Following on from my earlier post on practising grep, this post shows two tutorials you can run on the command line to gain familiarity and get practice in with git bisect and rebase in a realistic and safe way.
They use Docker and ShutIt to help manage state in safe and lightweight way, while guiding you through the process.
If you haven’t seen it, this is a very accurate and smart Downfall satire on Docker’s ecosystem, technology, and culture.
It’s so good that I thought it would be instructive to annotate it so that the state of the art and some technical details of Docker could be better explained.
Tweet me @ianmiell if you spot a problem or want to suggest an improvement.
Annotated script
Henchman: We pushed the images to DockerHub, then used docker-compose to deploy to the cluster
Docker Hub is the public repository of Docker containers, analagous to GitHub.
docker-compose is a tool for managing multiple containers as a unit on a single machine. You’d more likely use docker-swarm to deploy to a cluster
Henchman: We mounted data volumes on these nodes, and linked the app container here. Finally we updated the dns records.
A data volume is the persistent store of data for containers.
Since containers are generally ephemeral, persistent data
is ‘mounted’ to containers on startup.
Hitler: So we’re running 20 containers on every node now. When can we get rid of the excess servers?
It is a promising aspect of Docker that it can reduce your
physical server footprint through ‘max-packing’ containers
on physical tin through reduced resource claims and not
needing to run multiple kernels (the so called ‘Hypervisor tax‘).
Henchman: Mein Fuerer, the kernel… A third party container caused a kernel panic.
Henchman: We’ve lost 70% of the cluster and the data volumes
Presumably the Kernel panic caused this loss.
Presumably also Hitler blames Docker users’ encouragement of free container downloading as the cause (see below).
Hitler: If you never used Docker in production, leave the room now
Figures are hard to come by, but Docker use in production
heavily lags development and test. This is to be expected,
since most new technologies bubble up through developers to
production.
Hitler: What were you thinking? Who the hell uses public containers from DockerHub? For all you know they were made by Russian hackers!
A convenient means of distributing software that effectively hands over control of your machine to the internet.
Hitler: You think anything in public repos is secure because it’s OSS? You’re a bunch of node.jshipsters that just HAVE to install everything you read on Hacker News!
Guilty (but not the node.js bit).
Henchman: But Docker allows us to run our application anywhere!
A paraphrase of Docker’s slogan. ‘Build, ship, and run any app anywhere.’
Hitler: You use a VM just to run Docker on your laptop!
Many users can’t run Docker directly on their machines,
for example if they use Windows or OSX. I use
Docker on an Ubuntu VM running on a Mac.
I’m not sure what Hitler would make of this.
Henchman: Main Fuerer, docker-machine uses a lightweight VM!
Hitler: Do you hear yourself? Why do we need docker if we’re running a VM? A container inside a container!!!
In this context, a VM can be used for isolation, so is considered a container also. A docker advocate would argue that the image is lightweight and easier
to deploy than a VM. Or as I like to say, Docker doesn’t
give you anything a VM can’t, but a computer gives you
nothing nothing an abacus can’t – user experience is key.
Hitler: You archived a whole Linux O/S then used CoW storage because it’s too big.
By ‘Linux O/S’ Hitler here means an operating system’s filesystem, which makes up most
of a Docker image. CoW (copy on write) storage is a feature of Docker where changes to the filesystem
are copied on write to make a new ‘layer‘ ready
for committing as a new image. Images are made
up of these layers, which can be shared between
containers, reducing disk usage. Hitler’s point here
is that the images contain a lot of data, which can be wasteful.
Hitler: Just so you can deploy a 10MB go binary!
Docker is written in Go, a fashionable language. One
of Go’s features is that it generates portable
binaries that can be run across different distributions
with little difficulty. Hitler is making the point that
if that Go binary is portable, why bother with Docker at all?
Hitler: Don’t even talk to me about resource constraints. All that cgroups magic and it still can’t stop a simple fork bomb!
Hitler: And if the database needs all the resources on the server how exactly will Docker allow you to run more programs on it!? Before Docker I just picked the right size VMs.
Docker is not magic. If you need the tin for your application, it won’t help you get more resources.
Hitler: Suddenly people talk to me about datacenter efficiency and “hyperconvergence”. Everybody thinks they’re Google!
Far too many organisations act like they are running at Google scale when they are not.
Hitler: You don’t even run your own machines anymore! People run on GCE, in VM instances that run in Linux containers on Borg!
Google Compute Engine is Google’s alternative to Amazon
Web Services. They run VMs within Linux containers that
themselves run Docker, which presumably Hitler thinks is laughable, but is there to provide greater levels of
security, and likely because Google is not short of
compute! Borg is Google’s cluster management
software, on which Kubernetes is based.
Hitler: People even think Docker is configuration management. They think Docker solves everything!
If Docker is anything, it’s package management.
You might use Dockerfiles for primitive configuration
management, but you can use traditional
CM tools like Chef and Puppet to provision your images.
Hitler: Even Microsoft has containers now. I’m moving everyone to Windows!
The Windows picture is quite complicated. You can: – Run Docker within a VM running on Windows (see above) – Run a Windows container (not widely available yet)
that implements the Docker API. This will talk to the Windows OS API (I assume) rather than the Linux Kernel API so the images built will not run across the systems. – Run bash in Windows natively. See below.
Henchwoman: Don’t cry, you can run bash on windows 10 now.
Hitler: Docker is supposed to have better performance yet that userland proxy is slower than a 28.8k modem and for what, just bind on port 0.
A userland proxy is one written in software and outside the kernel. In-kernel proxies are much faster.
Binding on port 0 gets any available port from the OS.
Docker does something similar by default. Docker performance is not better than natively-run software, but in some cases is arguably better than VMs.
Hitler: Even enterprises want to run Docker now and they still have Red Hat 5 installed.
This happens. RedHat is an enterprise-supported implementation of Linux. RedHat5 was released in 2007.
Hitler: You idiots that Docker will help your application scale.
It won’t. It can allow you to run more instances of your application, which is not the same thing.
Hitler: Use Openstack for all I care.
Openstack is an open-source cloud technology, which is powerful but costly to manage, and somewhat out of favour now.
Let’s say you have a server that has been lovingly hand-crafted that you want to containerize.
Figuring out exactly what software is required on there and what config files need adjustment would be quite a task, but fortunately blueprint exists as a solution to that.
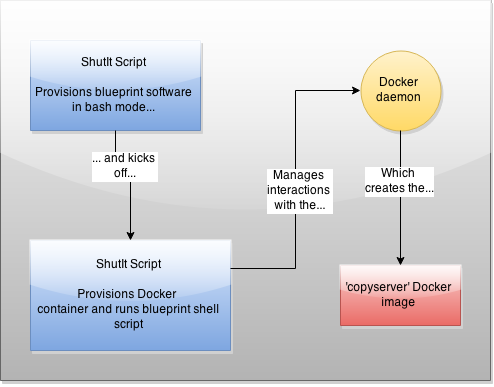
What I’ve done here is automate that process down to a few simple steps. Here’s how it works:
You kick off a ShutIt script (as root) that automates the bash interactions required to get a blueprint copy of your server, then this in turn kicks off another ShutIt script which creates a Docker container that provisions the container with the right stuff, then commits it. Got it? Don’t worry, it’s automated and only a few lines of bash.
There are therefore 3 main steps to getting into your container:
– Install ShutIt on the server
– Run the ‘copyserver’ ShutIt script
– Run your copyserver Docker image as a container
Step 1
Install ShutIt as root:
sudo su -
pip install shutit
The pre-requisites are python-pip, git and docker. The exact names of these in your package manager may vary slightly (eg docker-io or docker.io) depending on your distro.
You may need to make sure the docker server is running too, eg with ‘systemctl start docker’ or ‘service docker start’.
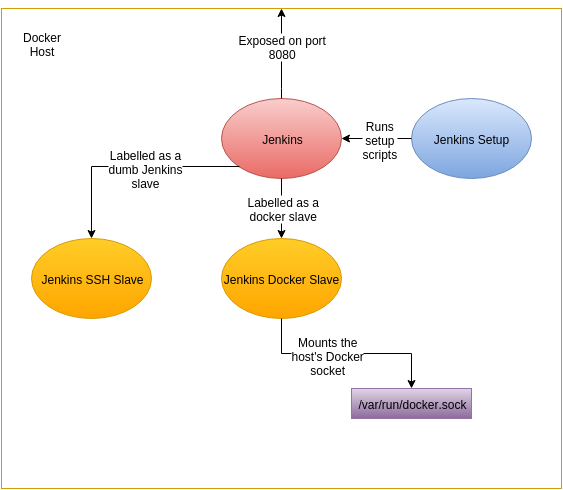
This article continues on from the previous twoposts outlining a method of provisioning Jenkins instances on demand programatically using docker-compose.
In this post we take this one step further by demonstrating how a Docker container can dynamically add itself as a client to the Jenkins server.
Overview
This updated diagram shows the architecture at part III
The ‘Jenkins-Swarm Docker Slave’ is new to this example. It is similar to the ‘Jenkins SSH Slave’ except that it connects itself to the Jenkins server as a slave running as a Docker container. Using this as a template you can dynamically add multiple clients to the Jenkins server under the ‘swarm’ tag.
Note: Do not confuse ‘Jenkins Swarm’ with ‘Docker Swarm’.
They are two different things: Jenkins Swarm allows clients to
dynamically attach themselves to a server and run jobs, while
Docker Swarm is a clustering solution for Docker servers.
New plugins
In addition, these new plugins have been added:
swarm – allow dynamic jenkins clients to be added via port 50000 backup – backs up configuration on demand (basic configuration set up by scripts) jenkinslint – gives advice on your jenkins setup build-timeout – allow a build timeout docker-build-publish – build and publish Docker projects to the Docker Hub greenballs – green balls for success, not blue!
This video demonstrates some of the highlights of the latest Docker version:
User namespacing setup and demo
In-memory filesystem creation
In-flight resource constraining of a CPU-intensive container
Internal-facing Docker network provisioning
Seccomp profile enforcement (updated!)
In-memory filesystems seem particularly apposite for ephemeral and I/O-intensive containers.
The user namespacing feature is neat, but be aware that you need a compatible kernel.
And from an operational perspective, the ability to dynamically constrain resources for a container is a powerful feature.
Secure?
There’s some confusion around whether these changes ‘makes Docker secure’. While user namespacing reduces the risk in one attack vector, and seccomp enforcement policies can reduce them in the other, security is not a binary attribute of any software platform.
For example, you still need to consider the content you are downloading and running, and where those components came from (and who is responsible for them!). Also, if someone has access to the docker command, they still (effectively) are a privileged user.
This article continues on from part one of this series, which looks at ‘CI as code’ using Docker to set up isolated and reproducible phoenix deployments of Jenkins deployments
Here I add dynamic Docker containers as on-demand Jenkins nodes in a Docker cloud.
Here’s a video of the stateless setup of the Docker cloud, and the job ‘docker-test’ which dynamically provisions a Docker container to run as a Jenkins slave.
What it does
Starts up Jenkins container with a server config config.xml preloaded
‘jenkinssetup’ container waits for Jenkins to be up and ready
Sets up global credentials
Updates Jenkins’ config.xml with the credentials id
Restart Jenkins and wait for jenkins to be ready
Kick off install of plugins
Periodically restart Jenkins until plugins confirmed installed
Upload job configurations
Details
The Docker plugins for Jenkins are generally poorly documented and fiddly to set up. And between them there’s quite a few, so the Docker options in a job available can get quite confusing. This took a little bit of trial and error before I could reliably get it to work.
To allow dynamic Docker provisioning, I used the standard docker plugin, mainly because it was the only one I ended up getting working with my Jenkins-in-docker-compose approach.
To get a dynamic on-demand Docker instance provisioned for every build, you have to set up a Docker cloud with the details of the Docker host to contact to spin up the container. This cloud is given a label, which you use in your job to specify that it should be run in a Docker container.
Note: If you want to recreate this you must have an opened-up Docker daemon.
See here for a great guide on this. Once that’s done you may need to change the
docker host address in the docker.xml field to point to your opened up Docker
daemon. Usually this is with the IP address outputted from ‘ip route’ in your
running containers. The default in the git repo is fine, assuming you have opened
it up on port 4243.
I don’t know about you, but I’ve always been uncomfortable with Jenkins’ apparent statefulness. You set up your Jenkins server, configure it exactly as you want it, then DON’T TOUCH IT.
For an industry apparently obsessed with ‘infrastructure/environments/whatever as code’ this is an unhappy state of affairs.
I’d set up a few Jenkins servers, thrown some away, re-set them up, and it always seemed a wasteful process, fraught with forgetfulness.
Fortunately I now have a solution. With a combination of Docker, Python’s Jenkins API modules, the Jenkins job builder Python module, and some orchestration using docker-compose, I can reproduce my Jenkins state at will from code and run it in isolated environments, improving in iterable, track-able steps.
Here’s a video of it running:
This example sets up:
a vanilla Jenkins instance via a Docker container
a simple slave node
a simple docker slave node
a container that sets up Jenkins with:
jobs
a simple echo command with no triggers
a docker echo command triggered from a github push
credentials
plugins
The code is here. I welcome contributions, improvements, suggestions and corrections.
To run it yourself, ensure you have docker-compose installed:
git clone https://github.com/ianmiell/jenkins-phoenix
cd jenkins-phoenix
git checkout tags/v1.0
./phoenix.sh
Navigating the Docker ecosystem can be confusing at the best of times.
I’ve been involved in numerous conversations where people have confused Indexes, Registries, Commits, diffs, pushes, Pods, Containers, Images… the list goes on.
I’ve put together these references to try and help with these confusions. Please get in touch if anything seems amiss, or you have any suggestions for improvements.
Containers are privileged if they run with full root powers. Normally, root within the container has a reduced set of capabilities
Registry
A registry is a hosted service containing repositories of images, which responds to the Docker registry API
Swarm
Docker Swarm is a clustered set of Docker nodes connected and managed by a Swarm manager running on each node
Docker vs Git
Docker
Git
Blob
Most often seen in the context of registries (API version 2) where the objects managed by the registry are stored in binary objects
The git index points to blobs that refer to content making up the repository’s history
Commit
Takes the differences in the container you reference to the last image, and creates a new layer. The added layer and all previous layers constitutes a new image
Takes the changes in your index and stores them in your local repository with a message
Diff
Gives you the files added, updated, or deleted in a layer
Gives a line-by-line diff of files between two revisions in the git repository’shistory
History
The layers that make up an image (in order) constitute an image’s history
The ordered previous revisions in a repository
Hub
DockerHub is an index of images and Dockerfiles managed by Docker.inc.
GitHub is a popular central point of reference for software projects that use git
Index
Apparently deprecated term for a registry
A binary file in a git repository that stores references to all the blobs that make up a repository
Pull
Images are pulled from registries to your local host
Get a set of commits and apply them to your local repository
Push
Committed and taggedimages can be pushed to registries
Commits can be pushed to remoterepositories
Repository
A collection of images distinguished by tag, eg docker.io/ubuntu
A git project, ie the folder you might pull from a git remote
Remote
N/A, though if someone uses this term, they probably mean registry
A repository stored in another location, eg on GitHub or bitbucket.org
Revision
N/A
See commit
Tag
Tags are applied to repositories to distinguish different images, eg docker.io/ubuntu:14.04 is a different image from docker.io/ubuntu:15.04, but both are in the same repository
A reference to a git repository in a particular state
Kubernetes
Endpoint
IP and port that accepts TCP or UDP flows
Kube-proxy
Receives information about changes to services and endpoints
Kubelet
See Replication Controller
Replication Controller
Container supervisor. One of these runs on each host, ensuring the correct pods are running and in the appropriate number
Controller Manager
Orchestrates replication controllers
Pod
A grouping of containers that run on one host, and share volumes and a network stack (ie including IP and ports). Pods can run as one-offs, while long-running services should be spun up by replication controllers
Service
An abstracted endpoint for a set of pods or other endpoint
OpenShift
Build Controller
Component that manages the building of Docker images ready for deployment
Deployment Controller
Component that manages the deployment of Dockerimages to pods on nodes in the cluster
Image Stream
A set references to other images (and/or image streams). This provides a virtual view of related images, which allow operational control of events when any of the referenced image (and/or image streams) are changed. These events might trigger a rebuild or redeployment of a build.
Route
A DNS-resolveable endpoint that maps to an ip address and port
Image Stream Tag
Image Streams can be tagged in a similar way to Docker image tags
Docker vs Kubernetes vs OpenShift
Docker
Kubernetes
OpenShift
Cluster
A cluster is a set of Nodes that run Docker Swarm
A Kubernetes Cluster is a set of masternodes and minions
An OpenShift Cluster is a set of OpenShift ‘master nodes’ plus a set of OpenShift nodes
Label
Name value pair applied to an object, eg an image or container
Name value pair applied to an object, eg pod or node
Name value pair applied to an object, eg route
Master
The Swarm Node acting as the elected master
The node or nodes that act as the cluster master, keeping track of centralised information using etcd nodes
The node or nodes that act as the cluster master, keeping track of centralised information using etcd nodes
Minion
N/A
Node on which Pods can be run
Rarely used, but would correspond to an OpenShift Node
Namespace
Kernel facility to allocate an isolated instance of a global resource, eg filesystem or network. Docker is partly a product that orchestrates these isolated components in a consumable way
Isolated sets of resources for management purposes
Isolated sets of resources for management purposes
Node
A host within a Swarmcluster
A host within a Kubernetes cluster
A host within an OpenShift cluster
Project
N/A
N/A
Extension of Kubernetes’ namespace concept with the addition of RBAC etc.
Service
Stable endpoint that forwards requests to (transient) containers
Stable endpoint that forwards requests to (transient) pods
Stable endpoint that forwards requests to (transient) pods