Writing a Technical Book
It’s over!
Seventeen months after signing the contract, I hold our book in my hands!

A lot of people have asked me about our experiences writing the book, whether it was ‘worth it’, how much work it was, whether I’d do it again, and should they do one.
I remember googling this before I started, so thought it would be good to pay forward my experiences for the benefit of others.
Why write a book?
It’s good to think about why you want to write a book before starting. Reasons include:
- Vanity
- Recognition
- Money
- Career development
- Communicating your ideas
- Learning about the technology!
None of these are good or bad reasons in themselves.
Vanity and recognition (seeing your name in print, being able to put ‘published author’ on your LinkedIn profile, being able to say ‘I’ve published a book on that’) can be a great motivator to keep going when things get tough, however shallow.
We all need money to live, but it’s no secret that writing a book will not make you rich. That doesn’t mean there aren’t material benefits though! You will get paid if it sells, but it’s not going to be enough in itself to make the hardship worthwhile, and will never be guaranteed. If you want money, market yourself as a consultant and make real money faster.
Secondary Benefits
The secondary benefits are where writing a book really excels. These can include:
- Conference invites
- Professional respect
- Improved networking
- Career enhancement
In a way, writing a book is like joining a professional club. The editor that persuaded me to write said ‘writing a book will put you into a different professional category’ and that has certainly been my experience.
Conferences can be fun, and you will come into contact with lots of people you would not normally meet. You can also validate your ideas while you write the book.
Learning
Whisper it, but writing a book will force you into corners of the technology you might not otherwise look into. In other words, you learn about it! I thought I knew a lot about Docker before I started, but writing a book forced me to up my game. Nothing focusses the mind like knowing that another ‘expert’ will be paid to go over your book with a fine-toothed comb and write brutal feedback!
As another secondary benefit, when you write a book, people ask you questions – a valuable way to gain intelligence about what’s going on in the field!
Communicating your ideas
A book is a great mouthpiece for you. You can take the time to give the benefits of your experience.
For us, we wanted to give the real picture about Docker for engineers. Having spent many months getting it to useful in our business, we felt that a lot of the rhetoric around Docker was misleadingly idealistic, and were keen to make engineers feel OK about compromises they might have to make for their business.
What you will need
A plan
Publishers want to know this before taking you on as an author:
- You know what you’re talking about
- You have a strong idea what you want to write about
- You are committed to completing the work
- You are able and want to communicate
Have a table of contents prepared. Don’t worry if it’s not perfect, the fact that you have something will put you far ahead of the competition, and help convince the publisher you’re serious. They will help you improve it anyway.
This will change a lot as you write, but by knowing the shape of the book in advance – and knowing what you want to say – you will save a lot of time and effort.
I started by giving talks at meetups, which I highly recommend for all sorts of reasons, but having a video of me communicating to my peers ticked a lot of these boxes for my publisher.
A good publisher
Get a good publisher. It’s worth far more than a few percent more on the book’s sales.
A good publisher provides:
- Planning, support and advice
- Editing expertise and mentoring
- Proof-reading iterations
- Technical proofreading
- Peer review
- Marketing
- Indexing
- Illustration
- Layout
- Printing
- Distribution
- Branding
That’s quite a list! You can self-publish if you want, and you will make a bigger cut, but you will have to do a lot more work to sell each copy.

Maybe the time will come that I write ‘SLAVE’ on my face, but I can always self-publish at that point and save on marker pen ink.
In fact, I had a look at some self-published technical books in preparation for this article, and could very quickly see flaws not in content but definitely in copy, approach, style and design. All things the Manning team saved me from.
I have nothing but good things to say about the team at Manning, who had a very efficient team which supported and pushed us to make a better (and a better-selling) book. And we learned a lot about the publishing industry through writing it.
For example, about 20% of the writing time was spent getting the first chapter right. We went over it again and again until we’d learned the lessons we needed to. After that, the subsequent chapters came out pretty easily.
Time and space
It’s no surprise that writing book is time-consuming, but there are some subtleties beyond this to consider.
Simply taking 30 minutes every day to ‘work on the book’ is not enough. That will work for writing linking snippets or bits of proofing or testing, but will need stretches of many hours to do the real meat of the work. I would take myself off to the libraries for many stretches to focus on sections of the book that required real thought.
For example, I spent more time than I care to relate trying to get Kubernetes set up at home when it was still in its infancy. In retrospect this was a massive waste of time! But quite valuable in other ways – I learned a lot about the product, and even got into contact with the lead Kubernetes developer.
I was lucky in that I had two months between jobs, so I wrote and explored London, which was a fantastic life experience and a lot of fun. If I were to write a book again I would probably quit work and devote myself to it full-time. It’s less profitable, but getting the focus full-time would make life a lot easier and fun.
Get a co-author
I would seriously recommend getting a co-author. The benefits are numerous:
- Sanity check on content and direction
- 50% of the work is taken off your hands
- You still retain control where you want it
But not at any cost. I was lucky with my co-author – the work divided up nicely between us, and our skills complemented each other nicely. If you don’t trust someone, don’t sign up with them, as the process can get stressful if you let it.
I would have to think very carefully about going through this process again on my own.
Ability to write (and draw!)
Sounds obvious, but you will need to be able to write. I was lucky that I’d had some professional writing experience, but when you write in a commercial niche there’s more to learn about what works and what doesn’t.
If you can’t write already, be prepared to listen and learn. A good editor will give robust feedback, and tell you clearly where you need to improve.
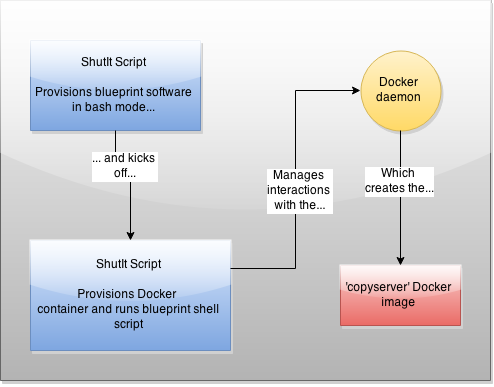
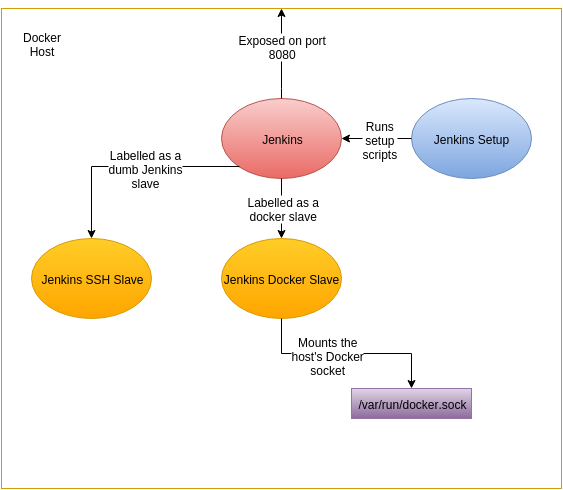
And get good at doing diagrams. They don’t need to be polished, but diagrams are increasingly important in successful technical books.
When you see tweets like this it makes it all that effort worthwhile.
Ability to market
Although publishers provide marketing for you, you should be willing to work on this side of things as well. You should know what topics are of interest to people, and the marketing team will be very grateful if you feed them useful content.
Still want to do it?
Feel free to contact me if you want more advice or have any questions!
This post is about my book Docker in Practice
May 16th 2016 Deal of the Day – 50% off!

Get 39% off with the code: 39miell