You’re a few years into your tenure as CEO of a Vandelay Industries, a behemoth in the Transpondsting space that’s existed for many decades.
The Real Strategy
You could really use the share price to go up soon so you can and sell your shares at the optimal point before fortune’s wheel turns and the board inevitably get rid of you.
You’re tired of Vandelay, and want to move to a better CEO job or maybe a nice juicy Chairmanship of another behemoth board before the share price drops.
What happens to Vandelay after you’re gone is not your problem. In fact, as you are likely to go and work for a rival corporation, it might even be better if things were worse at Vandelay once you’ve sold your shares than better.
Any means necessary are on the table.
Fortunately the solution to this problem is simple:
Declare a major technology transformation!
Why? Wall Street will love it. They love macho ‘transformations’. By sheer executive fiat Things Will Change, for sure.
Throw in ‘technology’ and it makes Wall Street puff up that little bit more.
The fact that virtually no analyst or serious buyer of stocks has the first idea of what’s involved in such a transformation is irrelevant. They will lap it up.
This is how capitalism works, and it indisputably results in the most efficient allocation of resources possible.
A Dash of Layoffs, a Sprinkling of Talent
These analysts and buyers will assume there will be reductions to employee headcount sooner rather than later, which of course will make the transformation go faster and beat a quick path to profit.
Hires of top ‘industry experts’ who know the magic needed to get all this done, and who will be able to pass on their wisdom without friction to the eager staff that remain, will make this a sure thing.
In the end, of course, you don’t want to come out of this looking too bad, do you?
So how best to minimise any fallout from this endeavour?
Leadership
The first thing you should do is sort out the leadership of this transformation.
Hire in a senior executive specifically for the purpose of making this transformation happen.
Well, taking responsibility for it, at least. This will be useful later when you need a scapegoat for failure.
Ideally it will be someone with a long resume of similar transformational senior roles at different global enterprises.
Don’t be concerned with whether those previous roles actually resulted in any lasting change or business success; that’s not the point. The point is that they have a lot of experience with this kind of role, and will know how to be the patsy. Or you can get someone that has Dunning-Kruger syndrome so they can truly inhabit the role.
Make sure this executive is adept at managing his (also hired-in) subordinates in a divide-and-conquer way, so their aims are never aligned, or multiply-aligned in diverse directions in a 4-dimensional ball of wool.
Incentivise senior leadership to grow their teams rather than fulfil the overall goal of the program (ideally, the overall goal will never be clearly stated by anyone – see Strategy, below).
Change your CIO halfway through the transformation. The resulting confusion and political changes of direction will ensure millions are lost as both teams and leadership chop and change positions.
With a bit of luck, there’ll be so little direction that the core business can be unaffected.
Strategy
This second one is easy enough. Don’t have a strategy. Then you can chop and change plans as you go without any kind of overall direction, ensuring (along with the leadership anarchy above) that nothing will ever get done.
Unfortunately, the world is not sympathetic to this reality, so you will have to pretend to have a strategy, at the very least. Make the core PowerPoint really dense and opaque. Include as many buzzwords as possible – if enough are included people will assume you know what you are doing. It helps if the buzzwords directly contradict the content of the strategy documents.
It’s also essential that the strategy makes no mention of the ‘customer’, or whatever provides Vandelay’s revenue, or why the changes proposed make any difference to the business at all. That will help nicely reduce any sense of urgency to the whole process.
Try to make any stated strategy:
hopelessly optimistic (set ridiculous and arbitrary deadlines)
inflexible from the start (aka ‘my way, or the highway’)
Whatever strategy you pretend to pursue, be sure to make it ‘Go big, go early’, so you can waste as much money as fast as possible. Don’t waste precious time learning about how change can get done in your context. Remember, this needs to fail once you’re gone.
Technology Architecture
First, set up a completely greenfield ‘Transformation Team’ separate from your existing staff. Then, task them with solving every possible problem in your business at once. Throw in some that don’t exist yet too, if you like! Force them to coordinate tightly with every other team and fulfil all their wishes.
Ensure your security and control functions are separated from (and, ideally, in some kind of war with) a Transformation Team that is siloed as far as possible from the mainstream of the business. This will create the perfect environment for expensive white elephants to be built that no-one will use.
All this taken together will ensure that the Transformation Team’s plans have as little chance of getting to production as possible. Don’t give security and control functions any responsibility or reward for delivery, just reward them for blocking change.
Ignore the ‘decagon of despair’. These things are nothing to do with Transformation, they are just blockers people like to talk about. The official line is that hiring Talent (see below) will take care of those. It’s easy to exploit an organisation’s insecurity about its capabilities to downplay the importance of these
The decagon of despair.
Talent
Hire hundreds of very expensive engineers and architects who don’t understand the business context. Do this before you’ve even established a clear architecture (which will never be defined) for your overall goals (which are never clearly articulated).
Give these employees no clear leadership, and encourage them to argue with each other (and everyone else, should they happen to come across them) about minor academic details of software development and delivery, thus ensuring that no actual delivery is in danger of happening.
Just let them get on with it.
Endgame
If all goes to plan, the initiative peaks at around 18 months in. The plan is in full swing and analysts are expecting benefits to show in the bottom line in the upcoming reports. Fortunately, you’ve done the groundwork, and internally, everyone can see it’s a mess.
People are starting to ask questions about the lack of results. The promised benefits have not arrived, and costs seem to be spiralling out of control. The faction for change you encouraged is now on the defensive in senior meetings, and the cultural immune system of the old guard is kicking in again, reasserting its control.
It’s now time for you to protest that everything is going to plan, but gracefully accept your fate and your juicy payoff. If you’ve still not got enough cash to be happy, then you can go to LandervayIndustries, and use your hard-won experience there to help them turn their business around. Maybe this time it will work, as your main competition (Vandelay) seems to be struggling since you left…
How many times have you sat there trying to work through a technical problem, and thought:
Is it OK if I interrupt someone else to get them to help me?
Pretty much every engineer ever
Since I work with companies that are in the process of moving to Cloud Native technologies, there is often a huge gulf in knowledge and experience between the ‘early adopters’/’pioneers’ and the rest of the organisation.
Bridging that gap is a very costly process involving a combination of approaches such as formal training, technical mentoring, gentle cajoling, and internal documentation.
Very commonly, the more junior technical staff are very wary of interrupting their more senior colleagues, whose time is perceived as more valuable, and whose knowledge and experience can inhibit them from seeking help.
The Problem
Most of the time this isn’t a huge problem, as engineers negotiate between them when it’s OK to interrupt by observing how often others do it, developing good relationships with their peers, and so on.
It becomes a problem when people are unable to feel safe to interrupt others. This might be because:
They feel ‘left out’ of the team
They feel like they ‘should’ be able to solve the problem themselves
Of course, all of these reasons are related reasons to do with psychological safety, so often cited as a core characteristic of high-performing teams. This article can’t solve that problem, but seeks to help with one aspect of it. If you have rules around when and how it’s ‘OK’ to ask for help, it can make you safer about seeking it.
If people feel unable to ask for help, they can (at the worst extremes) sit there sweating for days making no progress, while feeling under enormous stress about their work. At the other end, you can get employees that ask for help after getting stuck immediately, wasting others’ time as they have to explain their problem to someone, and very often fixing the problem themselves as they talk.
The Rule of Thumb
Early in my career, the first consultancy I worked with had a really simple rule for this:
If you’re stuck for over an hour, seek help.
This beautifully simple rule works very well in most contexts. It stops people sitting on blockages for days, and stops them from jumping out of their seat early in a panic.
A further piece of advice which I add to this is:
When you seek advice, first write down everything you’ve tried.
This has at least three benefits:
It acts as a form ofrubber duck debugging. Very often, in the process of taking a step back and writing down what you’ve tried, you’ll see what you missed.
When you go to get help, you have evidence that you’ve gone through some kind of structured thought process before raising the alarm, rather than just asking for help as soon as the going got tough.
You will save time explaining the context to someone else you’ve forced to context switch.
An essay is not required. Just enough notes to explain clearly and concisely what problem you’re facing and what your thinking was about how to solve it.
The Formula
The rule of thumb is simple and useful, but there’s other factors to consider if you want to get really scientific about when and how it’s OK to interrupt others. If you’re in the business of knowledge work, every time you interrupt someone you reduce their efficiency, and cost your business money.
Bosses are notorious for being cavalier with their inferiors’ time, but there’s often a good justification for this: their time is worth more to the business than yours.
So I came up with a formula for this, embodied in this spreadsheet.
The formula takes in a few parameters:
‘Time taken thus far’ (ie how much time you’ve spent stuck on the problem) (“T3F”)
Time it will take to explain to someone else (“T3E”)
The ‘interruption overhead’ to the interruptee (“IO”)
The relative worth of your time and the interruptee’s time (“RTW”)
and tells you whether it’s ok to interrupt, as well as how much time you should still spend looking at it before interrupting. The interesting extra parameter here is the ‘relative cost’ of your time to the interruptee’s. This will be difficult to estimate accurately, but it can be set by the more senior staff as a guide to when they want to get involved in a problem. The last thing a more senior engineer should want is for their juniors to be spending significant amounts of time neither solving the problem nor developing their knowledge and capabilities.
The formula, for those interested is:
Interrupt if:
T3F > RTW (IO + T3E)
If you use it, let me know!
If you enjoyed this, then please consider buying me a coffee to encourage me to do more.
Like many self-confessed geeks, I’ve long been curious about 3d-printing. To me, it sounds like the romantic early days of home computing in the 70s, where expensive machines that easily broke and were used as toys gradually gave way to more reliable and useful devices that became mainstream twenty years later.
The combination of a few factors led me to want to give it a go: needing a hobby in lockdown; teenage kids who might take to it (and were definitely interested); a colleague who had more experience with it; and the continuing drop in prices and relative maturity of the machines.
Going into this, I knew nothing about the details or the initial difficulties, so I wanted to blog about it before I forget about them or think that they are ‘obvious’ to everyone else. Plenty wasn’t obvious to me…
Reading Up And Choosing A Printer
I started by trying to do research on what kind of printer I wanted, and quickly got lost in a sea of technical terms I didn’t understand, and conflicting advice on forums. The choices were utterly bewildering, so I turned to my colleague for advice. The gist of what he told me was: ‘Just pick one you can afford that seems popular and go for it. You will learn as you go. Be prepared for it to break and be a general PITA.’
So I took his advice. I read somewhere that resin printers were far more detailed, and got advice from another former colleague on the reputable brands, held my nose and dove in. I plumped for the Elegoo Mars 2, as it was one of the recommendations, and it arrived a few days later, along with a bottle of resin. Machine + resin was about £230.
Setup
I won’t say setup was a breeze, but I imagine it was a lot slicker than it was in the really early days of home 3d printing. I didn’t have to construct the entire thing, and the build quality looked good to me.
The major difficulties I had during setup were:
Not realising I needed to wash the print in IPA (Isopropyl Alcohol, 90%+), surgical gloves (washing up gloves won’t cut it), and a mask. The people that inhabit 3d printing forums seemed to think it was trivial to get hold of gallons of it from local hardware stores, but all I could find was a surprisingly expensive 250ml bottle for £10 in a local hardware shop (the third I tried). Three pairs of gloves are supplied
Cack-handedly dropping a screw into the resin vat (not recommended) and having to fish it out.
Not following the instructions on ‘levelling the plate’ (the print starts by sticking resin to the metal printing plate, so it has to be very accurately positioned) to the absolute letter. The instructions weren’t written by a native speaker and also weren’t clearly laid out (that’s my excuse).
I also wasn’t aware that 3d-printing liquid resin is an unsafe substance (hence the gloves and mask), and that the 3d printing process produces quite a strong smell. My wife wasn’t particularly happy about this news, so I then did a lot of research to work out how to ensure it was safe. This was also bewildering, as you get everything from health horror stories to “it’s fine” reassurance.
In the event it seems like it’s fine, as long as you keep a window open whenever the printing lid is off and for a decent time after (30 mins+). It helps if you don’t print all day every day. The smelliest thing is the IPA, which isn’t as toxic as the resin, so as long as you keep the lid on wherever possible any danger is significantly reduced. If you do the odd print every other day, it’s pretty safe as far as I can tell. (This is not medical advice: IANAD). A far greater risk, it seems, is getting resin on your hands.
Thankfully also, the smell is not that unpleasant. It’s apparently the same as a ‘new car’ smell (which, by the way, is apparently horrifyingly toxic – I’ll always be opening a window when I’m in a new car in future).
Unlike the early days of computing, we have youtube, and I thoroughly recommend watching videos of setups before embarking on it yourself.
Finally, resin disposal is something you should be careful about. It’s irresponsible to pour resin down the drain, so don’t do it. Resin hardens in UV light (that’s how the curing/hardening process works), so there’s plenty of advice on how to dispose of it safely.
First Print
The first prints (which come on the supplied USB stick) worked first time, which was a huge relief. (Again, online horror stories of failed machines abound.)
The prints themselves were great little pieces themselves, a so-called ‘torture test’ for the printer to put it through its paces. A pair of rooks with intricate staircases inside and minute but legible lettering. The kids immediately claimed them as soon as I’d washed them in alcohol and water, before I had the time to properly cure them.
I didn’t know what curing was at the time, and had just read that it was a required part of the process. I was confused because I’d read it was a UV process, but since the machine worked by UV I figured that the capability to cure came with the machine. Wrong! So I’d need a source of UV light, which I figured daylight would provide.
I tried leaving the pieces outside for a few hours, but I had no idea when they would be considered done, or even ‘over-cured’, which is apparently a thing. In the end I caved and bought a curing machine for £60 that gave me peace of mind.
From here I printed something for the kids. The first print proper:
Darth Buddha, First Print for my Kids
I’d decided to ‘hollow out’ this figure, to reduce the cost of the resin. I think it was hollowed to 2mm, and worked out pretty well. One downside was that the base came away slightly at the bottom, suggesting I’d hollowed it out too much. In any case, the final result has pride of place next to the Xbox.
More Prints
Next was for me, an Escher painting I particularly like (supposedly the figure in the reality/gallery world is Wittgenstein):
MC Escher’s ‘Print Gallery’ Etched in 3-D
You can see that there are whiter, chalkier bits. I think this is something to do with some kind of failure in my washing/curing process combined with the delicacy of the print, but I haven’t worked out what yet.
And one for my daughter (she’s into Death Note):
And another for me – a 3D map of the City of London:
A 3D Map of the City of London
The Paraphernalia Spreads…
Another echo of the golden age of home computing is the way the paraphernalia around the machine gradually grows. The ‘lab’ quickly started to look like this:
The Paraphernalia Spreads…
Alongside the machine itself, you can also see the tray, tissue paper, bottles (IPA and resin), curing station, gloves, masks, tools, various tupperware containers, and a USB stick.
It helps if you have a garage, or somewhere to spread out to that other people don’t use during the day.
After a failed print (an elephant phone holder for my mother), which sagged halfway through on the plate, the subsequent attempts to print were marked by what sounded like a grinding noise of the plate against the resin vat. It was as though the plate tried to keep going through the vat to the floor of the machine.
I looked up this problem online, and found all sorts of potential causes, and no easy fix. Some fixes talked about attaching ‘spacers’ (?) to some obscure part of the machine. Others talked about upgrading the firmware, and even a ‘factory’. Frustrated with this, I left it alone for a couple of weeks. After re-levelling the plate a couple of times (a PITA, as the vat needed to be carefully removes, gloves and mask on etc), it occurred to me one morning that maybe some hardened material had fallen into the resin vat and that that was what the plate was ‘grinding’ on.
I drained the vat, which was a royal PITA the first time I did it, as my ineptitude resulted in spilled resin due to the mismatch between bottle size and resin filter (the supplied little resin jug is also way to small for purpose). But it was successful, as there were bits caught in the filter, and after re-filling the vat I was happily printing again.
Disaster Two
Excited that I hadn’t spent well north of £200 on a white elephant, I went to print another few things. Now the prints were failing to attach to the plate, meaning that nothing was being printed at all. A little research again, and another draining of the vat later I realised the problem: the plate hadn’t attached to the print, but the base of the print had attached to the film at the bottom of the vat. This must be a common problem, as a plastic wedge is provided for exactly this purpose. It wasn’t too difficult to prise the flat hardened piece of resin off the floor of the vat and get going again.
Talking to my colleague I was told that ‘two early disasters overcome is pretty good going so far’ for 3d printing.
We’re Back
So I was back in business. And I could get back to my original intention to print architectural wonders (history of architecture is an interest of mine). Here’s a nice one of Notre Dame.
Conclusion
When 3d printing works, it’s a joy. There is something magical about creating something so refined out of a smelly liquid.
When it doesn’t work it’s very frustrating. Like speculating on shares, I would only spend money on it you can afford to lose. And like any kind of building, don’t expect the spending to stop on the initial materials.
I think this is the closest I’ll get to the feeling of having one of these in 1975 (the year I was born).
The Altair 8800 Home PC
It’s also fun to speculate on what home 3d printing will look like in 45 years…
GitOps is the latest hotness in the software delivery space, following (and extending) on older trends such as DevOps, infrastructure as code, and CI/CD.
So you’ve read up on GitOps, you’re bought in to it, and you decide to roll it out.
This is where the fun starts. While the benefits of GitOps are very easy to identify:
Fully audited changes for free
Continuous integration and delivery
Better control over change management
The possibility of replacing the joys of ServiceNow with pull requests
the reality is that constructing your GitOps pipelines is far from trivial, and involves many big and small decisions that add up to a lot of work to implement as you potentially chop and change as you go. We at Container Solutions call this ‘GitOps Architecture’ and it can result in real challenges in implementation.
The good news is that with a bit of planning and experience you can significantly reduce the pain involved in the transition to a GitOps delivery paradigm.
In this article, I want to illustrate some of these challenges by telling the story of a company that adopts GitOps as a small scrappy startup, and grows to a regulated multinational enterprise. While such accelerated growth is rare, it does reflect the experience of many teams in larger organisations as they move from proof of concept, to minimum viable product, to mature system.
‘Naive’ Startup
If you’re just starting out, the simplest thing to do is create a single Git repository with all your needed code in it. This might include:
Terraform code to provision resources needed to run the application
All changes directly made to master, changes go straight to live
The main benefits of this approach are that you have a single point of reference, and tight integration of all your code. If all your developers are fully trusted, and shipping speed is everything then this might work for a while.
Unfortunately, pretty quickly the downsides of this approach start to show as your business starts to grow.
First, the ballooning size of the repository as more and more code gets added can result in confusion among engineers as they come across more clashes between their changes. If the team grows significantly, then a lot of rebasing and merging can result in confusion and frustration.
Second, you can run into difficulties if you need to separate control or cadence of pipeline runs. Sometimes you just want to quickly test a change to the code, not deploy to live, or do a complete build and run of the end-to-end delivery.
Increasingly the monolithic aspect of this approach creates more and more problems that need to be worked on, potentially impacting others’ work as these changes are worked through.
Third, as you grow you may want more fine-grained responsibility boundaries between engineers and/or teams. While this can be achieved with a single repo (newer features like CODEOWNERS files can make this pretty sophisticated), a repository is often a clearer and cleaner boundary.
Repository Separation
It’s getting heavy. Pipelines are crowded and merges are becoming painful. Your teams are separating and specialising in terms of their responsibility.
So you decide to separate repositories out. This is where you’re first faced with a mountain of decisions to make. What is the right level of separation for repositories? Do you have one repository for application code? Seems sensible, right? And include the Docker build stuff in there with it? Well, there’s not much point separating that.
What about all the team Terraform code? Should that be in one new repository? That sounds sensible. But, oh: the newly-created central ‘platform’ team wants to control access to the core IAM rule definitions in AWS, and the teams’ RDS provisioning code is in there as well, which the development team want to regularly tweak.
So you decide to separate out the Terraform out into two repos: a ‘platform’ one and an ‘application-specific’ one. This creates another challenge, as you now need to separate out the Terraform state files. Not an insurmountable problem, but this isn’t the fast feature delivery you’re used to, so your product manager is now going to have to explain why feature requests are taking longer than previously because of these shenanigans. Maybe you should have thought about this more in advance…
Unfortunately there’s no established best practice or patterns for these GitOps decisions yet. Even if there were, people love to argue about them anyway, so getting consensus may still be difficult.
The problems of separation don’t end there. Whereas before, co-ordination between components of the build within the pipeline were trivial, as everything was co-located, now you have to orchestrate information flow between repositories. For example, when a new Docker image is built, this may need to trigger a deployment in a centralised platform repository along with passing over the new image name as part of that trigger.
Again, these are not insurmountable engineering challenges, but they’re easier to implement earlier on in the construction of your GitOps pipeline when you have space to experiment than later on when you don’t.
OK, your business is growing, and you’re building more and more applications and services. It increasingly becomes clear that you need some kind of consistency in structure in terms of how applications are built and deployed. The central platform team tries to start enforcing these standards. Now you get pushback from the development teams who say they were promised more autonomy and control than they had in the ‘bad old days’ of centralised IT before DevOps and GitOps.
If these kind of challenges ring bells in readers’ heads it may be because there is an analogy here between GitOps and monolith vs microservices arguments in the application architecture space. Just as you see in those arguments, the tension between distributed and centralised responsibility rears its head more and more as the system matures and grows in size and scope.
On one level, your GitOps flow is just like any other distributed system where poking one part of it may have effects not clearly understood, if you don’t design it well.
I'll just make a small change to one of the repos in my GitOps setup. It'll be fine. pic.twitter.com/dhIRGYN5NX
At about the same time as you decide to separate repositories, you realise that you need a consistent way to manage different deployment environments. Going straight to live no longer cuts it, as a series of outages has helped birth a QA team who want to test changes before they go out.
Now you need to specify a different Docker tag for your application in ‘test’ and ‘QA’ environments. You might also want different instance sizes or replication features enabled in different environments. How do you manage the configuration of these different environments in source? A naive way to do this might be to have a separate Git repository per environment (eg superapp-dev, super-app-qa, super-app-live).
Separating repositories has the ‘clear separation’ benefit that we saw with dividing up the Terraform code above. However, few end up liking this solution, as it can require a level of Git knowledge and discipline most teams don’t have in order to port changes between repositories with potentially differing histories. There will necessarily be a lot of duplicated code between the repositories, and – over time – potentially a lot of drift too.
If you want to keep things to a single repo you have (at least) three options:
A directory per environment
A branch per environment
A tag per environment
Sync Step Choices
If you rely heavily on a YAML generator or templating tool, then you will likely be nudged more towards one or other choice. Kustomize, for example, strongly encourages a directory-based separation of environments. If you’re using raw yaml, then a branch or tagging approach might make you more comfortable. If you have experience with your CI tool in using one or other approach previously in your operations, then you are more likely to prefer that approach. Whichever choice you make, prepare yourself for much angst and discussion about whether you’ve chosen the right path.
Runtime Environment Granularity
Also on the subject of runtime environments, there are choices to be made on what level of separation you want. On the cluster level, if you’re using Kubernetes, you can choose between:
One cluster to rule them all
A cluster per environment
A cluster per team
At one extreme, you can put all your environments into one cluster. Usually, there is at least a separate cluster for production in most organisations.
Once you’ve figured out your cluster policy, at the namespace level, you can still choose between:
A namespace per environment
A namespace per application/service
A namespace per engineer
A namespace per build
Platform teams often start with a ‘dev’, ‘test’, ‘prod’ namespace setup, before realising they want more granular separation of teams’ work.
You can also mix and match these options, for example offering each engineer their own namespace for ‘desk testing’, as well as a namespace per team if you want.
Conclusion
We’ve only scratched the surface here of the areas of decision-making required to get a mature GitOps flow going. You might also consider RBAC/IAM and onboarding, for example, an absolute requirement if you grow to become that multinational enterprise.
Often rolling out GitOps can feel like a lot of front-loaded work and investment, until you realise that before you did this none of it was encoded at all. Before GitOps, chaos and delays ensued as no-one could be sure in what state anything was, or should be. These resulted in secondary costs as auditors did spot checks and outages caused by unexpected and unrecorded changes occupied your most expensive employees’ attention. As you mature your GitOps flow, the benefits multiply, and your process takes care of many of these challenges. But more often than not, you are under pressure to demonstrate success more quickly than you can build a stable framework.
The biggest challenge with GitOps right now is that there are no established patterns to guide you in your choices. As consultants, we’re often acting as sherpas, guiding teams towards finding the best solutions for them and nudging them in certain directions based on our experience.
What I’ve observed, though, is that choices avoided early on because they seem ‘too complicated’ are often regretted later. But I don’t want to say that that means you should jump straight to a namespace per build, and a Kubernetes cluster per team, for two reasons.
1) Every time you add complexity to your GitOps architecture, you will end up adding to the cost and time to deliver a working GitOps solution.
2) You might genuinely never need that setup anyway.
Until we have genuine standards in this space, getting your GitOps architecture right will always be an art rather than a science.
Recently, while showing someone at work a useful Git ‘trick’, I was asked “how many ways are there to undo a bad change in Git?”. This got me thinking, and I came up with a walkthrough similar to the ones I use in my book to help embed key Git concepts and principles.
There’s many ways to achieve the result you might want, so this can be a pretty instructive and fertile question to answer.
If you want to follow along, run these commands to set up a simple series of changes to a git repository:
cd $(mktemp -d)
git init
for i in $(seq 1 10)
do
echo "Change $i" >> file
git add file
git commit -m "C${i}"
done
Now you are in a fresh folder with a git repository that has 10 simple changes to a single file (called ‘file') in it. If you run:
git log --oneline --graph --all
at any point in this walkthrough you should be able to see what’s going on.
See here if you want to know more about this git log command.
1) Manual Reversion
The simplest way (conceptually, at least) to undo a change is to add a new commit that just reverses the change you last made.
First, you need to see exactly what the change was. The ‘git show‘ command can give you this:
git show HEAD
The output should show you a diff of what changed in the last entry. The HEAD tag always points to a specific commit. If you haven’t done any funny business on your repo then it points to the last commit on the branch you are working on.
Next, you apply the changes by hand, or you can run this command (which effectively removes the last line of the file) to achieve the same result in this particular context only:
head -9 file > file2
mv file2 file
and then commit the change:
git commit -am 'Revert C10 manually'
2) git revert
Sometimes the manual approach is not easy to achieve, or you want to revert a specific commit (ie not the previous one on your branch). Let’s say we want to reverse the last-but-two commit on our branch (ie the one that added ‘Change 9‘ to the file).
First we use the git rev-list command to list the previous changes in reverse order, and capture the commit ID we want to the LASTBUTONE variable using pipes to head and tail:
and follow the instructions to commit the change. The file should now have reverted the entry for Change 9 and the last line should be Change 8. This operation is easy in this trivial example, but can get complicated if the changes are many and varied.
3) Re-point Your Branch
This method makes an assumption that you can force-push changes to remote branches. This is because it changes the history of the repository to effectively ‘forget’ about the change you just made.
In this walkthrough we don’t have a remote to push to, so it doesn’t apply.
Briefly, we’re going to:
check out the specific commit we want to return to, and
point our branch at that commit
The ‘bad commit’ is still there in our local Git repository, but it has no branch associated with it, so it ‘dangles’ off a branch until we do something with it. We’re actually going to maintain a ‘rejected-1‘ branch for that bad commit, because it’s neater.
Let’s first push a bad change we want to forget about:
Now we realise that that change was a bad one. First we make a branch from where we are, so we can more easily get back to the bad commit if we need to:
git branch rejected-1
Now let’s check out the commit before the bad one we just committed:
git checkout HEAD^
Right now you have checked out the commit you would like your master branch to be pointed at. But you likely got the scary detached HEAD message:
Note: switching to 'HEAD^'.
You are in 'detached HEAD' state. You can look around, make experimental
changes and commit them, and you can discard any commits you make in this
state without impacting any branches by switching back to a branch.
If you want to create a new branch to retain commits you create, you may
do so (now or later) by using -c with the switch command. Example:
What this means is that you are on the commit you want to be on, but are not on a branch. master is still pointed at the ‘bad’ commit. You can check this with a quick log command:
Your ‘HEAD‘ (ie, where your Git repository is right now) is pointed at the commit before the ‘bad’ one. The rejected-1 and master branches are still pointed at the ‘bad’ commit.
We want the master branch to point to where we are right now (HEAD). To do this, use git branch, but force the branching to override the error we would get because the branch already exists. This is where we start to change the Git repo’s history.
git branch -f master
The log should now show we are on the master branch:
You should be able to see now why we branched off the rejected-1 branch earlier. If we want to get back to the ‘bad’ commit, it’s easy to check out that branch. Also, the branch provides an annotation for what the commit is (ie a mistake).
We’re not finished yet, though! The commit you have checked out is now the same as the commit the master branch is on, but you still need to tell Git that you want to be on the master branch:
git checkout master
Now you have effectively un-done your change. The ‘bad’ change is safely on the rejected-1 branch, and you can continue your work as if it never happened.
Remember that if you have a remote, then you will need to force-push this change with a git push -f. In this walkthrough we don’t have a remote, so we won’t do that.
There’s a more direct way to revert your local repository to a specific commit. This also changes history, as it re-sets the branch you are one back some steps.
Let’s say we want to go back to ‘Change 8’ (with the commit message ‘C8‘).
COMMITID=$(git rev-list HEAD | head -5 | tail -1)
echo $COMMITID
Check this is the commit you want by looking at the history:
git log --oneline --graph --all
Finally, use the git reset command to . The --hard flag tells git that you don’t mind changing the history of the repository by moving the branch tip backwards.
git reset --hard "${COMMITID}"
Now your HEAD pointer and master branch are pointed at the change you wanted.
5) git rebase
This time we’re going to use git rebase to go back to ‘Change 6’. As before, you first get the relevant commit ID. Then you use the git rebase command with the -i (interactive) flag to ‘drop’ the relevant commits from your branch.
COMMITID=$(git rev-list HEAD | head -3 | tail -1)
git rebase -i "${COMMITID}"
At this point you’re prompted to decide what to do with the previous commits before continuing. Put a ‘d‘ next to the commits you want to forget about.
If you run the git log command again:
git log --oneline --graph --all
You’ll see that the commits are still there, but the master branch has been moved back to the commit you wanted:
This trick can also get you to return your branch to the initial commit without losing the other commits, which is sometimes useful:
git rebase -i $(git rev-list --max-parents=0 HEAD)
This uses the git rev-list command and --max-parents flag to give you the first commit ID in the history. Dropping all the above commits by putting ‘d‘ next to all the commits takes your branch back to the initial commit.
When I was growing up in an outer suburb of London in the 1980s, there was much talk of the decline of the city. In the future, we were told, we would all be working remotely via telescreens from our decentralised living pods.
The economics and technology of the argument seemed solid. The Internet was coming up in earnest (from 1990), and we wouldn’t need to be near each other anymore to do our jobs. In the event, that didn’t happen, and property prices in London rose dramatically as people clustered to where the jobs were in the later 90s, the noughties, and up until 2020.
COVID, of course, has changed all that.
In this article, I want to take a peek into the future and speculate on what will be the medium term effect on London of the systemic shock COVID has brought to our working practices and assumptions.
Here’s the flow of the analysis:
Working from home is now a thing
50% of office space is not needed
How much office/residential/retail space is there?
How long will this take?
Skip to ‘Consequences‘ below if you’re not interested in the analysis.
Working From Home Is Definitely Now A Thing
There’s no doubt that WFH is now a proven model for working. Whatever objections existed in the past (and difficulty was had negotiating it) few businesses now think that having everyone in the office all the time is essential or even desirable for their bottom line. Most managers used to furrow their brow if someone wanted to WFH and grudgingly offer it as a ‘perk’, and maybe let them WFH for one day a week. Pre 2020, a few plucky businesses (normally startups or smaller tech firms) offered or embraced remote working, but these were a relatively low proportion of all businesses or workers in the economy.
But right now, many companies are effectively operating as distributed businesses that telecommute. Many reports say that office workers will not return until 2021. And when they do, their habits will have ineradicably altered.
But there’s also no doubt WFH is not for everyone all of the time. Many people want or even need the physical social contact that work gives them. On the other hand, CFOs across the capital must be looking at their operating costs and wondering by what percentage they can be cut.
So the question arises: how much less office space can people use and still be productive and content? Right now I would estimate we are at near 80% of office space going unused in central London (I work alone from an office in Central London at the moment (July 2020), and apart from construction and security workers, it’s eerily quiet here).
I’m going to take a guess here and say that businesses – on average – will be planning to cut 50% of office space. Some people will go back full time, some people will come in for a few days a fortnight, and some will come in rarely (if at all). On the other hand, extra space may be be needed to maintain safety from next year. Fifty percent seems a reasonable estimate. It’s also backed up by anecdotal stories coming from the City:
“If we have learned nothing we have learned that 40-50% of staff can work from home. For the time being some leases are long but there should be plenty of room if only 50% of the staff are present every day, without requiring extra space.” Source
How Much Office Space Is There?
What does 50% less office space utilisation actually mean for London? How significant is this, historically?
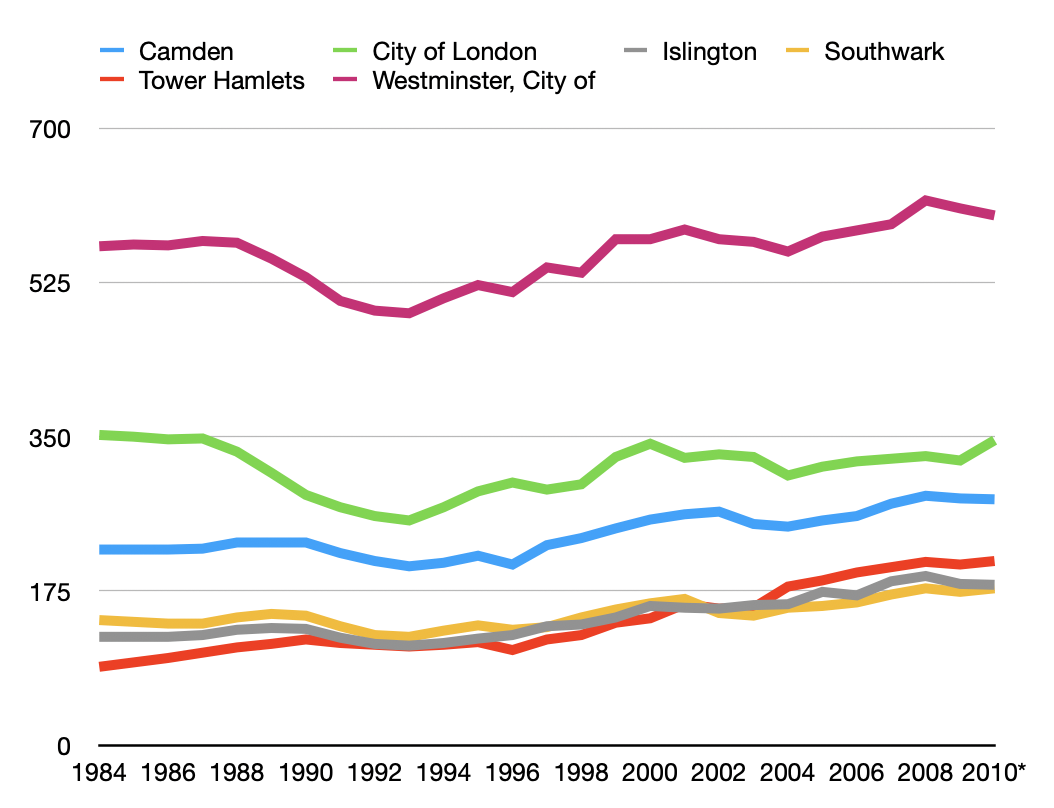
Firstly, I’m going to look at office space in Central London. The best figures I could find were here, from 2012.
Borough
Square metres
Square feet
Westminster
5,373,000
57,800,000
The City
5,000,000
53,800,000
Tower Hamlets
2,458,000
26,400,000
Camden
2,137,000
23,000,000
Islington
1,455,000
15,700,000
Southwark
1,270,000
13,700,000
TOTAL
17,693,000
190,376,680
Central London Office Space by Borough, 2012. Source
There was 190m sq ft of office space in these central boroughs in 2012. This source suggests that this doesn’t move much every year, (some 800,000 sq feet of space was converted to residential, but new offices are also being built) so if it has moved since, it would be in the low millions. Other sources suggest that the change in office space was roughly +1% per year between 2000 and 2012
So let’s assume we lose the need for around 90-100m sq ft of space. What do these figures mean, in a historical context?
This source tells us the number of jobs per London borough between 1984 and 2010. Usefully, in the middle of this was a large recession which reached its nadir in 1993.
Number of jobs (000s) per borough 1984-2010. Source
A quick look at the numbers for the City of London tells us that the peak (2010) to trough of jobs (1993) in town was about 20%. So a big recession (the 90s was a pretty big one) resulted in 20% fewer people working in town.
The effect of a 50% reduction is therefore utterly seismic. We’re in uncharted territory.
I don’t know how far you’d have to go back to get back to those levels. Leaving the war aside, maybe the 1950s had similar levels of people working in London then? Before that, you’d have to go back to times when horses were the main means of transport in London, which was effectively a different world.
How Much Household Space Is There?
So if half the office space is no longer needed, can this space be converted into residential property?
To figure this out, we need to know:
How many Central London households are there?
How big is the ‘typical’ Central London household?
Central London households by Borough, 2012. Source
We have 587,100 households. The median household size (based on a Rightmove search of EC1 + 1 mile) is two bedrooms.
Bedrooms
Number for sale
Studio
187
1
944
2
1306
3
554
4
77
5+
36
EC1 + 1 mile search on Rightmove
The average size of a 2 bed in this area is ~800 square foot, so the estimated floorspace of residential property in Central London is: 587,100 * 800 = 469,680,000 square feet.
So the amount of ‘freed up’ office space (~ 90-100m sq feet) gives about 20% extra residential space to Central London, if it were all to be ‘handed over’ instantaneously.
How Much Retail Space Is There?
London doesn’t just contain office and residential space, there’s also retail. From this source, the figures show that the amount of space is – relatively speaking – not that significant:
Borough
Square metres
Square feet
The City
2,810,000
~3,000,000
Westminster
1,973,000
~21,200,000
Camden
637,000
~6,900,000
Islington
413,000
~4,400,000
Southwark
434,000
~4,700,000
Tower Hamlets
455,000
~4,900,000
TOTAL
6,722,000
~45,000,000
Retail floorspace in Central London boroughs. Source
Aside from noting its relative lack of size, predicting whether retail floorspace will go up or down is harder to determine. If people move in, retail demand may increase. If people stop working there, it may fall. If floorspace gets cheaper, larger retailers may move back into town to take advantage of Central London’s connectivity to sell more. So I think retail floorspace demand can safely be ignored for the purposes of this discussion.
How Long Will This Take?
If we do indeed need 50% less office space, then how long will this take to work through the system? Obviously, we can’t just wake up tomorrow and start using half of our offices as residential homes, so at least two factors are at play here:
How long office leases are
How quickly offices can be converted to residential
How Long Are Commercial Leases?
According to this source, the typical commercial lease length is 3-7 years. If we split the difference to get the average remaining lease time, that’s 5 years. So, if the typical company was halfway through their lease when the pandemic hit in March, that gives us 2.5 years remaining for the average firm. Half a year later, we’re not far off being 2 years away from when the typical lease ends.
So that’s just two years before 25% of Central London office spaces become vacant. This is frighteningly quick.
How Fast Can Offices Be Converted To Residential?
As mentioned above, 800,000 sq feet of office space was converted to residential in 2013. That might be considered a fairly typical year. To convert 90-100m square feet of office space to residential would therefore take about 100 years in ‘normal’ times. This is clearly far too slow.
At least two factors limit this possible rate of change: the speed of the planning system, and the capacity of the building trade to supply skills.
Consequences
Here’s some of the consequences we might speculate will happen as a result of this sudden demand shock.
Expect the price of office space price to plummet
This one’s a no-brainer – if demand for offices drop, expect a fast drop in the price of office space in London. This might mean businesses open up more expansive spaces, maybe with more old-style physical offices or flexible meeting rooms to take advantage.
Expect London wages to fall
As property costs fall, London wages might be expected to fall, as the pool of staff to compete with goes beyond those that need or want to live in London.
Expect pressure on the planning system
One of the first things we’d expect to see is pressure on the planning system to move faster. As offices vacate, many requests for change of use will come in.
City planning systems are not famed for their efficiency or speed, so I don’t expect this to be fast (especially if numbers overwhelm the system). But this source suggests that smaller requests take 8 weeks to process. I’ve no idea how realistic this is, nor do I know how long it takes for the ‘larger, more complex developments’ mentioned.
This source suggests that ‘Since 2013 the conversion of B1/B8 commercial premises to a dwelling house is considered to be a permitted right. It does not therefore require a Change of Use Planning Application.’ I don’t know how many offices this would cover, nor can I shake the suspicion that it can’t be that easy. Maybe a reader can enlighten me?
Expect a boom for builders
Whatever happens, I expect a boom in the building trade in London. Already, many businesses have taken the opportunity in the lull to refit their buildings, and Central London is awash with builders driving, carrying goods, and shouting to each other near my quiet office. The next few years will be boom time in London for anyone running a building firm as cheap labour and high demand.
Expect reduced transport investment
Fewer workers in London means far less strain on the transport system. In recent decades London has invested enormously in transport infrastructure and capacity. I can remember the abysmal state of the Tube and buses in the 80s: hours spent waiting for buses that arrived in batches, and tube trains that ran infrequently. I can even remember the filthy smoking carriages on the underground. But I digress.
This article from 2013 gives some idea of the sums involved and the plans London had. I expect there to be pressure to not only curtail these plans, but also to reduce services more generally as fewer people pressure the system at rush hour.
Expect even more pubs to disappear
The traditional City pub has been under pressure for some years now, but this will take things to a completely new level. A far-sighted historical blogger has already taken pictures of these pubs in preparation for their demise.
Expect property prices in London to fall, and surrounding areas to rise
The effect on residential property prices in Central London itself is difficult to gauge, as I don’t have a ready model. On the one hand, the conversion of just under 100m square feet of office space to residential will increase supply about 20%, as discussed above.
At first glance, this suggests a straightforward fall in property price. How much is unclear, because previous comparisons (eg with the low property prices of the late 90s) coincided with a general and significant recession (ie a sustained fall in economic output). It’s quite possible that we will have a ‘V-shaped recovery’ without people returning to the office. This is, to use an over-used term, unprecedented.
London workers are already fleeing (not just Central) London, and we’re already seeing the signs of this, with analysis flummoxed by an ‘unexpected mini-boom‘ in the surrounding areas:
‘It can’t be denied that lockdown really emphasised the need to move for many, particularly those who were considering upsizing or leaving London for the commuter belt and we expect this to continue, particularly as workers are told they may not be going back into the office until next year.’ Source
Demand for buying the smaller ‘pied a terre’ properties that already abound there may increase significantly, as those fleers decide to retain a convenient bolt-hole in town. This could moderate the fall of (or even raise) the cost for these properties.
Conclusion
Property markets are dynamic systems, so the scenario above is unlikely to play out as straightforwardly as I’ve analysed it. That’s what makes economics fun. So let’s speculate a bit further.
Any significant drop in property values results in a relative rise in value in surrounding areas as people flee the town. This economic boost to previously ‘failing’ areas could play into the Conservative government’s hands as private investment in these areas replaces or works alongside public investment to produce an economic ‘feelgood’ factor.
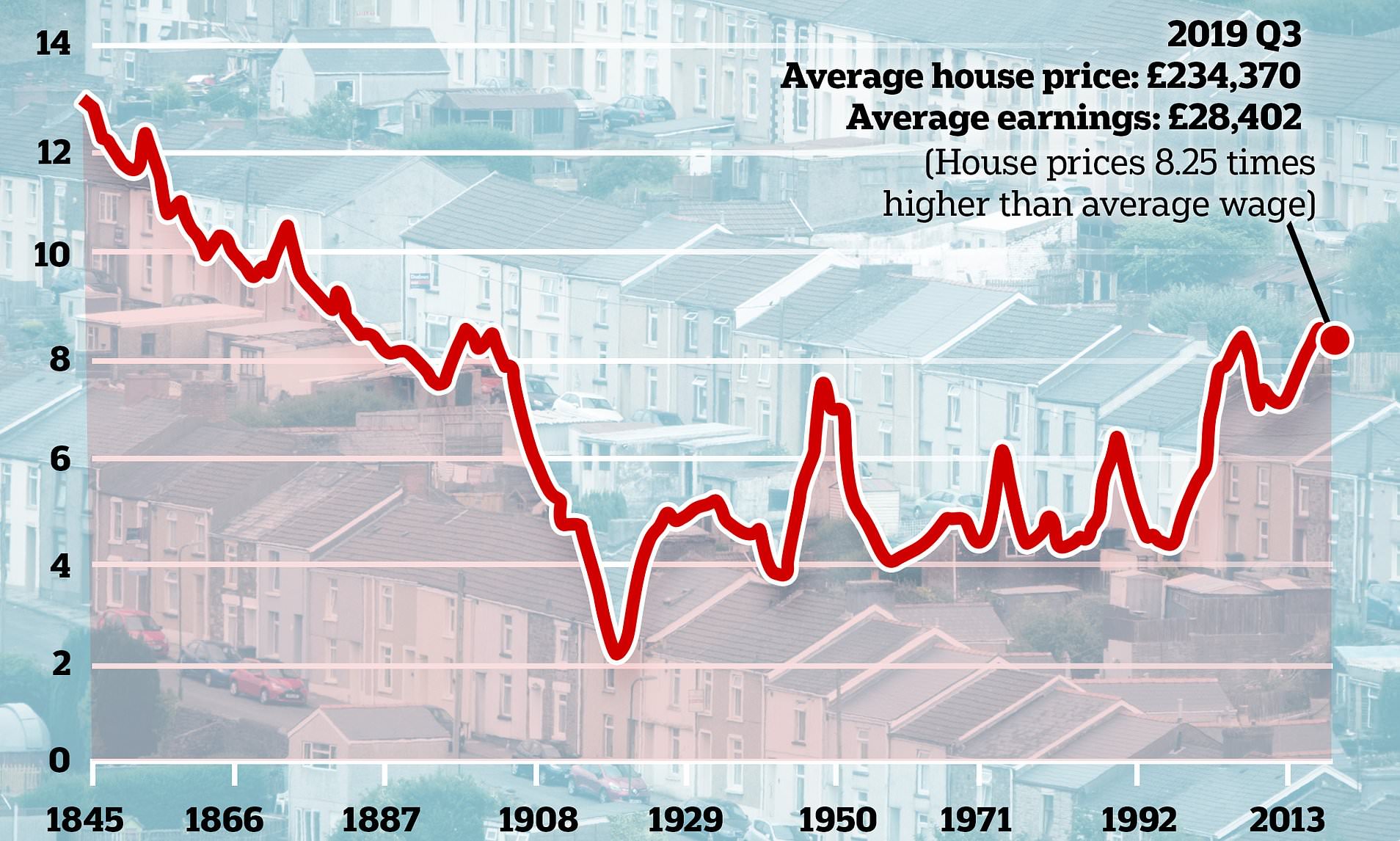
I was tempted to compare the effect of this to wars, but this graph of house prices compared to wages stopped me in my tracks.
You can see that wars appear to have had an effect (drops during the 1910s and the 1940-1945s), but that these pale compared to the steady fall between 1845 and the first world war. According to the analysis, this had three factors: rising incomes, more houses, and smaller houses:
‘The Victorians and Edwardians didn’t just build more houses, they more than doubled the housing stock in England, Wales and Scotland between 1851 and 1911 – from 3.8 million houses to 8.9 million houses.’ Source
This time we may well have a 20% increase in supply in Central London, and an unknown, but possibly similar, increase in supply in the suburbs that depend on Central London activity. A back of envelope calculation suggests that prices could fall by about a third relative to incomes (which could themselves fall significantly, as noted above). In real terms, therefore, we could see London property prices halve.
And this is in the context of demographics which suggest that real London property prices were already under pressure. This 2005 paper from the Federal Reserve predicted a significant real terms fall in UK house prices going out to 2030, and in the last 15 years hasn’t been that far off the mark.
But it’s important not to forget that there is a significant economic benefit to the innovations that working in physical proximity brings. Cities are where ‘ideas have sex‘, and these ideas have intangible value that translates to economic value that justify the city premium. Looking past the next few years, if London property prices fall then young workers will take advantage of the situation to move back in and generate value however it’s done in the future, acting as a brake on any falls. In the meantime, other UK cities could boom as their relative value and compatibility with this new way of working work to their advantage.
Recently I read two books I’d recommend that got me thinking about how the IT industry has changed in the last 20 years. These books are The Great Convergence and Capitalism Without Capital.
First I’ll briefly describe the books, then go over some of the consequences of their theses for the global economy, and then move onto what this has meant for IT in the last 30 years. Specifically, I got interested in why the DevRel position has arisen, and what it means for IT in general.
Richard Baldwin explains our modern civilization’s economic history and future based on three key economic constraints:
The cost of moving goods
The cost of moving ideas
Cost of moving people
The first industrial revolution (1820-1990) removed the need for physical proximity for viable trade in goods (the ‘first unbundling’). This led to the ‘great divergence’ of wealth between nations, as large production centres became key wealth generators for countries that could take the ‘comparative advantage’. Baldwin also characterises this historical turn as ‘globalising local economies’: production microclusters (ie large factories) rose in significance due to the ease of moving goods vs the difficulty of moving people and ideas. The big winners of this era were steelmakers, for example.
Baldwin dates the ‘second unbundling’ of the cost of moving ideas to 1990, and equates its significance to the original industrial revolution in terms of its impact on the global economy. The need for physical proximity for the movement of ideas and skills was removed due to enormous changes in communication technologies. Baldwin characterises this as ‘globalising factories’. The big winners of this era are information traders, such as Google and Facebook.
To illustrate the significance of the change, he cites a few interesting facts I wasn’t aware of, such as that the share of rich nations’ wealth to global wealth is now back to where it was in 1914 (and declining), falling as the Internet has grown.
Note that the G7’s dominance is a blip compared to China and India’s long-standing supremacy.
The third industrial revolution around the cost of moving people is yet to come. It’s still expensive to move people around to do their jobs (think of the highly trained surgeon, for example, or political leader), and although the cost of moving a person has dropped along with the cost of moving goods, it’s still an enormous constraint, as people are conscious beings who need hotels, food and and other conducements to travel that inert materials do not. Baldwin points out that change may be coming here, and is already seen in smaller ways. He cites telerobotics (eg remote surgery), or holographic conferencing, which is prohibitively expensive (and probably unreliable) at the moment, but could become significantly cheaper as its supporting technologies improve.
Some interesting facts cited along the way
The Newcomen steam engine (which went into commercial use in 1712), pumped water out of coal mines that had previously required 500 horses
Between 1986 and 2007, world information storage capacity grew at 23 percent per year, telecommunications at 28 percent, and computation power at 58 percent per year
The value added by manufacturing has been reducing and reducing. Of the $2bn value of iPhones, $0.2bn comes from manufacturing
The Albert Bridge was entirely constructed in the 19th century in England, and shipped to Adelaide for assembly
This book is similar to the first in that it makes an observation about recent history and extrapolates consequences from that. In this case that intangible value has become more and more significant for the economy over the last decades.
Intuitively, this is fairly uncontroversial. Whereas 100 years ago physical assets were a central part of every major business (think big steel, the car factory, the tool-maker, the oil company), the biggest companies now include many who primarily own intangible assets. For example, in 2006, Microsoft’s $250bn market value contained only $10bn of physical assets. And ‘only’ $60bn of it was cash or financial instruments. The remainder is intangible value: brands, software, service capabilities etc.
The book argues nimbly that intangibles differ significantly from traditional business assets in four key ways:
Scalability (costs nothing to reuse, say, an idea or brand)
Sunkenness (once you’ve invested in an intangible, it’s hard to move or repurpose it)
Spillovers (if you have an idea, others can easily use it or recombine it with other ideas)
Synergies (putting ideas together than create significant further value with little cost)
They also differ in other more concrete ways. Intangible assets are hard to account for, leading to some interesting accounting nuances. For example, if you invest in a brand, it seems that the value of that investment can not be turned into an asset value within your business accounts. However, if you buy someone else’s company and their value is partly intangible, that’s written down as ‘goodwill’ on the company accounts. This creates some interesting consequences discussed later.
GDP also has an ambivalent relationship to intangible assets. Many types of intangible asset don’t figure in GDP calculations. If intangible investment and production is becoming more and more the norm, then this may go some way to explain why G7 economies appear to be doing relatively badly compared to so-called ‘developing’ nations that show year after year of strong GDP growth.
Some other interesting facts gleaned
Edgar Rice Burrows acquired a trademark for Tarzan in the 1920s. The beginning of movies’ obsession with building intangible but legally defensible IP rather than, y’know, drama of any discernible quality (I’m looking at you, Star Wars and Marvel)
Mickey Mouse’s copyright is due to expire in 2023, which might explain why Disney don’t invest in him
In 1961 , the world produced $746bn through agriculture. In 2009, $2,260bn, an output rise of 203%, far morethan population growth (~130%). In 1961 world had 4.46bn hectares of land under cultivation; in 2009, 4.89bn (+10%)
‘Peak horse’ happened around 1910, 80 years after introduction of the first railway
Amazon warehouse workers walk up to 15 miles per shift
Henry P. Crowell’s invention of Quaker Oats in 1879 required a strenuous advertising campaign to convince consumers that the food was not horse fodder
Consequences For Economies
Some of the consequences of these books’ theses will not be surprising. Obviously, improved communications has increased the viability of remote working, and increased the already-existing trends towards offshoring significant parts of the value chain.
Also fairly obvious is that the most successful companies trade more and more on their intangible value. A social network is almost purely an intangible enterprise (and partly explains their fragility as businesses). A car-sharing business’s value is almost entirely composed of intangible property such as its brand and its software.
Even an old-fashioned heavy goods manufacturing business like Tesla has a significant amount of intangible value via its brand and the Musk halo effect. This helps it trade far above the values the raw production and sales figures suggest, as well as attract key staff and customer loyalty.
Less Obviously…
More subtly, these books suggest that these trends encourage the loosening of traditional working bonds. If you’re not constrained to work for the local factory owner due to your location, but can easily move your labour to anywhere in the world, then the power relationship between leader and led is very much altered.
By the same token, however, your boss is no longer dependent on their business’s physical location either. Rather than owning an effectively immovable plant and depending on people in the local area to supply labour, they can freely source labour across the world wherever it may be that has a usable internet connection.
The end result of this is an even more fluid relationship between employer and employed than has existed in the past. The success of this relationship will depend far more on leadership than management, where management is ‘telling people what to do’, which leadership is ‘motivating people towards a goal’. Indeed, relative mentions of ‘leadership’ over ‘management’ in the Harvard Business Review show that talk of ‘leadership’ is growing much faster.
If ideas and skills can be moved easily, then collating and harnessing those skills becomes more important. If skills are more and more mobile while being in demand then ‘telling people what to do’ is going to be less and less what businesses do. ‘Telling people what to do’ has traditionally been called ‘management’ – think of Taylor and his time and motion studies.
Exchanging Leadership For Capital
If leadership (as opposed to management) is now at a premium, then we would expect to see businesses exist to build up that intangible asset and exchange it for capital. And that’s exactly what we do see.
For example, many small technical consultancies get eaten up by larger-scale businesses simply because they have mind-share in a particular area. This, despite the fact that those businesses might not even turn a profit or even show any promise of doing so in the future. Just having that credibility is enough. In other words, their intangible value exceeds their book value.
Perhaps the most obvious example of this was virtualization behemoth VMWare’s purchase of various cloud native businesses in recent years. I won’t comment on any of these business’s specific profitability prior to purchase, but suffice it to say that I’m informed that some of them were made offers that were difficult for their owners to refuse given their book value…
The DevRel and Public Validation
All these things taken together explain something that had mystified me until recently: the rise of the DevRel role. I don’t even know how to formally state it: a ‘developer relations expert’, or ‘develop relationship manager’, or what? Commonly it’s just known as a ‘developer relations’ role (so ‘DevRel’ for short), and formally defined (by a quick google search, natch) as ‘a marketing policy that prioritizes relationships with developers’. But it still makes no grammatical sense to say ‘I am a Developer Relations for X’.
Anyway, a DevRel is a bridge between internal knowledge and external consumption of that value. In other words, it’s a sales role, albeit with a different focus. DevRels frequently get wheeled out to demonstrate technical competence to potential customers (at the low end), or as travelling rock stars (at the high end) to demonstrate credibility, or just dazzle the client with star power.
This is similar to the old ‘pre-sales’ role, but the twist is that the value DevRels bring is demonstrating publicly-validated credibility through conference talks and social media followers rather than demonstrating that an enterprise system can be integrated to your org with a little effort in a few days as a proof of concept.
There’s also some interesting parallels with traditional salespeople here. While the old salesperson was partly valued by the contents of their private Rolodex, the DevRel is valued partly by the publicly-validated status of their profile. Their public profile serves as a kind of ‘proof of credibility’ system for establishing their credibility (I have to physically resist mentioning ‘blockchain’ here…).
It’s hard to fake followers on Twitter these days. You have to either cheat and risk getting thrown off – which has become harder lately – or just show up and engage positively for a long, long time. It’s also difficult to get a reputation as a conference speaker by faking it.
In other words, technical leadership is becoming a publicly-tradeable commodity that in turn gives a company credibility to sell. You may begin to wonder: what value does a company actually have if good marketing can even be an intangible proxy for another (arguably less) intangible product (software expertise)? As in many industries, it’s becoming increasingly difficult to explain to people what it is you actually do, a situation sent up in a radio show recently:
I don’t really know where these trends are going, but it be just a matter of time before there are courses on gaining technical credibility in the marketplace, just as there are courses on marketing and PR now. Maybe there already are…
Related Links
If you liked this, then other posts about books I’ve read might be of interest:
It got a lot of hits (mostly from HackerNews), and privately quite a few people reached out to me to ask for advice on embedding similar practices in their own organisations. It even got name-checked in a Google SRE book.
Since then, I’ve learned a few more things about trying to get operational teams to follow best practice by writing and maintaining runbooks, so this is partly an update of that.
All these experiences have led me to help initiate a public Runbooks project to try and collect and publish similar efforts and reduce wasted effort across the industry.
tl;dr
We’ve set up a public Runbooks project to expose our private runbooks to the world.
We’re looking for contributions. Do you have any runbooks lying around that could benefit from being honed by many eyes? The GitHub repo is here if you want to get involved, or contact me on Twitter.
I already talked about this in the previous post, but every subsequent attempt I made to get a practice of writing runbooks going was hard going. No-one ever argues with the logic of efficiency and saved time, but when it comes to putting the barn up, pretty much everyone is too busy with something else to help.
In summary, you can’t tell people anything. You have to show them, get them to experience it, or incentivise them to work on it.
Some combination of these four things is required:
Line-management/influence/control to encourage/force the right behaviours
A critical mass of material to demonstrate value
Resources allocated to sustain the effort
A process for maintaining the material and ensuring it remains relevant
With a prevailing wind, you can get away with less in one area, but these are the critical factors that seem to need to be in place to actually get results.
A Powerful External Force Is Often Needed
Looking at the history of these kind of efforts, it seems that people need to be forced – against their own natures – into following these best practices that invest current effort for future operational benefit.
Boeing and checklists (“planes are falling from the sky – no matter how good the pilots!”)
Construction and standard project plans (“falling building are unacceptable, we need a set of build patterns to follow and standards to enforce”)
Medicine and ‘pre-flight checklists’ (“we’re getting sued every time a surgeon makes a mistake, how can we reduce these?”)
In the case of my previous post, it was frustration for me at being on-call that led me to spend months writing up runbooks. The main motivation that kept me going was that it would be (as a minimal positive outcome) for my own benefit. This intrinsic motivation got the ball rolling, and the effort was then sustained and developed by both the development of more structured process-oriented management and others seeing that it was useful to them.
There’s a commonly-seen pattern here:
you need some kind of spontaneous intrinsic motivation to get something going and snowball, and then
a bureaucratic machine behind it to sustain it
If you crack how to do that reliably, then you’re going to be pretty good at building businesses.
A Runbook Doesn’t Always Help
That wasn’t the only experience I had trying to spread what I thought was good practice. In other contexts, I learned, the application of these methods was unhelpful.
In my next job, I worked on a new and centralised fast-changing system in a large org, and tried to write helpful docs to avoid repeating solving the same issues over and over. Aside from the authority and ‘critical mass’ problems outlined above, I hit a further one: the system was changing too fast for the learnings to be that useful. Bugs were being fixed quickly (putting my docs out of date similarly quickly) and new functionality was being added, leading to substantial wasted effort and reduced benefit.
Discussing this with a friend, I was pointed at a framework that already existed called Cynefin that had already thought about classifying these differences of context, and what was an appropriate response to them. Through that lens, my mistake had been to try and impose what might be best practice in a ‘Complicated’/’Clear’ context to a context that was ‘Chaotic’/’Complex’. ‘Chaotic’ situations are too novel or under-explored to be susceptible to standard processes. Fast action and equally fast evaluation of system response is required to build up practical experience and prepare the way for later stabilisation.
‘Why Don’t You Just Automate It?’
I get this a lot. It’s an argument that gets my goat, for several reasons.
Runbooks are a useful first step to an automated solution
If a runbook is mature and covers its ground well, it serves as an almost perfect design document for any subsequent automation solution. So it’s in itself a useful precursor to automation for any non-trivial problem.
Automation is difficult and expensive
It is never free. It requires maintenance. There are always corner cases that you may not have considered. It’s much easier to write: ‘go upstairs’ than build a robot that climbs stairs.
Automation tends to be context-specific
If you have a wide-ranging set of contexts for your problem space, then a runbook provides the flexibility to applied in any of these contexts when paired with a human mind. For example: your shell script solution will need to reliably cater for all these contexts to be useful; not every org can use your Ansible recipe; not every network can access the internet.
All my thoughts on this subject so far have been predicated on writing proprietary runbooks that are consumed and maintained within an organisation.
What I never considered was gaining the critical mass needed by open sourcing runbooks, and asking others to donate theirs so we can all benefit from each others’ experiences.
So we at Container Solutions have decided to open source the runbooks we have built up that are generally applicable to the community. They are growing all the time, and we will continue to add to them.
Call for Runbooks
We can’t do this alone, so are asking for your help!
If you have any runbooks that you can donate to the cause lying around in your wikis, please send them in
If you want to write a new runbook, let us know
If you want to request a runbook on a particular subject, suggest it
Following on from previouspostsonbash, here’s some more bash tips that are relatively obscure, or rarely seen, but still worth knowing about.
1) Mid-Command Comments
Usually when I want to put a comment next to a shell command I put it at the end, like this:
echo some command # This echoes some output
But until recently I had no idea that you could embed comments within a chain of commands using the colon operator:
echo before && : this && echo after
Combined with subshells, this means you can annotate things really neatly, like this:
(echo banana; : IF YOU ARE COPYING \THIS FROM STACKOVERFLOW BE WARNED \THIS IS DANGEROUS) | tr 'b' 'm'
2) |&
You may already be familiar with 2>&1, which redirects standard error to standard output, but until I stumbled on it in the manual, I had no idea that you can pipe both standard output and standard error into the next stage of the pipeline like this:
if doesnotexist |& grep 'command not found' >/dev/null then echo oops fi
3) $''
This construct allows you to specify specific bytes in scripts without fear of triggering some kind of encoding problem. Here’s a command that will grep through files looking for UK currency (‘£’) signs in hexadecimal recursively:
grep -r $'\xc2\xa3' *
You can also use octal:
grep -r $'\302\243' *
4) HISTIGNORE
If you are concerned about security, and ever type in commands that might have sensitive data in them, then this one may be of use.
This environment variable does not put the commands specified in your history file if you type them in. The commands are separated by colons:
HISTIGNORE="ls *:man *:history:clear:AWS_KEY*"
You have to specify the whole line, so a glob character may be needed if you want to exclude commands and their arguments or flags.
If readline key bindings aren’t under your fingers, then this one may come in handy.
It calls up the last command you ran, and places it into your preferred editor (specified by the EDITOR variable). Once edited, it re-runs the command.
6) ((i++))
If you can’t be bothered with faffing around with variables in bash with the $[] construct, you can use the C-style compound command.
So, instead of:
A=1
A=$[$A+1]
echo $A
you can do:
A=1
((A++))
echo $A
which, especially with more complex calculations, might be easier on the eye.
7) caller
Another builtin bash command, caller gives context about the context of your shell’s
SHLVL is a related shell variable which gives the level of depth of the calling stack.
This can be used to create stack traces for more complex bash scripts.
Here’s a die function, adapted from the bash hackers’ wiki that gives a stack trace up through the calling frames:
#!/bin/bash
die() {
local frame=0
((FRAMELEVEL=SHLVL - frame))
echo -n "${FRAMELEVEL}: "
while caller $frame; do
((frame++));
((FRAMELEVEL=SHLVL - frame))
if [[ ${FRAMELEVEL} -gt -1 ]]
then
echo -n "${FRAMELEVEL}: "
fi
done
echo "$*"
exit 1
}
which outputs:
3: 17 f1 ./caller.sh
2: 18 f2 ./caller.sh
1: 19 f3 ./caller.sh
0: 20 main ./caller.sh
*** an error occured ***
8) /dev/tcp/host/port
This one can be particularly handy if you find yourself on a container running within a Kubernetes cluster service mesh without any network tools (a frustratingly common experience).
Bash provides you with some virtual files which, when referenced, can create socket connections to other servers.
This snippet, for example, makes a web request to a site and returns the output.
The first line opens up file descriptor 9 to the host brvtsdflnxhkzcmw.neverssl.com on port 80 for reading and writing. Line two sends the raw HTTP request to that socket connection’s file descriptor. The final line retrieves the response.
Obviously, this doesn’t handle SSL for you, so its use is limited now that pretty much everyone is running on https, but when running from application containers within a service mesh can still prove invaluable, as requests there are initiated using HTTP.
9) Co-processes
Since version 4 of bash it has offered the capability to run named coprocesses.
It seems to be particularly well-suited to managing the inputs and outputs to other processes in a fine-grained way. Here’s an annotated and trivial example:
coproc testproc (
i=1
while true
do
echo "iteration:${i}"
((i++))
read -r aline
echo "${aline}"
done
)
This sets up the coprocess as a subshell with the name testproc.
Within the subshell, there’s a never-ending while loop that counts its own iterations with the i variable. It outputs two lines: the iteration number, and a line read in from standard input.
After creating the coprocess, bash sets up an array with that name with the file descriptor numbers for the standard input and standard output. So this:
echo "${testproc[@]}"
in my terminal outputs:
63 60
Bash also sets up a variable with the process identifier for the coprocess, which you can see by echoing it:
echo "${testproc_PID}"
You can now input data to the standard input of this coprocess at will like this:
echo input1 >&"${testproc[1]}"
In this case, the command resolves to: echo input1 >&60, and the >&[INTEGER] construct ensures the redirection goes to the coprocess’s standard input.
Now you can read the output of the coprocess’s two lines in a similar way, like this:
You might use this to create an expect-like script if you were so inclined, but it could be generally useful if you want to manage inputs and outputs. Named pipes are another way to achieve a similar result.
Here’s a complete listing for those who want to cut and paste:
Recently I (along with a few others much smarter than me) had occasion to implement a ‘real’ production system with Istio, running on a managed cloud-provided Kubernetes service.
Istio has a reputation for being difficult to build with and administer, but I haven’t read many war stories about trying to make it work, so I thought it might be useful to actually write about what it’s like in the trenches for a ‘typical’ team trying to implement this stuff. The intention is very much not to bury Istio, but to praise it (it does so much that is useful/needed for ‘real’ Kubernetes clusters – skip to the end if impatient) while warning those about to step into the breach what comes if you’re not prepared.
In short, I wish I’d found an article like this before we embarked on our ‘journey’.
None of us were experienced implementers of Istio when combined with other technologies. Most of us had about half a year’s experience working with Kubernetes and had spun up vanilla Istio more than a few times on throwaway clusters as part of our research.
1) The Number Of People Doing This Feels Really Small
Whenever we hit up against a wall of confusion, uncertainty, or misunderstanding, we reached out to expertise in the usual local/friendly/distant escalation path.
The ‘local’ path was the people on the project. The ‘friendly’ path were people in the community we knew to be Istio experts (talks given at Kubecon and the like). One such expert admitted to us that they used Linkerd ‘until they absolutely needed Istio for something’, which was a surprise to us. The ‘distant’ path was mostly the Istio forum and the Istio Slack channel.
Whenever we reached out beyond each other we were struck by how few people out there seemed to be doing what we were doing.
Not for the first time with Kubernetes I'm thinking: 'Surely we can't be the only people in the world trying to do this?' pic.twitter.com/cqFE0EQZj2
‘What we were doing’ was trying to make Istio work with:
applications that may not have conformed to the purest ideals of Kubernetes
a strict set of network policies (Calico global DENY-ALL)
a monitoring stack we could actually configure to our needs without just accepting the ‘non-production ready’ defaults
Maybe we were idiots who could configure our way out of a paper bag, but it felt that, beyond doing 101 guides or accepting the defaults, there just wasn’t that much prior art out there.
Eventually we got everything to work the way we wanted, but we burned up significant developer time in the process, and nearly abandoned our efforts more than once on the way.
2) If You Go Off The Beaten Path, Prepare For Pain
Buoyed by our success running small experiments by following blogs and docs, we optimistically tried to leap to get everything to work at the same time. Fortunately, we ran strict pipelines with a fully GitOps’d workflow which meant there were vanishingly few ‘works on my cluster’ problems to slow us down (if you’re not doing that, then do so, stat. It doesn’t have to be super-sophisticated to be super-useful).
Istio question:
Does _anyone_ have a solution for where you:
– want mTLS switched on
– want pod2pod communication to work and auto-encrypted (maybe with host checking off, since pod IPs aren't baked into the certs)
Tried many things that looked like they might work, but don't
A great example of this was monitoring. If you just read the literature, then setting up a monitoring stack is a breeze. Run the default Istio install on a bare server, and everything comes for free. Great. However, we made the mistake of thinking that this meant fiddling with this stack for our own ends would be relative easy.
First, we tried to make this work with a strict mTLS mode (which is not the default, for very good reason). Then we tried to make the monitoring stack run in a separate namespace. Then we tried to make it all work with a strict global network policy of DENY-ALL. All three of these things caused enormous confusion when it didn’t ‘just work’, and chewed up weeks of engineering time to sort out.
The conclusion: don’t underestimate how hard it will be make changes you might want to make to the defaults when using Istio alongside other Kubernetes technologies. Better to start simple, and work your way out to build a fuller mental model that will serve you better for the future.
Istio has a lot of terms that are overloaded in other related contexts. Terms commonly used, like ‘cluster’, or ‘registry’ may have very specific meanings or significance depending on context. This is not a disease peculiar to Istio, but the denseness of the documentation and the number of concepts that must be embedded in your understanding before you can parse them fluently.
We spend large amounts of time interpreting passages of the docs, like theologians arguing over Dead Sea Scrolls (“but cluster here means the mesh”, “no, it means ingress to the kubernetes cluster”, “that’s a virtual service, not a service”, “a headless service is completely different from a normal service!”).
Here’s a passage picked more or less at random:
An ingress Gateway describes a load balancer operating at the edge of the mesh that receives incoming HTTP/TCP connections. It configures exposed ports, protocols, etc. but, unlike Kubernetes Ingress Resources, does not include any traffic routing configuration. Traffic routing for ingress traffic is instead configured using Istio routing rules, exactly in the same way as for internal service requests.
I can read that now and pretty much grok what it’s trying to tell in real time. Bully for me. Now imagine sending that to someone not fully proficient in networking, Kubernetes, and Istio in an effort to get them to help you figure something out. As someone on the project put it to me: ‘The Istio docs are great… if you are already an Istio developer.’
As an aside, it’s a good idea to spend some time familiarising yourself with the structure of the docs, as it very quickly becomes maddening to try and orient yourself: ‘Where the hell was that article about Ingress TLS I saw earlier? Was it in Concepts, Setup, Tasks, Examples, Operation, or Reference?”
Where was that doc?
4) It Changes Fast
While working on Istio, we discovered that things we couldn’t do in one release started working in another, while we were debugging it.
While we’re on the subject, take upgrades seriously too: we did an innocuous-looking upgrade, and a few things broke, taking the system out for a day. The information was all there, but was easy to skip over in the release notes.
You get what you pay for, folks, so this should be expected from such a fundamental set of software components (Istio) running within a much bigger one (Kubernetes)!
5) Focus On Working On Your Debug Muscles
If you know you’re going to be working on Istio to any serious degree, take time out whenever possible to build up your debug skills on it.
Unfortunately the documentation is a little scattered, so here are some links we came across that might help:
When you’re lost in the labyrinth, it’s easy to forget what power and benefits Istio can bring you.
Ingress and egress control, mutual TLS ‘for free’, a jump-start to observability, traffic shaping… the list goes on. Its feature set is unparalleled, it’s already got mindshare, and it’s well-funded. We didn’t want to drop it because all these features solved a myriad of requirements in one fell swoop. These requirements were not that recherché, so this is why I think Istio is not going away anytime soon.
The real lesson here is that you can’t hide from the complexity of managing all functionalities and expect to be able manipulate and control it at will without any hard work.
Budget for it accordingly, and invest the time and effort needed to benefit from riding the tiger.