, a ‘PAUSE_POINT’ directive is included, which drops you into the run with a terminal, and a deliberately wrong ‘ASSERT_OUTPUT’ directive is included to show what happens when a test fails (and the terminal is interactive). This makes debugging a _lot_ easier.
DELIVERY bash
# Set up trivial webserver on machine1
VAGRANT_LOGIN machine1
INSTALL python
# Add file
RUN echo 'hi from machine1' > /root/index.html
RUN nohup python -m SimpleHTTPServer 80 &
VAGRANT_LOGOUT
# Set up trivial webserver on machine2
VAGRANT_LOGIN machine2
INSTALL python
RUN echo 'hi from machine2' > /root/index.html
RUN nohup python -m SimpleHTTPServer 80 &
VAGRANT_LOGOUT
# Test machine2 from machine1
VAGRANT_LOGIN machine1
INSTALL python
RUN curl machine2
ASSERT_OUTPUT hi from machine2
VAGRANT_LOGOUT
# Test machine1 from machine2
VAGRANT_LOGIN machine2
INSTALL python
RUN curl machine1
ASSERT_OUTPUT hi from machine1
VAGRANT_LOGOUT
# Example debug
VAGRANT_LOGIN machine1
INSTALL python
PAUSE_POINT 'Have a look around, debug away'
# Trigger a 'failure'
RUN curl machine2
ASSERT_OUTPUT will never happen
VAGRANT_LOGOUT
To run this ShutItFile (which we call here ‘ShutItFile.sf’), you run like this:
pip install shutit #use sudo if needed, --upgrade if upgrading
shutit skeleton
Follow the instructions, choosing ‘shutitfile’ as the pattern, and ‘vagrant’ as the delivery method, eg:
$ shutit skeleton
# Input a name for this module.
# Default: /space/git/shutitfile/examples/vagrant/simple_two_machine/shutit_sabers
# Input a ShutIt pattern.
Default: bash
bash: a shell script
docker: a docker image build
vagrant: a vagrant setup
docker_tutorial: a docker-based tutorial
shutitfile: a shutitfile-based project (can be docker, bash, vagrant)
shutitfile
# Input a delivery method from: bash, docker, vagrant.
# Default: ' + default_delivery + '
docker: build within a docker image
bash: run commands directly within bash
vagrant: build an n-node vagrant cluster
vagrant
# ShutIt Started...
# Loading configs...
# Run:
cd /space/git/shutitfile/examples/vagrant/simple_two_machine/shutit_sabers && ./run.sh
# to run.
# Or
# cd /space/git/shutitfile/examples/vagrant/simple_two_machine/shutit_sabers && ./run.sh -c
# to run while choosing modules to build.
and follow the commands given (at the place in bold above) to run.
Initially you are given empty ShutItFiles. You could start by adding the commands from the example here.
A cheatsheet for the various ShutItFile commands is available here.
Regular readers will be familiar with ShutIt, a framework I work on that allows me to automate all sorts of workflows and tools that I publish on GitHub.
This article demonstrates a new feature that uses this platform to make doing expect-type tasks trivial.
Embedded ShutIt
In response to a request, I recently added a feature which may be useful to others.
All this is available in python scripts if you:
pip install shutit
You can now automate interactions in python scripts. This script just gets the hostname and logs it:
Since ShutIt is a big wrapper/platform built onpexpect, it takes care of setting up the prompt, figuring out when the command is done and a whole load of other stuff you never want to worry about about terminals.
ShutIt takes care of determining what package manager is on the host. If you’re not logged in as root it prompts you for a sudo password before attempting the install.
If you want to insert yourself in the middle of the run, you can add a ‘pause_point’, which will hand you back the terminal until you hit CTRL+[, after which it continues:
If you need to wait for something to happen, you can ‘send_until’ a regexp is seen in the output. This trivial example runs a command to wait 20 seconds and then create a file, and the ‘send_until’ command does not complete until the file is created.
Maintaining Docker at scale, I’m more frequently concerned with clusters of VMs than the containers themselves.
The irony of this is not lost on me.
Frequently I need to spin up clusters of machines. Either this is very slow/unreliable (Enterprise OpenStack implementation) or expensive (Amazon).
The obvious answer to this is to use Vagrant, but managing this can be challenging.
So I present here a very easy way to set up a useful Vagrant cluster. With this framework, you can then automate your ‘real’ environment and play to your heart’s content.
$ pip install shutit
$ shutit skeleton
# Input a name for this module.
# Default: /Users/imiell/shutit_resins
[hit return to take default]
# Input a ShutIt pattern.
Default: bash
bash: a shell script
docker: a docker image build
vagrant: a vagrant setup
docker_tutorial: a docker-based tutorial
shutitfile: a shutitfile-based project
[type in vagrant]
vagrant
How many machines do you want (default: 3)? 3
[hit return to take default]
What do you want to call the machines (eg superserver) (default: machine)?
[hit return to take default]
Do you want to have open ssh access between machines? (default: yes) yes
# Run:
cd /Users/imiell/shutit_resins && ./run.sh
to run.
[follow the instructions to run up your cluster.
$ cd /Users/imiell/shutit_resins && ./run.sh
This will automatically run up an n-node cluster and then finish up.
NOTE: Make sure you have enough resources on your machine to run this!
BTW, if you re-run the run.sh it automatically clears up previous VMs spun up by the script to prevent your machine grinding to a halt with old machines.
# Go to machine2 and call machine1's server
shutit.login(command='vagrant ssh machine2')
shutit.login(command='sudo su -')
shutit.install('curl')
shutit.send('curl machine1.vagrant.test')
shutit.logout()
shutit.logout()
Will set up an apache server and curl a request to the first machine from the second.
Examples
This is obviously a simple example. I’ve used this for these more complex setups which are can be instructive and useful:
Following on from my previous post setting up an OpenShift cluster in Vagrant, this post discusses migrating an etcd cluster within a live OpenShift instance to newer servers.
Moving a standalone etcd cluster is relatively straightforward, but when it’s part of an OpenShift cluster — and especially one that’s live and operational — it is a little more involved.
The ordering of actions is important and there are several aspects to consider when planning such a move:
Config management preparation
Stopping the cluster
Creation and distribution of certificates
Data migration
Update of OpenShift config
Update of config management
Here we are using Ansible to provision and maintain the environment.
You can also use Chef to manage your OpenShift cluster.
NOTE: If you have a lot of data in your cluster, you will want to give the new node ample time to receive the data from the other nodes. In this trivial example, there is little data to transfer. Alternatively, you can copy over the data from one of the original nodes.
Drop the Old Members
Now drop the old members from the cluster and remove etcd from those hosts: