The host runs Vagrant and Virtualbox. Each box in the host box (the big rectangle) represents a virtual machine. There are workers (which run the pods, controllers, which run the kubernetes cluster) and a client (which has the kubernetes binaries installed on it) and a load balancer (which represents the entry point to the cluster.
Is it safe?
All work (including the Kubernetes client commands) are done within your locally-provisioned VMs, so it should won’t install crazy things to your machine or anything.
How Does it Work?
The script uses ShutIt to automate the steps to bring up the cluster and walk through the build. Contact me for more info: @ianmiell
Recently I have been playing with Terraform. It’s a lot of fun.
I had a little project that was perfect for it, but ran into a problem. Most examples of Terraform usage assume that your environments are static. So layouts like this are not uncommon:
All well and good, but in my project I needed to create environments on the fly, and perhaps many in existence at the same time. There was no ‘live’, just potentially hundreds of envs in use at once for a short period of time.
I also needed to keep a record of environments created and destroyed.
I researched and asked around, but couldn’t find any best practice for this, so came up with a pattern that may be useful to others.
Nothing a Shell Script Can’t Handle
In one sentence, this scheme creates a new folder on demand with a unique value which is destroyed when time is up.
The original code is elsewhere and somewhat more complex, so I put together this simple example code to illustrate the flow.
Create a directory with a unique (well, probably) ID
Set up the main.tf file
Terraform the environment
(Git) add, commit and push the new directory
This script can be triggered when a new environment is required.
#!/bin/bash# Ensure we are in the right folderpushd$(dirname ${BASH_SOURCE[0]})# Create a (probably) unique ID by concatenating two random
# values (RANDOM is a variable inherent to bash), with the day of year
# as a suffix.ID="dynamic_environment_${RANDOM}${RANDOM}_$(date +%j)"# Create the terraform folder.mkdir-p${ID}pushd${ID}cat > main.tf << ENDmodule "dynamicenv" {source = "../modules/dynamicenv"dynamic_env_id = "${ID}"}END# Terraform ahoy!terraform getterraform planterraform applypopd# Record the creation in git and push. Assumes keys set up.git add ${ID}git commit -am"${ID} environment added"git pushpopd
destroy_dynamic_environments.sh
After 7 days, retire the environment
(Git) remove, commit and push the removal
This script can be run regularly in a cron.
In the ‘real’ aws environment I get the EC2 instance to self-destruct after a few hours, but for belt and braces we destroy the environment and remove it from git.
#!/bin/bash# We need extended glob capabilities.shopt -s extglob
# Ensure we are in the right folderpushd$(dirname ${BASH_SOURCE[0]})# Default to destroying environments over 7 days old.# If you want to destroy all of them, pass in '-1' as an argument.DAYS=${1:-7}
# Get today's 'day of year'
TODAY=$(date +%j)# Remove leading zeroes from the date.TODAY=${TODAY##+(0)}# Go through all the environment folders, and terraform destroy,
# git remove and remove the folder.for dir in $(find dynamic_environment_* -type d -maxdepth 0)do# Remove the folder prefix.dir_day=${dir##*_}# Remove any leading zeroes from the day of year.dir_day=${dir_day##+(0)}# If over 7 days old...if [[ $(( ${TODAY} - ${dir_day})) -gt ${DAYS} ]]thenpushd "${dir}"
# Destroy the environment.terraform destroy -forcepopd# Remove from git.git rm -rf "${dir}"git commit -am "destroyed ${dir}"git push# Remove left-over backup files.rm -rf "${dir}"fidone
I routinely use both bash and python to quickly whip up tools for short and long-term uses.
Generally I start with a bash script because it’s so fast to get going, but as time goes on I add features, and then wish I had started it in python so that I could access all the modules and functionality that’s harder to get to in bash.
I found a bash2py tool, which looked good, but came as a zipped source download (not even in a git repo!).
I created a Docker image to convert it, and have used it a couple of times. With a little bit of effort you can quickly convert your bash script to a python one and move ahead.
Example
I’m going to use an artificially simple but realistic bash script to walk through a conversion process.
Let’s say I’ve written this bash script to count the number of lines in a list of files, but want to expand this to do very tricky things based on the output:
#!/bin/bashif [ $# -lt 1 ]thenecho "Usage: $0 file ..."exit 1fiecho "$0 counts the lines of code" l=0for f in $*do l=`wc -l $f | sed 's/^\([0-9]*\).*$/\1/'` echo "$f: $l"done
Here’s a conversion session:
imiell@Ians-Air:/space/git/work/bin$ docker run -ti imiell/bash2pyUnable to find image 'imiell/bash2py:latest' locallylatest: Pulling from imiell/bash2py357ea8c3d80b: Already exists 98b473a7fa6a: Pull complete a7f8553161b4: Pull complete a1dc4858a149: Pull complete 752a5d408084: Pull complete cf7fa7bc103f: Pull complete Digest: sha256:110450838816d2838267c394bcc99ae00c99f8162fa85a1daa012cff11c9c6c2Status: Downloaded newer image for imiell/bash2py:latestroot@89e57c8c3098:/opt/bash2py-3.5# vi a.shroot@89e57c8c3098:/opt/bash2py-3.5# ./bash2py a.sh root@89e57c8c3098:/opt/bash2py-3.5# python a.sh.py Usage: a.sh.py file ...root@89e57c8c3098:/opt/bash2py-3.5# python a.sh.py afilea.sh.py counts the lines of codeafile: 16
So that’s nice, I now have a working python script I can continue to build on!
Simplify
Before you get too excited, unfortunately it’s not magically working out which python modules to import and cleverly converting everything from bash to python. However, what’s convenient about this is that you can adjust the script where you care about it, and build from there.
To work through this example, here is the raw conversion:
#! /usr/bin/env pythonfrom __future__ import print_function
import sys,os
class Bash2Py(object):__slots__ = ["val"]def __init__(self, value=''):self.val = valuedef setValue(self, value=None):self.val = valuereturn valuedef GetVariable(name, local=locals()):if name in local:return local[name]if name in globals():return globals()[name]return Nonedef Make(name, local=locals()):ret = GetVariable(name, local)if ret is None:ret = Bash2Py(0)globals()[name] = retreturn retdef Array(value):if isinstance(value, list):return valueif isinstance(value, basestring):return value.strip().split(' ')return [ value ]class Expand(object):@staticmethoddef at():if (len(sys.argv) < 2):return []returnsys.argv[1:]@staticmethoddef star(in_quotes):if (in_quotes):if (len(sys.argv) < 2):return ""return " ".join(sys.argv[1:])return Expand.at()@staticmethoddef hash():returnlen(sys.argv)-1if (Expand.hash() < 1 ):print("Usage: "+__file__+" file ...")exit(1)print(__file__+" counts the lines of code")l=Bash2Py(0)
for Make("f").val in Expand.star(0):Make("l").setValue(os.popen("wc -l "+str(f.val)+" | sed \"s/^\\([0-9]*\\).*$/\\1/\"").read().rstrip("\n"))print(str(f.val)+": "+str(l.val))
The guts of the code is in the for loop at the bottom.
bash2py does some safe conversion and wrapping of the bash script into some methods such as ‘Make’, ‘Array’ et al that we can get rid of with a little work.
By replacing:
Bash2Py(0) with 0
Make(“f”).val with f
and Make(“l”) with l etc
f.val with f
and l.val with l etc
54,57c27,30
< l=Bash2Py(0)
< for Make("f").val in Expand.star(0):
< Make("l").setValue(os.popen("wc -l "+str(f.val)+" | sed \"s/^\\([0-9]*\\).*$/\\1/\"").read().rstrip("\n"))
< print(str(f.val)+": "+str(l.val))
---
> l=0
> for f in Expand.star(0):
> l = os.popen("wc -l "+str(f)+" | sed \"s/^\\([0-9]*\\).*$/\\1/\"").read().rstrip("\n")
> print(str(f)+": "+str(l))
I simplify that section.
I can remove the now-unused methods to end up with the simpler:
#! /usr/bin/env pythonfrom __future__ import print_functionimport sys,osclass Expand(object):@staticmethoddef at():if (len(sys.argv) < 2):return []returnsys.argv[1:]@staticmethoddef star(in_quotes):if (in_quotes):if (len(sys.argv) < 2):return ""return " ".join(sys.argv[1:])return Expand.at()@staticmethoddef hash():returnlen(sys.argv)-1if (Expand.hash() < 1 ):print("Usage: "+__file__+" file ...")exit(1)print(__file__+" counts the lines of code")l=0for f in Expand.star(0):l = os.popen("wc -l "+str(f)+" | sed \"s/^\\([0-9]*\\).*$/\\1/\"").read().rstrip("\n")print(str(f)+": "+str(l))
Note I don’t bother with ‘Expand’ yet, but I can pythonify that later if I choose to.
Unikernels are a relatively new concept to most people in IT, but have been around for a while.
They are operating system running as VMs under a hypervisor, but are:
Single-purpose
Only use the libraries they need
A unikernel might not have networking (for example)
Built from a set of available libraries which are dynamically pulled into the image as needed
So rather than starting from a ‘complete’ OS like Linux and then stripping out what’s not needed, only what’s needed to run the OS is included.
This brings some benefits:
Smaller OS image size
Smaller security attack surface
Fast bootup
Small footprint
True isolation from other OSes on the same host
Docker recently bought a unikernel company and promptly used their technology to deliver a very impressive Beta for Mac using xhyve. The end result was a much improved user experience delivered surprisingly quickly.
Walkthrough
This walkthrough uses one flavour of unikernel (MirageOS) to demonstrate the building of a unikernel as a Unix binary and as a xen VM image.
The unikernel uses the console library to print out ‘hello world’ four times and exit.
It sets up an Ubuntu xenial VM and compiles the binary and VM image. The VM image is run using the xl tool, which runs up the VM as though it were a VM running under Xen.
[A video of me talking about this is available here]
Docker is extremely popular with developers, having gone as a product from zero to pretty much everywhere in a few years.
I started tinkering with Docker three years ago, got it going in a relatively small corp (700 employees) in a relatively unregulated environment. This was great fun: we set up our own registry, installed Docker on our development servers, installed Jenkins plugins to use Docker containers in our CI pipeline, even wrote our own build tool to get over the limitations of Dockerfiles.
I now work for an organisation working in arguably the most heavily regulated industry, with over 100K employees. The IT security department itself is bigger than the entire company I used to work for.
There’s no shortage of companies offering solutions that claim to meet all the demands of an enterprise Docker platform, and I seem to spend most of my days being asked for opinions on them.
I want to outline the areas that may be important to an enterprise when considering developing a Docker infrastructure.
If I’ve missed anything or you have any comments get in touch below or tweet @ianmiell
Images
Registry
You will need a registry. There’s an open source one (Distribution), but there’s numerous offerings out there to choose from if you want to pay for an enterprise one.
Does this registry play nice with your authentication system?
Does it have a means of promoting images?
Does it have role-based access control?
Does it cohere well with your other artifact stores?
Image Scanning
An important one.
When images are uploaded to your registry, you have a golden opportunity to check that they conform to standards. For example, could these questions be answered:
Is there a shellshock version of bash on there?
Is there an out of date ssl library?
Is it based on a fundamentally insecure or unacceptable base image?
Static image analysers exist and you probably want to use one.
Image Building
How are images going to be built? Which build methods will be supported and/or are strategic for your organisation? How do these fit together?
Dockerfiles are the standard, but some users might want to use S2I, Docker + Chef/Puppet/Ansible or even hand-craft them.
Which CM tool do you want to mandate (if any)
Can you re-use your standard governance process for your configuration management of choice?
Can anyone build an image?
Image Integrity
You need to know that the images running on your system haven’t been tampered with between building and running.
Have you got a means of signing images with a secure key?
Have you got a key store you can re-use?
Can that key store integrate with the products you choose?
Third Party Images
Vendors will arrive with Docker images expecting there to be a process of adoption.
Do you have a governance process already for ingesting vendor technology?
Can it be re-used for Docker images?
Do you need to mandate specific environments (eg DMZs) for these to run on?
Will Docker be available in those environments?
SDLC
If you already have software development lifecycle (SDLC) processes, how does Docker fit in?
How will patches be handled?
How do you identify which images need updating?
How do you update them?
How do you tell teams to update?
How do you force them to update if they don’t do so in a timely way?
Secrets
Somehow information like database passwords need to be passed into your containers. This can be done at build time (probably a bad idea), or at run time.
How will secrets be managed within your containers?
Is the use of this information audited/tracked and secure?
Base Image?
If you run Docker in an enterprise, you might want to mandate the use of a company-wide base image:
What should go into this base image?
What standard tooling should be everywhere?
Who is responsible for it?
Security and Audit
The ‘root’ problem
By default, access to the docker command implies privileges over the whole machine. This is unlikely to be acceptable to most sec teams in production.
Who (or what) is able to run the docker command?
What control do you have over who runs it?
What control do you have over what is run?
Solutions exist for this, but they are relatively new.
Monitoring what’s running
A regulated enterprise is likely to want to be able to determine what is running across its estate. What can not be accounted for?
How do you tell what’s running?
Can you match that content up to your registry/registries?
Is what is running up to date?
Have any containers changed critical files since startup?
Forensics
When things go wrong people will want to know what happened. In the ‘old’ world of physicals and VMs there were a lot of safeguards in place to assist post-incident investigation. A Docker world can become one without ‘black box recorders’.
Can you tell who ran a container?
Can you tell who built a container?
Can you determine what a container did once it’s gone?
Can you determine what a container might have done once it’s gone?
Operations
Logging
Application logging is likely to be a managed or controlled area of concern:
Do the containers log what’s needed for operations?
Do they follow standards for logging?
Where do they log to?
Orchestration
Containers can quickly proliferate across your estate, and this is where orchestration comes in. Do you want to mandate one?
Does your orchestrator of choice play nicely with other pieces of your Docker infrastructure?
Do you want to bet on one orchestrator, hedge with a mainstream one, or just sit it out until you have to make a decision?
Operating System
Enterprise operating systems can lag behind the latest and greatest.
Is your standard OS capable of supporting all the latest features? For example, some orchestrators and Docker itself require kernel versions or packages that may be more recent than is supported. This can come as a nasty surprise…
Which version of Docker is available in your local package manager?
Development
Dev environments
Developers love having admin. Are you ready to effectively give them admin with Docker?
Are their clients going to be consistent with deployment? If they’re using docker-compose, they might resent switching to pods in production.
CI/CD
Jenkins is the most popular CI tool, but there’s other alternatives popular in the enterprise.
What’s your policy around CI/CD plugins?
Are you ready to switch on a load of new plugins PDQ?
Does your process for CI cater for ephemeral Jenkins instances as well as persistent, supported ones?
Infrastructure
Shared Storage
Docker has in its core the use of volumes that are independent of the running containers, in which persistent data is stored.
Is shared storage easy to provision?
Is shared storage support ready for increased demand?
Is there a need for shared storage to be available across deployment locations?
Networking
Enterprises often have their own preferred Software Defined Networking solutions, such as Nuage, or new players like Calico.
Do you have a prescribed SDN solution?
How does that interact with your chosen solutions?
Does SDN interaction create an overhead that will cause issues?
aPaaS
Having an aPaaS such as OpenShift or Tutum Cloud can resolve many of the above questions by centralising and making supportable the context in which Docker is run.
Have you considered using an aPaaS?
Which one answers the questions that need answering?
Cloud Providers
If you’re using a cloud provider such as Amazon or Google:
How do you plan to deliver images and run containers on your cloud provider?
Do you want to tie yourself into their Docker solutions, or make your usage cloud-agnostic?
Recently I’ve become responsible for a large project with lots of branches and a complex history I frequently need to dig into. I prefer to work on the command line, so ended up exploring various git log options.
I haven’t found a good write-up of these, so here is my attempt at sharing one with you.
tl;dr
I use this alias everywhere:
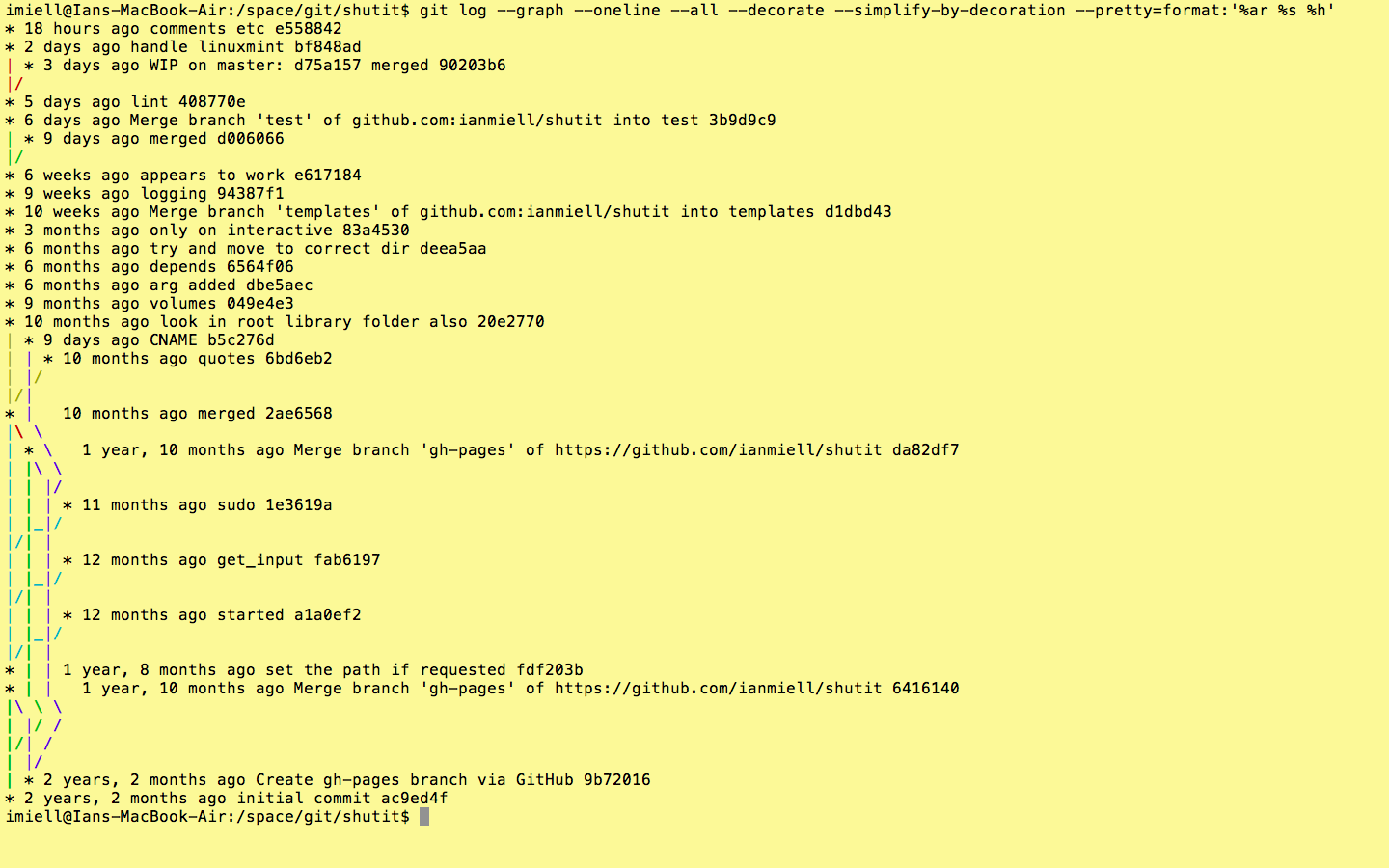
alias gitgraph="git log --graph --oneline --all --decorate --topo-order"
git log
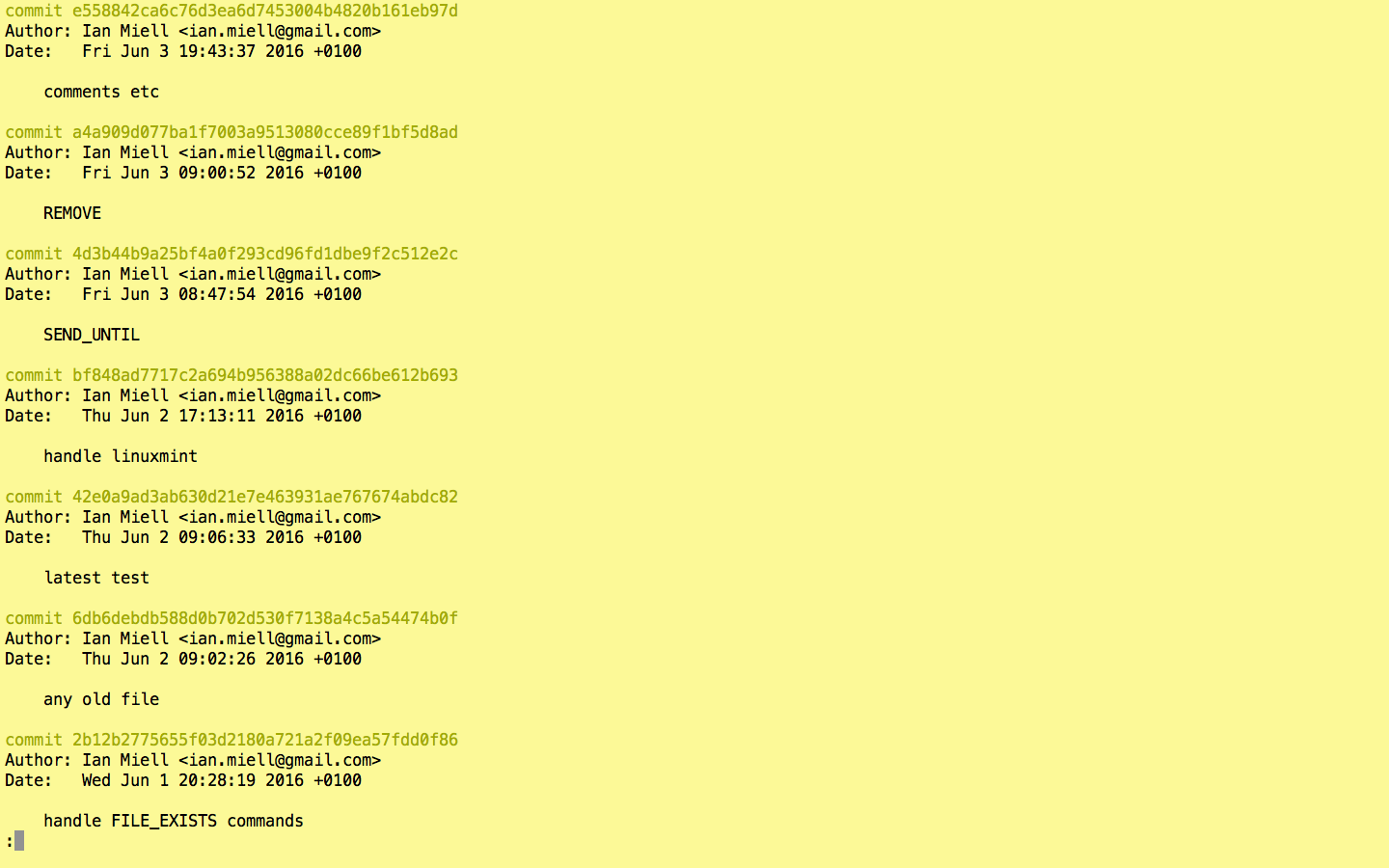
In case you’re not familiar with it already, the command to show the history from your current point is:
git log
The output is most-recent commit first, down to the oldest.
–oneline
Most of the time I don’t care about the author or the date, so in order that I can see more per screen, I use –oneline to only show the commit id and comment per-commit.
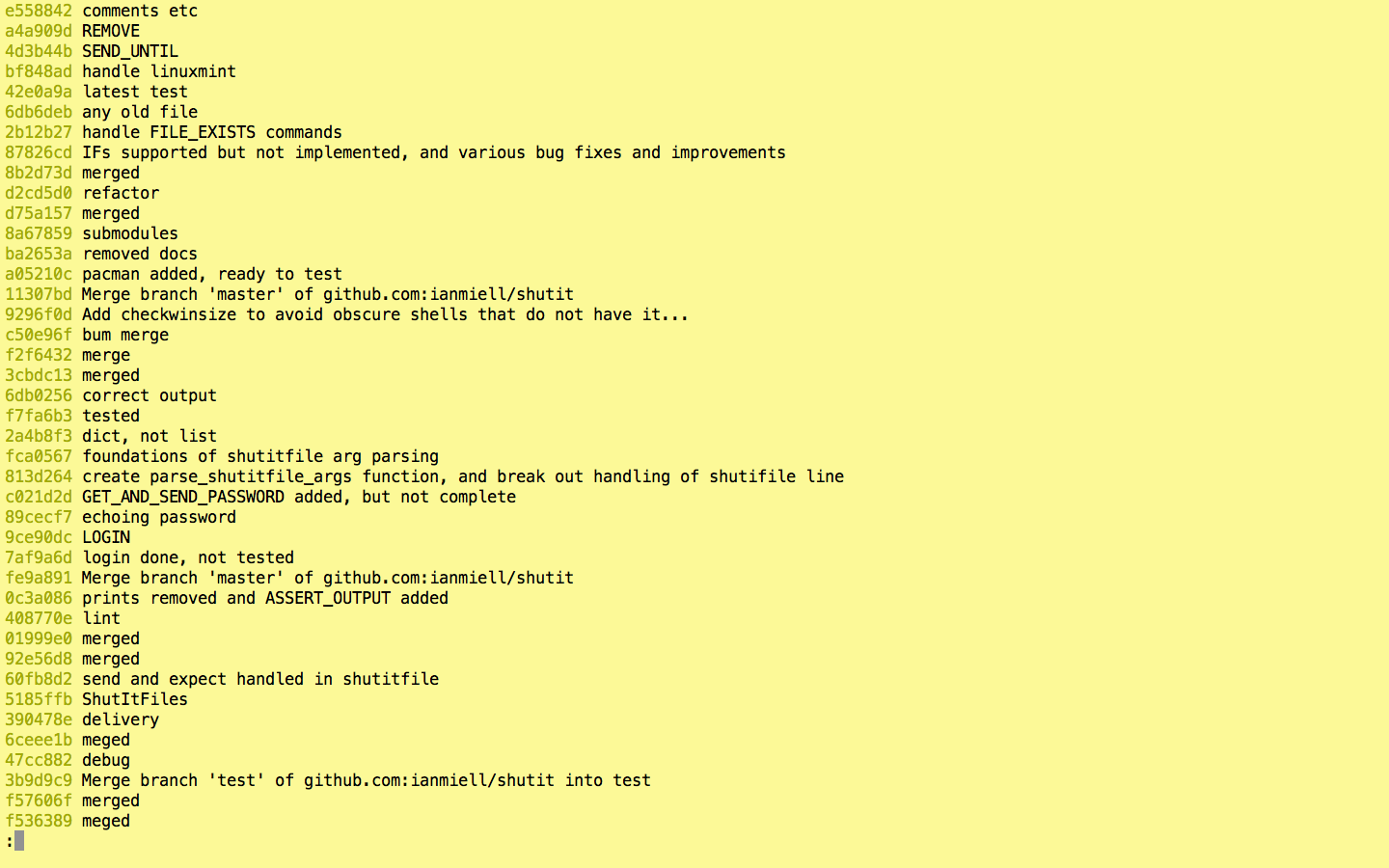
git log --oneline
–graph
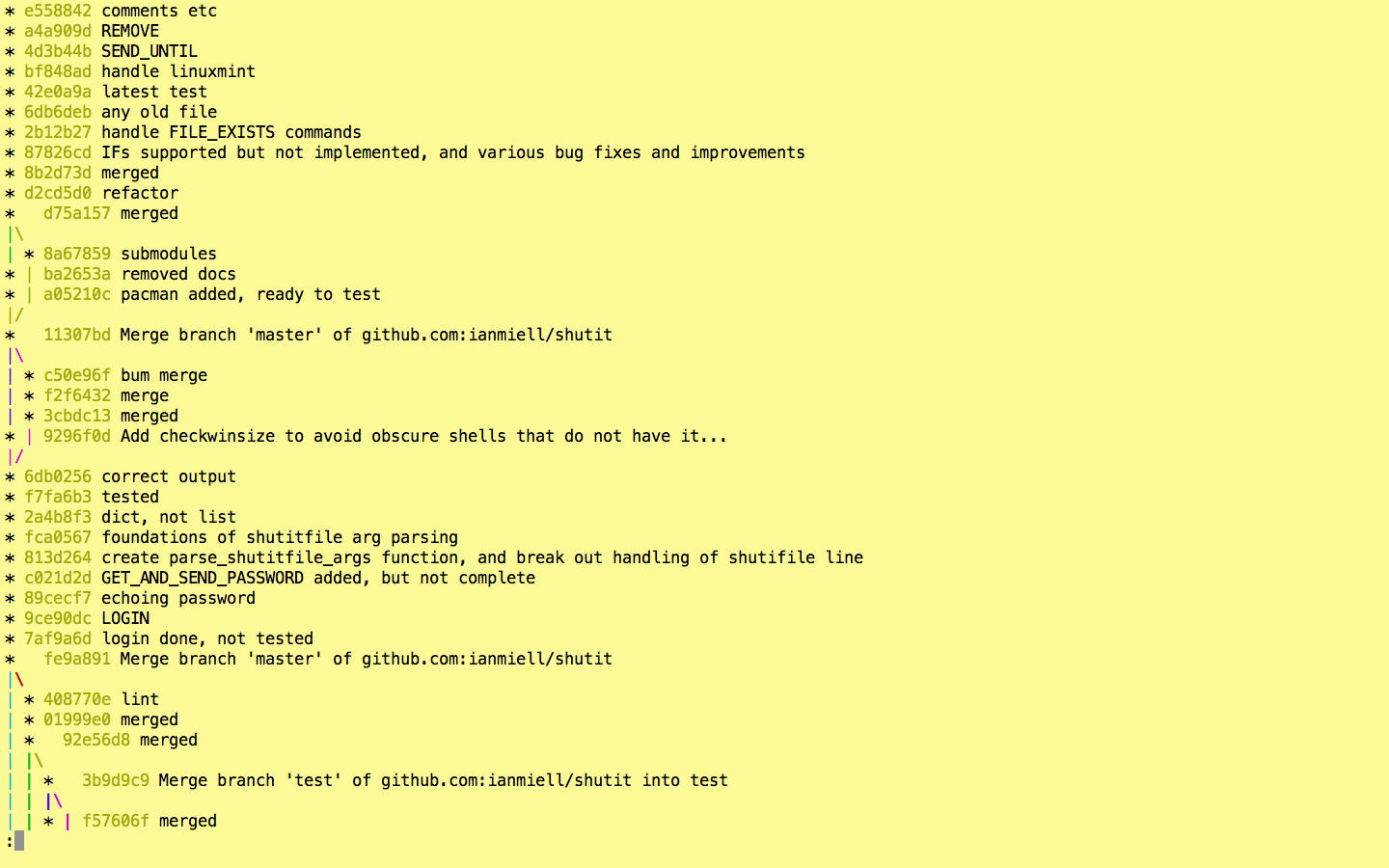
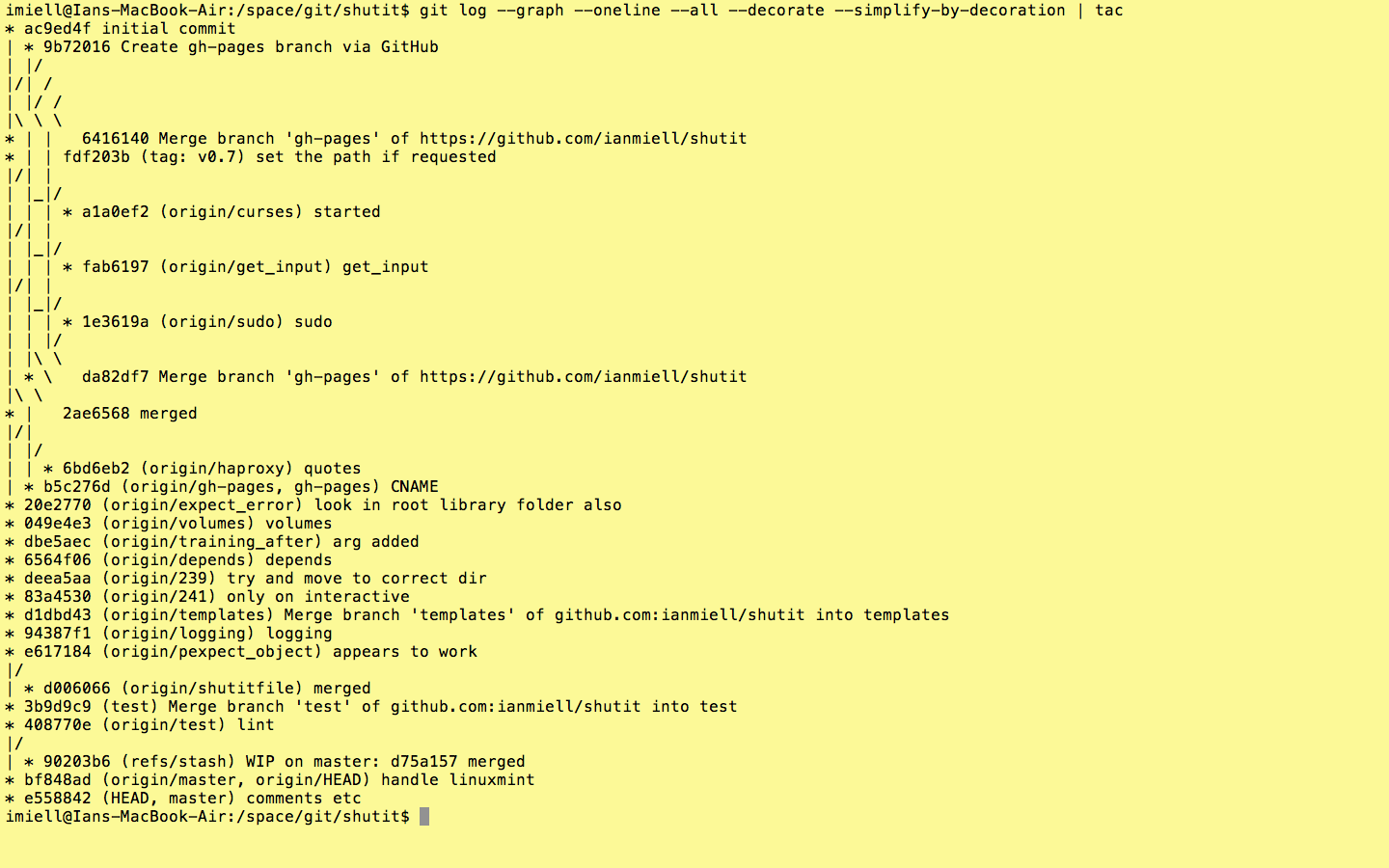
The problem with the above is that you only see a linear series of commits, and get no sense of what was merged in where. To see this aspect of the history use –graph.
git log --oneline --graph
You can see where merges take place, and what commits were merged.
–all
By default you only get the history leading up to the HEAD (ie where you are currently in the git history. Often I want to see all the branches in the history, so I add the –all flag.
git log --graph --oneline --all
–decorate
That’s great, but I can’t see what branch is where! This is where you use –decorate.
git log --graph --oneline --all --decorate
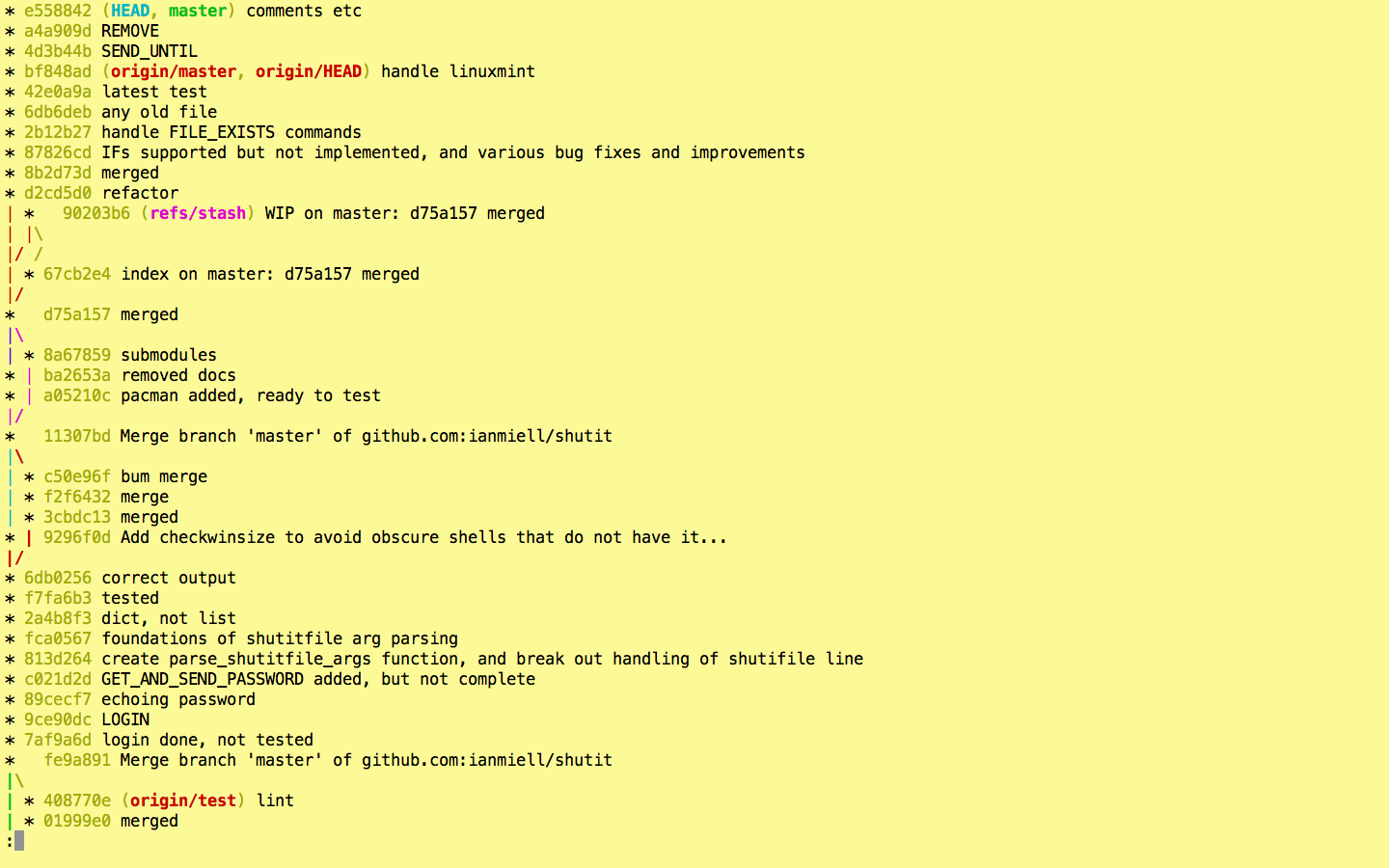
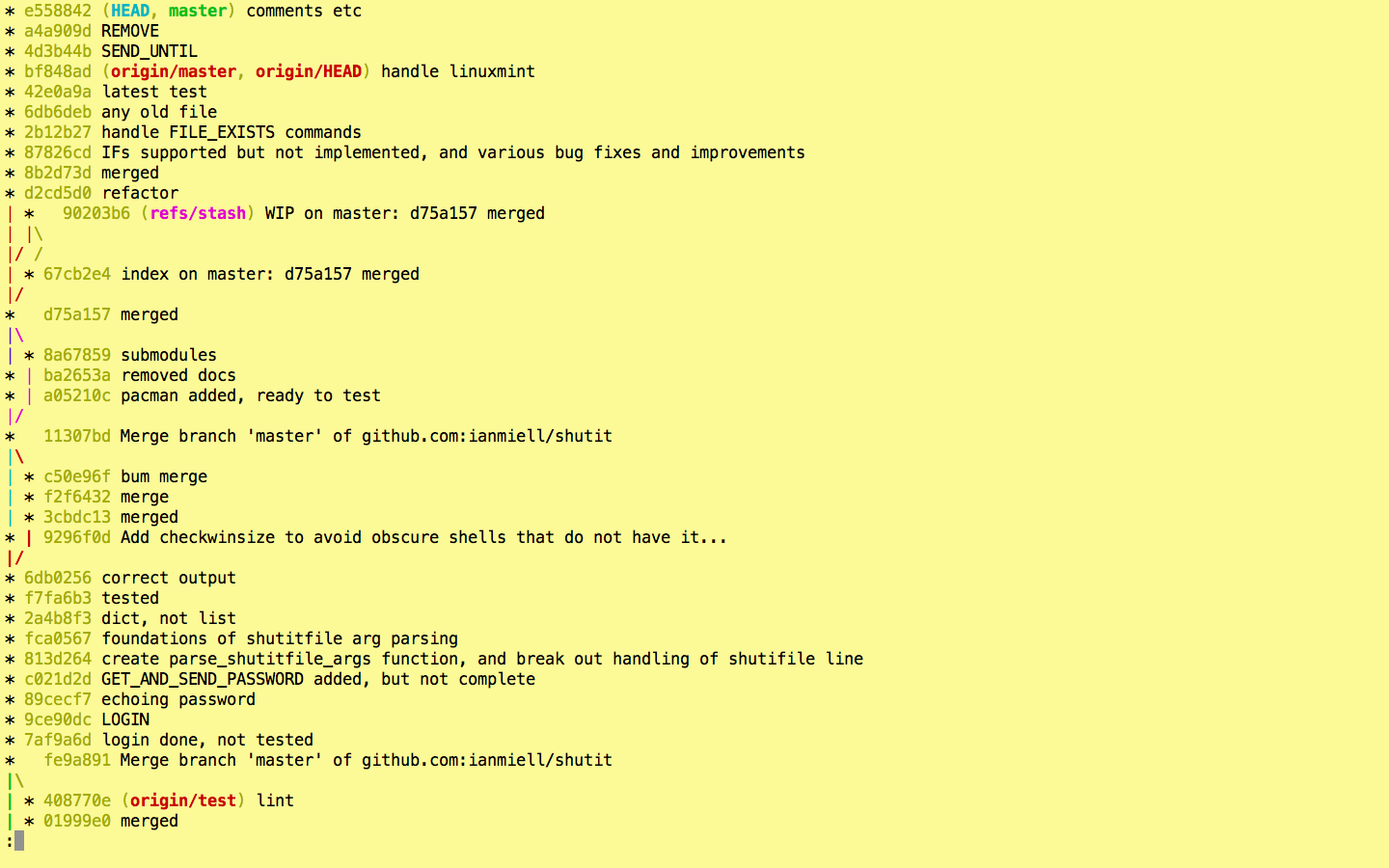
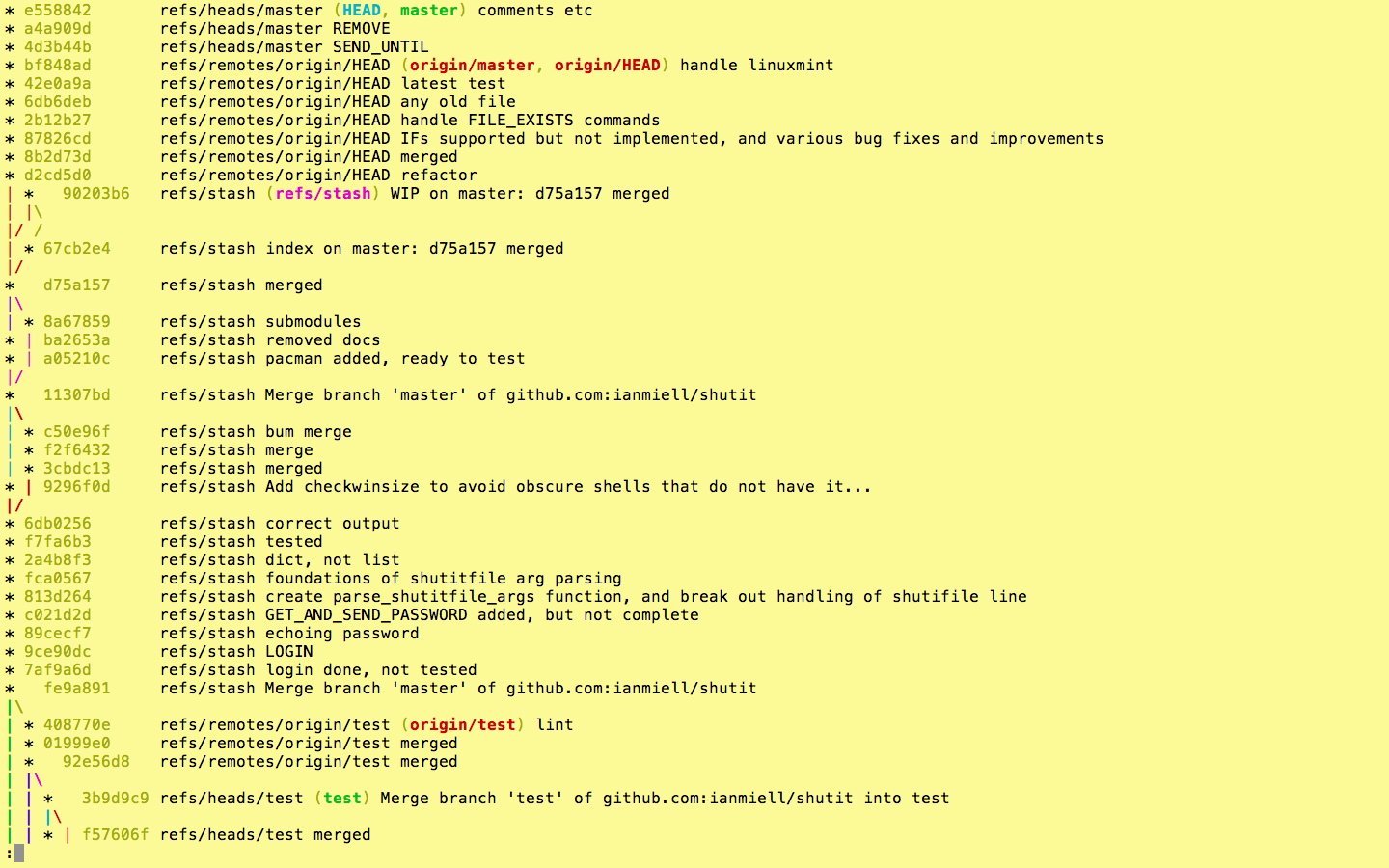
Now we’re cooking with gas! Each remote or type of branch/tag is shown in a different colour (even stashes!). On my terminal, remotes are in red, HEAD is blue, local branches are in green, stashes in pink.
If you want, you can show the ref name on each line by adding –source, but I usually find this to be overkill:
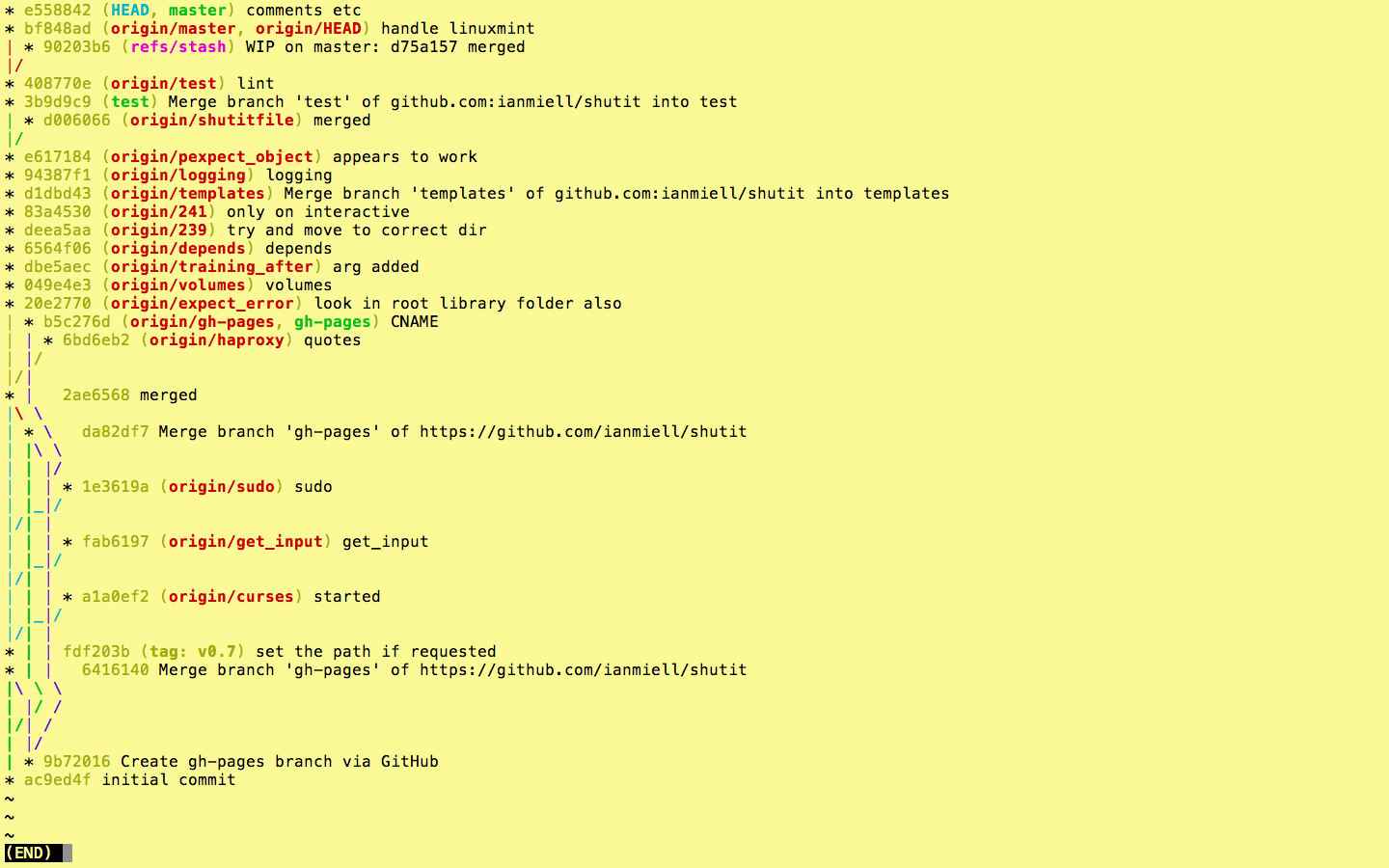
If you’re looking at the whole history of your project, you may want to see only the significant points of change (ie the lines affected by –decorate above) to eliminate all the intermediary commits. This is perfect for getting an overview of the project as a whole.
The order in which commits are displayed. Although it appears to be the default, it’s worth knowing that –topo-order shows commits ‘bunched together’ by topic, rather than in date order. This leads to easier-to-read graphs in complex projects.
About once every few months I have to set up a reverse tunnel.
I’ve learned the hard way to not read the man page, and just wing it.
After setting one up the other day I looked at the man page to see if it made sense whilst having a picture of its operating still in my mind.
*-R* [bind_address:]port:host:hostport
Specifies that the given port on the remote (server) host is to be forwarded to the given host and port on the local side.
This works by allocating a socket to listen to port on the remote side, and whenever a connection is made to this port, the connec-tion is forwarded over the secure channel, and a connection is made to host port hostport from the local machine.
We all got that, right?
Break it down
OK, maybe I just wasn’t paying close enough attention, so I’m going to read it carefully and take notes while doing so:
The given port [which given port? port? or hostport?] on the remote (server) [hang on, which is the remote/server here? is it the ‘host’?] host [ok, so the remote/server is ‘host’ here? maybe? that would mean that host == server == remote?] is to be forwarded to the given hostand port on the local side [which port? same as previously mentioned port? does that mean the previously-mentioned port is the hostport? what’s the ‘local side’ here? local to where I ssh to? or local to where I run ssh?]
At this point I’m basically crying.
This works [so we presumably understand what’s going on by this point!] by allocating a socket to listen to port on the remote side [which is the remote side?], and whenever a connection is made to this port [ah, does this mean it’s the port on the machine I connect to (ie the ‘port’)?], the connection is forward over the secure channel, and a connection is made to host port hostport [wtf? ok, just ignore ‘host port’ there. I think we might be able to conclude that hostport is the port we are forwarding to, and the host is the host of the hostport] from the local machine [ok, now I think that the local machine is the machine we log onto. I hope that’s right].
Understand it Visually
A – Your ssh -R command connects to the ‘fromhost’. The ‘fromhost’ is the host from which you want to connect to the server.
B – Your ssh -R command connects to the server on the serverport
C – The port that was allocated on the ‘fromhost’ accepts tcp requests, and passes the data to the server:serverport via the intermediary host on which ssh -R was run.
I hope this helps someone.
Please tweet any corrections or comments to: @ianmiell
Seventeen months after signing the contract, I hold our book in my hands!
A lot of people have asked me about our experiences writing the book, whether it was ‘worth it’, how much work it was, whether I’d do it again, and should they do one.
I remember googling this before I started, so thought it would be good to pay forward my experiences for the benefit of others.
Why write a book?
It’s good to think about why you want to write a book before starting. Reasons include:
Vanity
Recognition
Money
Career development
Communicating your ideas
Learning about the technology!
None of these are good or bad reasons in themselves.
Vanity and recognition (seeing your name in print, being able to put ‘published author’ on your LinkedIn profile, being able to say ‘I’ve published a book on that’) can be a great motivator to keep going when things get tough, however shallow.
We all need money to live, but it’s no secret that writing a book will not make you rich. That doesn’t mean there aren’t material benefits though! You will get paid if it sells, but it’s not going to be enough in itself to make the hardship worthwhile, and will never be guaranteed. If you want money, market yourself as a consultant and make real money faster.
Secondary Benefits
The secondary benefits are where writing a book really excels. These can include:
Conference invites
Professional respect
Improved networking
Career enhancement
In a way, writing a book is like joining a professional club. The editor that persuaded me to write said ‘writing a book will put you into a different professional category’ and that has certainly been my experience.
Conferences can be fun, and you will come into contact with lots of people you would not normally meet. You can also validate your ideas while you write the book.
Learning
Whisper it, but writing a book will force you into corners of the technology you might not otherwise look into. In other words, you learn about it! I thought I knew a lot about Docker before I started, but writing a book forced me to up my game. Nothing focusses the mind like knowing that another ‘expert’ will be paid to go over your book with a fine-toothed comb and write brutal feedback!
As another secondary benefit, when you write a book, people ask you questions – a valuable way to gain intelligence about what’s going on in the field!
Communicating your ideas
A book is a great mouthpiece for you. You can take the time to give the benefits of your experience.
Publishers want to know this before taking you on as an author:
You know what you’re talking about
You have a strong idea what you want to write about
You are committed to completing the work
You are able and want to communicate
Have a table of contents prepared. Don’t worry if it’s not perfect, the fact that you have something will put you far ahead of the competition, and help convince the publisher you’re serious. They will help you improve it anyway.
This will change a lot as you write, but by knowing the shape of the book in advance – and knowing what you want to say – you will save a lot of time and effort.
I started by giving talks at meetups, which I highly recommend for all sorts of reasons, but having a video of me communicating to my peers ticked a lot of these boxes for my publisher.
A good publisher
Get a good publisher. It’s worth far more than a few percent more on the book’s sales.
A good publisher provides:
Planning, support and advice
Editing expertise and mentoring
Proof-reading iterations
Technical proofreading
Peer review
Marketing
Indexing
Illustration
Layout
Printing
Distribution
Branding
That’s quite a list! You can self-publish if you want, and you will make a bigger cut, but you will have to do a lot more work to sell each copy.
Manadatory Credit: Photo by Brian Rasic / Rex Features (396812dh) PRINCE VARIOUS
Maybe the time will come that I write ‘SLAVE’ on my face, but I can always self-publish at that point and save on marker pen ink.
In fact, I had a look at some self-published technical books in preparation for this article, and could very quickly see flaws not in contentbut definitely in copy, approach, style and design. All things the Manning team saved me from.
I have nothing but good things to say about the team at Manning, who had a very efficient team which supported and pushed us to make a better (and a better-selling) book. And we learned a lot about the publishing industry through writing it.
For example, about 20% of the writing time was spent getting the first chapter right. We went over it again and again until we’d learned the lessons we needed to. After that, the subsequent chapters came out pretty easily.
Time and space
It’s no surprise that writing book is time-consuming, but there are some subtleties beyond this to consider.
Simply taking 30 minutes every day to ‘work on the book’ is not enough. That will work for writing linking snippets or bits of proofing or testing, but will need stretches of many hours to do the real meat of the work. I would take myself off to the libraries for many stretches to focus on sections of the book that required real thought.
For example, I spent more time than I care to relate trying to get Kubernetes set up at home when it was still in its infancy. In retrospect this was a massive waste of time! But quite valuable in other ways – I learned a lot about the product, and even got into contact with the lead Kubernetes developer.
I was lucky in that I had two months between jobs, so I wrote and explored London, which was a fantastic life experience and a lot of fun. If I were to write a book again I would probably quit work and devote myself to it full-time. It’s less profitable, but getting the focus full-time would make life a lot easier and fun.
Get a co-author
I would seriously recommend getting a co-author. The benefits are numerous:
Sanity check on content and direction
50% of the work is taken off your hands
You still retain control where you want it
But not at any cost. I was lucky with my co-author – the work divided up nicely between us, and our skills complemented each other nicely. If you don’t trust someone, don’t sign up with them, as the process can get stressful if you let it.
I would have to think very carefully about going through this process again on my own.
Ability to write (and draw!)
Sounds obvious, but you will need to be able to write. I was lucky that I’d had some professional writing experience, but when you write in a commercial niche there’s more to learn about what works and what doesn’t.
If you can’t write already, be prepared to listen and learn. A good editor will give robust feedback, and tell you clearly where you need to improve.
And get good at doing diagrams. They don’t need to be polished, but diagrams are increasingly important in successful technical books.
When you see tweets like this it makes it all that effort worthwhile.
Ability to market
Although publishers provide marketing for you, you should be willing to work on this side of things as well. You should know what topics are of interest to people, and the marketing team will be very grateful if you feed them useful content.
Still want to do it?
Feel free to contact me if you want more advice or have any questions!