
Overview
Before we get going with Kubernetes, it’s a good idea to get a picture of Kubernetes’ high-level architecture.

Kubernetes has a master-minion architecture. Master nodes are responsible for receiving orders about what should be run on the cluster and orchestrating its resources. Each minion has Docker installed on it, and a ‘kubelet’ service, which manages the pods (sets of containers) running on each node. Information about the cluster is maintained in etcd, a distributed key-value data store, and this is the cluster’s source of truth.
What’s a Pod?
We’ll go over it again later in this article, so don’t worry about it so much now, but if you’re curious, a pod is a grouping of related containers. The concept exists to facilitate simpler management and maintenance of Docker containers.
The end goal of Kubernetes is to make running your containers at scale a simple matter of declaring what you want and letting Kubernetes take care of ensuring the cluster achieves your desires. In this technique you will see how to scale a simple service to a given size by running one command.
Why was Kubenetes built?
Kubernetes was originally developed by Google as a means of managing containers at scale. Google has been running containers for over a decade at scale, and decided to develop this container orchestration system when Docker became popular. It builds on the lessons learned from this extensive experience. It is also known as ‘K8s’.
Installation
To install Kubernetes you have a choice. You can either install directly on your host, which will give you a single-minion cluster, or use Vagrant to install a multi-minion cluster managed with VMs.
To install a single-minion cluster on your host, run:
export KUBERNETES_PROVIDER=vagrant
curl -sS https://get.k8s.io | bash
Latest instructions here
If you want to install a multi-minion cluster, you have another choice. Either follow the instructions on the Kubernetes GitHub repository (see ‘Latest instructions’ above) for Vagrant, or you can try an automated script maintained by me which sets up a two-minion cluster: see here
If you have Kubernetes installed you can follow along from here. The following output will be based on a multi-node cluster. Next we’re going to start simply by creating a single container and using Kubernetes to scale it up.
Scaling a Single Container
You can start up a pod from an image stored on the Docker Hub with the ‘run-container’ subcommand to kubectl.
The following command starts up a pod, giving it the name ‘todo’, and telling Kubernetes to use the dockerinpractice/todo image from the DockerHub.
$ kubectl run-container todo --image=dockerinpractice/todo
Now if you run the ‘get pods’ subcommand you can list the pods, and see that it’s in a ‘Pending’ state, most likely because it’s downloading the image from the Docker Hub
$ kubectl get pods | egrep "(POD|todo)"
POD IP CONTAINER(S) IMAGE(S) HOST LABELS STATUS CREATED MESSAGE
todo-hmj8e 10.245.1.3/ run-container=todo Pending About a minute
After waiting a few minutes for the todo image to download, you will eventually see that its status has changed to ‘Running’:
$ kubectl get pods | egrep "(POD|todo)"
POD IP CONTAINER(S) IMAGE(S) HOST LABELS STATUS CREATED MESSAGE
todo-hmj8e 10.246.1.3 10.245.1.3/10.245.1.3 run-container=todo Running 4 minutes
todo dockerinpractice/todo Running About a minute
This time the ‘IP’, ‘CONTAINER(S)’ and ‘IMAGE(S)’ columns are populated. The IP column gives the address of the pod (in this case ‘10.246.1.3’), the container column has one row per container in the pod (in this case we have only one, ‘todo’). You can test that the container (todo) is indeed up and running and serving requests by hitting the IP address and port directly:
$ wget -qO- 10.246.1.3:8000
[...]
Scale
At this point we’ve not seen much difference from running a Docker container directly. To get your first taste of Kubernetes you can scale up this service by running a resize command:
$ kubectl resize --replicas=3 replicationController todo
resized
This command has specified to Kubernetes that we want the todo replication controller to ensure that there are three instances of the todo app running across the cluster.
What is a replication controller?
A replication controller is a Kubernetes service that ensures that the
right number of pods are running across the cluster.
$ kubectl get pods | egrep "(POD|todo)"
POD IP CONTAINER(S) IMAGE(S) HOST LABELS STATUS CREATED MESSAGE
todo-2ip3n 10.246.2.2 10.245.1.4/10.245.1.4 run-container=todo Running 10 minutes
todo dockerinpractice/todo Running 8 minutes
todo-4os5b 10.246.1.3 10.245.1.3/10.245.1.3 run-container=todo Running 2 minutes
todo dockerinpractice/todo Running 48 seconds
todo-cuggp 10.246.2.3 10.245.1.4/10.245.1.4 run-container=todo Running 2 minutes
todo dockerinpractice/todo Running 2 minutes
Kubernetes has taken the resize instruction and the todo replication controller and ensured that the right number of pods are started up. Notice that it placed two on one host (10.245.1.4) and one on another (10.245.1.3). This is because Kubernetes’ default scheduler has an algorithm that spreads pods across nodes by default.
You’ve started to see how Kubernetes can make management of containers easier across multiple hosts. Next we dive into the core Kubernetes concept of pods.
Pods
A pod is a collection of containers that are designed to work together in some way that share resources.
Each pod gets its own IP address, and shares the same volumes and network port range. Because a pod’s containers share a ‘localhost’, the containers can rely on the different services being available and visible wherever they are deployed.
The following figure illustrates this with two containers that share a volume.
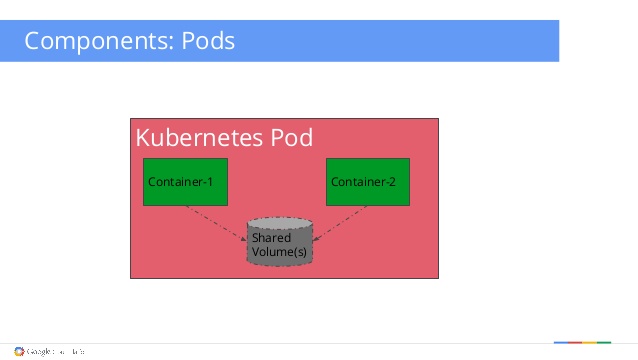
In the above figure Container1 might be a webserver that reads data files from the shared volume which is in turn updated by Container2. Both containers are therefore stateless, while state is stored in the shared volume.
This facilitates a microservices approach by allowing you to manage each part of your service separately, allowing you to upgrade one image without needing to be concerned with the others.
The following Pod specification defines a complex pod that has a container that writes random data (simplewriter) to a file every five seconds, and another container that reads from the same file (simplereader). The file is shared via a volume (pod-disk).
{
"id": "complexpod",
"kind": "Pod",
"apiVersion": "v1beta1",
"desiredState": {
"manifest": {
"version": "v1beta1",
"id": "complexpod",
"containers": [{
"name": "simplereader",
"image": "dockerinpractice/simplereader",
"volumeMounts": [{
"mountPath": "/data",
"name": "pod-disk"
}]},{
"name": "simplewriter",
"image": "dockerinpractice/simplewriter",
"volumeMounts": [{
"mountPath": "/data",
"name": "pod-disk"
}]
}],
"volumes": [{
"name": "pod-disk",
"emptydir": {}
}]
}
}
}
Have a look at the pod specification above. The mount path is the path to the volume mounted on the filesystem of the container. This could be set to a different location for each container. The volume mount name refers to the matching name in the pod manifest’s
‘volumes’ definition. The ‘volumes’ attribute defines the volumes created for this pod. The name of the volume is what’s referred to in the volumeMounts entries above. ’emptydir’ is a temporary directory that shares a pod’s lifetime. Persistent volumes are also available.
To load this pod specification in create a file with the above listing in run:
$ kubectl create -f complexpod.json
pods/complexpod
After waiting a minute for the images to download, you can see the log output of the container by running the ‘kubectl log’ and specifying first the pod and then the container you are interested in.
$ kubectl log complexpod simplereader
2015-08-04T21:03:36.535014550Z '? U
[2015-08-04T21:03:41.537370907Z] h(^3eSk4y
[2015-08-04T21:03:41.537370907Z] CM(@
[2015-08-04T21:03:46.542871125Z] qm>5
[2015-08-04T21:03:46.542871125Z] {Vv_
[2015-08-04T21:03:51.552111956Z] KH+74 f
[2015-08-04T21:03:56.556372427Z] j?p+!
What Next
We’ve just scratched the surface of Kubernetes’ capabilities and potential here, but this should give a flavour of what can be done with it, and how it can make orchestrating Docker containers simpler.











{kind=link}