In this section we introduce the most-frequently used feature of jq: the filter. Filters allow you to reduce a given stream of JSON to another smaller, more refined stream of JSON that you can then do more filtering or processing on on if you want.
How Important is this Post?
Filters are fundamental to using jq, so this post’s content is essential to understand.
We will cover:
The most commonly-used filters
Selecting values from a stream of JSON
Railroad diagrams, and how arrays cannot contain name-value pairs in JSON
This file contains a simple JSON object with two name-value pairs (user1, and user2 being the names, and alice and bob being their values, respectively).
The Dot Filter
The concept of the filter is central to jq. The filter allows us to select those parts of the JSON document that we might be interested in.
The simplest filter – and one you have already come across – is the ‘dot’ filter. This filter is a simple period character (.) and doesn’t do any selection on the data at all:
$ jq . json_object
Note that here we are using the filename as the last argument to jq, rather than passing the data through a UNIX pipe with cat.
Arrays, Name-Value Pairs, and Railroad Diagrams
Now let’s try and create a similar array with the same name-value pairs, and run the dot filter against it:
Was that what you expected? When I ran this I expected it to just work, based on my experiences of data structures in other languages. But no. Arrays in JSON cannot contain a name-value pair as one of its values – it’s not a JSON object, and arrays must be composed of JSON objects.
What can an array contain? Have a look at this railroad diagram, from https://json.org/:
The above diagram defines what an array consists of. Make sure you understand how to read the diagram before continuing, as being able to read such diagrams is useful in many contexts in software development.
Railroad Diagram
A railroad diagram is also known as a syntax diagram.
It visually defines the syntax for a particular language
or format. As your code or document is read, you can
follow the line,choosing which path to take as it splits.
If your code or document can be traced through the
'railroad', then it is syntactically correct. As far as I can
tell, there is no 'official' format for railroad diagrams
but the conventional signs can easily be found
and deciphered by searching online for examples.
The ‘value’ in the array diagram above is defined here:
Following the value diagram, you can see that there is no ‘name-value’ pair defined within a value. Name-value pairs are defined in the object railroad diagram:
A JSON object consists of zero or more name-value pairs, separated by commas, making it fundamentally different from an array, which contains only JSON values separated by spaces.
It’s worth understanding these diagrams, as they can help you a lot as you try and create and parse JSON with jq. There are further diagrams on the https://json.org site (string, number, whitespace). They are not reproduced in this section, as you only need to reference them in the rarer cases when you are not sure (for example) whether something is a number or not in JSON.
Let’s say we want to know what user2‘s value is in this document. To do this, we need a filter that outputs only the value for a specific name.
First, we can select the object, and then select by name:
$ jq '.user2' json_object
This is our first proper query with jq. We’ve filtered the contents of the file down to the information we want.
In the above we just put the bare string user2 after the dot filter. jq accepts this, but you can also refer to the name by placing it in quotes, or placing it in quotes inside square brackets:
However, with the square brackets and without the quotes does not work:
$ jq '.[user2]' json_object
This is because the [""] form is the official way to look up a name in an object. The simpler .user2 and ."user2" forms we saw above are just a shorthand for this, so you don’t need the four characters of scaffolding ([""]) around the name. As you are learning jq it may be better to use the longer form to embed the ‘correct’ form in your mind.
Types of Quote Are Important
It’s important to know that the types of quote you use in your JSON are significant to jq. Type this in, and think about how it is different to the ‘non-broken’ json above.
The various allowed forms for performing the selection
The syntactic difference between an object, an array, and a name-value pair
The types of quote are important
Exercises
1) Create another json_array file as per this section, but this time with two JSON objects (ie the same line twice). Re-run the queries above and see what happens to demonstrate that jq works on a stream of JSON objects.
This section introduces you to the jq command, starting with the simplest possible commands as well as a brief look at the most commonly-used flags.
What is jq?
jq is a program for parsing, querying, and manipulating JSON. More broadly, it’s a filter: it takes input and transforms it to output.
It can help you programmatically answer questions like:
How many AWS VMs does my account have?
How many of these VMs were created before last week?
What is the running status of these older VMs?
What is the list of VMs that have the tag ‘sales’, were created before last week, and are still running?
Before jq existed, the most common way to work out these things would be to use older command-line tools such as sed, awk, or programming languages like Python or perl. These could be highly sensitive to changes in input, difficult to maintain, prone to error, and slow. jq is much more elegant.
However, jq can be difficult for the uninitiated to understand and is more often used than understood. This book aims to help with that, to the point where you can confidently come up with your own solutions to challenges you face at work.
Invoking jq
Let’s get our hands dirty with jq.
Run this on your terminal:
$ echo '{}' | jq
This is the simplest JSON document you can pass to jq. The output of the echo command is piped into the jq command, which reads the output and ‘pretty-prints’ the JSON received for you because it’s going to the terminal rather than a file or another program. In this case, the input looks the same as the output, but the ‘pretty-printing’ involves emboldening the braces.
$ echo '{}' | jq
Input to jq
jq takes a stream of JSON documents as input. This input can be via a pipe like this:
It’s really important to understand that jq does not take a single JSON document as input (although it can). According to the documentation, it takes ‘a stream of JSON entities’.
What does this mean in practice? It means that if you run this:
$ echo '{}[]' | jq
you have just seen jq process ‘a stream of JSON entities’. What you inputted to jq was not valid JSON. If you want to prove this to yourself, just plug in {}[] to a JSON-parsing website (easily Google-able) or run this:
$ echo '{ {}[] }' | jq
The above just enclosed the ‘stream of JSON’ within a single JSON object (the surrounding {}), and jq throws an error, because what’s inside the single JSON object, ie:
{}[]
is not itself a single valid JSON document.
Two jq Flags
The jq command has a number of flags which are useful to know about. At this stage of the book we’re just going to look at two, as to list them all would overwhelm you. These are the two I have seen used most often.
The -r Flag
The first is most often used in quick scripts and shell pipelines. All it does is remove the quotes from the items in the output. For example, just passing in a string to jq will output the string with the quotes surrounding it:
$ echo '"asd"' | jq
Adding the -r flag removes the quotes:
$ echo '"asd" "fgh' | jq -r
The -S Flag
The second flag sorts fields in JSON objects. In this first example, the a and b items are output in the same order they were input:
$ echo '{"b":0,"a":0}' | jq
Adding the -S flag sorts them by their key:
$ echo '{"b":0,"a":0}' | jq -S
In this simple example the value of sorting these fields is not so clear, but if you have huge JSON document to look through, then knowing this flag is a simple way to save lots of time hunting through screen after screen full of data.
This jq series has been written to help users to get to a deeper understanding and proficiency in jq. It doesn’t aim to make you an expert immediately, but you will be more confident about using it and building your knowledge up from that secure base.
You may well have already played with jq a little – maybe been given a jq command to run by someone else, found a useful one-liner from StackOverflow, or hacked something together quickly that ‘does the job’, but without really understanding what you did. While that’s a great way to get going, a guided course that shows you how the pieces fit together by using it really helps you go further. Understanding these pieces enable you to more creative, solving your own challenges in ways that work for your problem domain.
Why ‘The Hard Way’?
The ‘Hard Way’ is a method that emphasises the process required to learn anything. You don’t learn to ride a bike by reading about it, and you don’t learn to cook by reading recipes. Content can help (hopefully, this does) but it’s up to you to do the work.
This book shows you the path in small digestible pieces and tells you to actually type out the code. This is as important as riding a bike is to learning to ride a bike. Without the brain and the body working together, the knowledge does not properly seep in.
Before we get hands on with jq, it’s important to know what JSON is, and what it is not.
In this post, we cover:
What JSON is
Look at examples of it
Introduce key terms
Briefly look at its place in the software landscape
Why Should I Read This Post?
This is an introductory post, but an important one.
Even if you’ve seen JSON before, I strongly encourage you to read over this. The reason for that is that getting a clear grasp of the terminology will help enormously when reading jq docs later. In fact, a good working understanding of the terminology is the best way to avoid confusion when using jq.
What Is JSON?
JSON is a ‘data interchange format’. This is a fancy way of saying that is a standardised way to write information and send it to other entities who can understand what it means.
You might have heard of (or even used) other data-interchange formats, such as XML, CSV, Apache Parquet, YAML. Each of these formats has their benefits and disadvantages relative to each other. CSV is very simple and easily understood but is not very good at expressing complex nested information, and can be ambiguous in how it represents data. XML allows for very complex data to be encapsulated but can be verbose and hard for humans to parse. YAML is optimised for human readability, allowing comments and using whitespace rather than special characters to delimit.
JSON is ubiquitous for a few reasons. First, it is simple, being easily parsed by anyone familiar with standard programming languages. Second, it is natively understood by JavaScript, a very popular programming language in the IT industry. Third, it is widely parsed by many programming languages in easily available libraries.
The above JSON represents two departments of a workplace and their employees. The departments are in a ‘collection’ of name-value pairs. "accounting" and "sales" are the names, and the values are an ordered list of name-value pairs (an ordered list is known as an array).
Anything enclosed within a pair of curly braces (‘{‘ and ‘}‘) is an object. Anything enclosed within a pair of square braces (‘[‘ and ‘]‘) is an array.
It might sound theoretical, but it’s really important that you understand the above terminology, or at least understand that it’s important. Most jq documentation makes these distinctions carefully, and some use them wrongly, or loosely. This can cause great confusion. When you look at JSON as you read this book, be sure you can explain what it is in clear and correct terms to yourself and others.
The format is flexible, allowing items within an object to have different name-value pairs. Here, the “building” name is in Celia’s and Alice’s entry, but not in Jim’s or Bob’s.
A JSON document can be an object or an array. Here is the same document as above, but in an array rather than an object.
In this document, the departments are in a specific order, because they are placed in an array rather than in an object.
In the above passage, the key terms to grasp are:
Name
Value
Name-value pairs
Object
Array
We will cover these in more depth later in this series, but for now just be aware that these names exist, and that understanding them is key to getting to mastery of jq.
Natively Understood By Javascript
JSON arose from Javascript’s need for a way to communicate between processes on different hosts in an agreed format. It was established as a standard around the turn of the century, and any Javascript interpreter now understands JSON out of the box.
Used By Many Languages
JSON is not specific to JavaScript. It was invented for JavaScript, but is now a general-purpose format that is well-supported by many languages.
Here is an example of an interactive Python session parsing a simplified version of the above JSON into a Python dictionary.
Many engineers today make extensive use of YAML as a configuration language. JSON and YAML express very similar document content, but they look different. YAML is easier for humans to read than JSON, and also allows for comments in its documents.
Technically, JSON can be converted into YAML without any loss of information. But this conversion cannot always go both ways. YAML has a few extra features, such as ‘anchors’ that allow you to reference other items within the same document, which can make converting back to JSON impossible.
JSON Can Be Nested
JSON can have a nested structure. This means that any value within a JSON object or array can have the same structure as the whole document. In other words, every value could itself be a JSON document. So each of the the following lines are valid JSON documents:
{}
"A string"
{ "A name" : {} }
{ "A name" : [] }
and this one is not valid:
{ {} }
because there is no ‘value’ inside the JSON object.
This one is also not valid:
{ Thing }
because values that are strings need to be quoted (just as in JavaScript).
We will go into more detail on name-value pairs in an upcoming post.
Recently an Amazon Prime Video (APV) article about their move from serverless tools to ECS and EC2 did the rounds on all the tech socials. A lot of noise was made about it, initially because it was interpreted as a harbinger of the death of serverless technologies, followed by a second wave that lashed back against that narrative. This second wave argued that what had happened was not a failure of serverless, but rather a standard architectural evolution of an initial serverless microservices implementation to a ‘microservice refactoring’.
This brouhaha got me thinking about why, as an architect, I’ve never truly got onto the serverless boat, and what light this mini-drama throws on that stance. I ended up realising how Amazon and AWS had been at the centre of two computing revolutions that changed the computing paradigm we labour within.
Before I get to that, let’s recap the story so far.
The Story
The APV team had a service which monitored every stream viewed on the platform, and triggered a process to correct poorly-operating streams. This service was built using AWS’s serverless Step Functions and Lambda services, and was never intended to run at high scale.
As the service scaled, two problems were hit which together forced a re-architecture. Account limits were hit on the number of AWS Step Function transitions, and the cost of running the service was prohibitive.
In the article’s own words: ‘The move from a distributed microservices architecture to a monolith application helped achieve higher scale, resilience, and reduce costs. […] We realized that [a] distributed approach wasn’t bringing a lot of benefits in our specific use case, so we packed all of the components into a single process.’
The Reactions
There were more than a few commentators who relished the chance to herald this as the return of the monolith and/or the demise of the microservice. The New Stack led with an emotive ‘Amazon Dumps Microservices’ headline, while David Heinemeier Hansson, as usual, went for the jugular with ‘Even Amazon Can’t Make Sense of Serverless or Microservices’.
After this initial wave of ‘I told you so’ responses, a rearguard action was fought by defenders of serverless approaches to argue that reports of the death of the monolith was premature, and that others were misinterpreting the significance of the original article.
Adrian Cockroft, former AWS VP and well-known proponent of microservices fired back with ‘So Many Bad Takes – What Is There To Learn From The Prime Video Microservices To Monolith Story’, which argued that the original article did not describe a move from microservice to monolith, rather it was ‘clearly a microservice refactoring step’, and that the team’s evolution from serverless to microservice was a standard architectural pathway called ‘Serverless First’. In other words: nothing to see here, ‘the result isn’t a monolith’.
The Semantics
At this point, the debate has become a matter of semantics: What is a microservice? Looking at variousdefinitionsavailable, the essential unarguable point is that a microservice is ‘owned by a small team’. You can’t have a microservice that requires extensive coordination between teams to build or deploy.
But that can’t be the whole story, as you probably wouldn’t describe a small team that releases a single binary with an embedded database, a web server and a Ruby-on-Rails application as a microservice. A microservice implies that services are ‘fine-grained […] communicating through lightweight protocols’.
There must be some element of component decomposition in a microservice. So what is a component? In the Amazon Prime Video case, you could argue both ways. You could say that the tool is the component, and is a bounded piece of software managed by a small team, or you could say that the detectors and converters are separate components mushed into a now-monolithic application. You could even say that my imagined Ruby-on-Rails monolithic binary above is a microservice if you want to just define a component as something owned by a small team.
And what is an application? A service? A process? And on and on it goes. We can continue deconstructing terms all the way down the stack, and as we do so, we see that whether or not a piece of software is architecturally monolithic or a microservice is more or less a matter of perspective. My idea of a microservice can be the same as your idea of a monolith.
But does all this argumentation over words matter? Maybe not. Let’s ignore the question of what exactly a microservice or a monolith is for now (aside from ‘small team size’) and focus on another aspect of the story.
Easier to Scale?
The second paragraph of AWS’s definition of microservices made me raise my eyebrows:
‘Microservices architectures make applications easier to scale and faster to develop, enabling innovation and accelerating time-to-market for new features.’
Regardless of what microservices were, these were their promised benefits: faster to develop, and easier to scale. What makes the AVP story so triggering to those of us who had been told we were dinosaurs is that the original serverless implementation of their tool was ludicrously un-scalable:
We designed our initial solution as a distributed system using serverless components (for example, AWS Step Functions or AWS Lambda), which was a good choice for building the service quickly. In theory, this would allow us to scale each service component independently. However, the way we used some components caused us to hit a hard scaling limit at around 5% of the expected load.
and not just technically un-scalable, but financially too:
Also, the overall cost of all the building blocks was too high to accept the solution at a large scale.
To me, this doesn’t sound like their approach has made it ‘easier to scale’. Some, indeed, saw this coming:
Everyone is surprised Amazon Prime Video is ditching Lambda for a monolith.
I saw Lambda being born, and understood it inside out. I was never convinced it would become a suitable application host.
But what about the other benefit, that of being ‘faster to develop’? Adrian Cockroft’s post talks about this, and lays out this comparison table:
This is where I must protest, starting with the second line which states that ‘traditional’, non-serverless/non-microservices development takes ‘months of work’ compared to the ‘hours of work’ microservices applications take to build.
Anyone who has actually built a serverless system in a real world context will know that it is not always, or even usually, ‘hours of work’. To take one small example of problems that can come up: https://twitter.com/matthewcp/status/1654928007897677824
to which you might add: difficulty of debugging, integration with other services, difficulty of testing scaling scenarios, state management, getting IAM rules right… the list goes on.
You might object to this, and argue that if your business has approved all the cloud provider’s services, and has a standard pattern for deploying them, and your staff is already well versed in the technologies and how to implement them, then yes, you can implement something in a few hours.
But this is where I’m baffled. In an analogous context, I have set up ‘traditional’ three-tier systems in a minimal and scalable way in a similar time-frame. Much of my career has been spent doing just that, and I still do that in my spare time because it’s easier for me for prototyping to do that on a server than wiring together different cloud services.
The supposed development time difference between the two methods is not based on the technology itself, but the context in which you’re deploying it. The argument made by the table is tendentious. It’s based on comparing the worst case for ‘traditional’ application development (months of work) with the best case for ‘rapid development’ (hours of work). Similar arguments can be made for all the table’s comparisons.
The Water We Swim In
Context is everything in these debates. As all the experts point out, there is no architectural magic bullet that fits all use cases. Context is as complex as human existence itself, but here I want to focus on two areas specifically:
governance
knowledge
The governance context is the set of constraints on your freedom to build and deploy software. In a low-regulation startup these constraints are close to zero. The knowledge context is the degree to which you and your colleagues know how a set of technologies work. It’s assumptions around these contexts that make up the fault lines of most of the serverless debate.
Take this tweet from AWS, which approvingly quotes the CEO of Serverless:
“The great thing about serverless is […] you just have to think about one task, one unit of work”
I can’t speak for other developers, but that’s almost always true for me most of the time when I write functions in ‘traditional’ codebases. When I’m doing that, I’m not thinking about IAM rules, how to connect to databases, the big app, the huge application. I’m just thinking about this one task, this unit of work. And conversely, if I’m working on a serverless application, I might have to think about all the problems I might run into that I listed above, starting with database connectivity.
You might object that a badly-written three-tier system makes it difficult to write such functions in isolation because of badly-structured monolithic codebases. Maybe so. But microservices architectures can be bad too, and let you ‘think about the one task’ you are doing when you should be thinking about the overall architecture. Maybe your one serverless task is going to cost a ludicrous amount of money (as with APV), or is duplicated elsewhere, or is going to bottleneck another task elsewhere.
Again: The supposed difference between the two methods is not based on the technology itself, but the context in which you’re working. If I’m fully bought into AWS as my platform from a governance and knowledge perspective, then serverless does allow me to focus on just the task I’m doing, because everything else is taken care of.
There are these two young fish swimming along and they happen to meet an older fish swimming the other way, who nods at them and says “Morning, boys. How’s the water?” And the two young fish swim on for a bit, and then eventually one of them looks over at the other and goes “What the hell is water?”
When you’re developing, you want your context to be like water to a fish: invisible, not in your way, sustaining you. But if I’m not a fish swimming in AWS’s metaphorical water, then I’m likely to splash around a lot if I dive into it.
Most advocates of serverless take it as a base assumption of the discussion that you are fully, maturely, and exclusively bought into cloud technologies, and the hyperscalers’ ecosystems. But for many more people working in software (including our customers), that’s not true, and they are wrestling with what, for them, is still a relatively unfamiliar environment.
A Confession
I want to make a confession. Based on what you’ve read so far, you might surmise I’m someone who doesn’t like the idea of serverless technology. But I’ve spent 23 years so far doing serverless work. Yes, I’m one of those people who claims to have 23 years experience in a 15-year old technology.
In fact, there’s many of us out there. This is because in those days we didn’t call these technologies ‘serverless’ or ‘Lambda’, we called them ‘stored procedures’.
Serverless seems like stored procedures to me. The surrounding platform is just a cloud mainframe rather than a database.
I worked for a company for 15 of those years where the ‘big iron’ database was the water we swam in. We used it for message queues (at such a scale that IBM had to do some pretty nifty work to optimise for our specific use case and give us our own binaries off the main trunk), for our event-driven architectures (using triggers), and as our serverless platform (using stored procedures).
The joy of having a database as the platform was exactly the same then as the joys of having a serverless platform on a hyperscaler now. We didn’t have to provision compute resources for it (DBA’s problem), maintain the operating system (DBA’s problem), or worry or performance (DBA’s problem, mostly). We didn’t have to think about building a huge application, we just had to think about one task, one unit of work. And it took minutes to deploy.
Serverless itself is nothing new. It’s just a name for what you’re doing when you can write code and let someone else manage the runtime environment (the ‘water’) for you. What’s new is the platform you treat as your water. For me 23 years ago, it was the database. Now it’s the cloud platform.
Mainframes, Clouds, Databases, and Lock-In
The other objection to serverless that’s often heard is that it increases your lock-in to the hyperscaler, something that many architects, CIOs, and regulators say they are concerned about. But as a colleague once quipped to me: “Lock-in? We are all locked into x86”, the point being that we’re all swimming in some kind of water, so it’s not about avoiding lock-in, but rather choosing your lock-in wisely.
It was symbolic when Amazon (not AWS) got rid of their last Oracle database in 2019, replacing them with AWS database services. In retrospect, this might be considered the point where businesses started to accept that their core platform had moved from a database to a cloud service provider. A similar inflection point where the mainframe platform was supplanted by commodity servers and PCs might be considered to be July 5, 1994, when Amazon itself was founded. Ironically, then, Amazon heralded both the death of the mainframe, and the birth of its replacement with AWS.
Conclusion
With this context in mind, it seems that the reason I never hopped onto the serveless train is because, to me, it’s not the software paradigm I was ushered into as a young engineer. To me, quickly spinning up a three-tier application is as natural as throwing together an application using S3, DynamoDB, and API Gateway is for those cloud natives that cut their teeth knowing nothing else.
What strikes this old codger most about the Amazon Prime Video article is the sheer irony of serverless’s defenders saying that its lack of scalability is the reason you need to move to a more monolithic architecture. It was serverless’s very scalability and the avoidance of the need to re-architect later that was one of its key original selling points!
But when three-tier architectures started becoming popular I’m sure mainframers of the past said the same thing: “What’s the point of building software on commodity hardware, when it’ll end up on the mainframe?” Maybe they even leapt on articles describing how big businesses were moving their software back to the mainframe, having failed to make commodity servers work for them, and joyously proclaimed that rumours of the death of the mainframe was greatly exaggerated.
And in a way, maybe they were right. Amazon killed the physical mainframe, then killed the database mainframe, then created the cloud mainframe. Long live the monolith!
This article was originally published on Container Solutions’ blog and is reproduced here by permission.
Recently, in Container Solutions’ engineering Slack channel, a heated argument ensued amongst our engineers after a Pulumi-related story was posted. I won’t recount the hundreds of posts in the thread, but the first response was “I still don’t know why we still use Terraform”, followed by a still-unresolved ping-pong debate about whether Pulumi is declarative or imperative, followed by another debate about whether any of this imperative vs declarative stuff really matters at all, and why can’t we just use Pulumi please?
This article is my attempt to prove that I was right and everyone else was wrong calmly lay out some of the issues and help you understand both what’s going on and how to respond to your advantage when someone says your favoured tool is not declarative and therefore verboten.
What does declarative mean, exactly?
Answering this question is harder than it appears, as the formal use of the term can vary from the informal use within the industry. So we need to unpick first the formal definition, then look at how the term is used in practice.
“In computer science, declarative programming is a programming paradigm—a style of building the structure and elements of computer programs—that expresses the logic of a computation without describing its control flow.”
This can be reduced to:
“Declarative programming expresses the logic of a computation without describing its control flow.”
This immediately begs the question: ‘what is control flow?’ Back to Wikipedia:
“In computer science, control flow (or flow of control) is the order in which individual statements, instructions or function calls of an imperative program are executed or evaluated. Within an imperative programming language, a control flow statement is a statement that results in a choice being made as to which of two or more paths to follow.”
This can be reduced to:
“Imperative programs make a choice about what code is to be run.”
According to Wikipedia, examples of control flow include if statements, loops, and indeed any other construct that allows changes which statement is to be performed next (e.g. jumps, subroutines, coroutines, continuations, halts).
Informal usage and definitions
In debates around tooling, people rarely stick closely to the formal definitions of declarative and imperative code. The most commonly heard informal definition saw heard is: “Declarative code tells you what to do, imperative code says how to do it”. It sounds definitive, but discussion about it quickly devolves into definitions of what ‘what’ means and what ‘how’ means.
Any program tells you ‘what’ to do, so that’s potentially misleading, but one interpretation of that is that it describes the state you want to achieve.
For example, by that definition, is this pseudo-code declarative or imperative?
if exists(ec2_instance_1):
create(ec2_instance_2)
create(ec2_instance_1)
Firstly, strictly speaking, it’s definitely not declarative according to a formal definition, as the second line may or may not run, so there’s control flow there.
It’s definitely not idempotent, as running once does not necessarily result in the same outcome as running twice. But an argument put to me was: “The outcome does not change because someone presses the button multiple times”, some sort of ‘eventually idempotent’ concept. Indeed, a later clarification was: “Declarative means for me: state eventually consistent”.
It’s not just engineers in the field who don’t cling to the formal definition. This Jenkinsfile documentation describes the use of conditional constructs whilst calling itself declarative.
So far we can say that:
The formal definitions of imperative vs declarative are pretty clear
In practice and general discussion, people get a bit confused about what it means and/or don’t care about the formal definition
Are there degrees of declarativeness?
In theory, no. In practice, yes. Let me explain.
What is the most declarative programming language you can think of? Whichever one it is, it’s likely that either there is a way to make it (technically) imperative, or it is often described as “not a programming language”.
HTML is so declarative that a) people often deride it as “not a programming language at all”, and b) we had to create the JavaScript monster and the SCRIPT tag to ‘escape’ it and make it useful for more than just markup. This applies to all pure markup languages. Another oft-cited example is Prolog, which has loops, conditions, and a halt command, so is technically not declarative at all.
SQL is to many a canonical declarative language: you describe what data you want, and the database management system (DBMS) determines how that data is retrieved. But even with SQL you can construct conditionals:
insert into table1
where exists (
select 1
from table2
where "some value" == table2.column1
)
Copy
The insert to table1 will only run conditionally, i.e. if there’s a row in table two that matches the text “some value”. You might think that this is a contrived example, and I won’t disagree. But in a way this backs up my central argument: whatever the technical definition of declarative is, the difference between most languages in this respect is how easy or natural it is to turn them into imperative languages.
This is clearly effectively imperative code. It runs in an order from top to bottom, and has conditionals. It can run different instructions at different times, depending on the context it is run in. However, YAML itself is still declarative. And because YAML is declarative, we have the hell of Helm, kustomize, and different devops pipeline languages that claim to be declarative (but clearly aren’t) to deal with, because we need imperative, dynamic, conditional, branching ways to express what we want to happen.
It’s this tension between the declarative nature of the core tool and our immediate needs to solve problems that creates the perverse outcomes we hate so much as engineers, where we want to ‘break out’ of the declarative tool in order to get the things we want done in the way that we want it done.
Terraform and Pulumi
Which brings us neatly to the original subject of the Slack discussion we had at Container Solutions.
Anyone who has used Terraform for any length of time in the field has probably gone through two phases. First, they marvel at how the declarative nature of it makes it in many ways easier to maintain and reason about. And second, after some time using it, and as complexity in the use case builds and builds, they increasingly wish they could have access to imperative constructs.
It wasn’t long before Hashicorp responded to these demands and introduced the ‘count’ meta-argument, which effectively gave us some kind of loop concept, and hideous bits of code like this abound to give us if statements by the back door:
count = var.something_to_do ? 1 : 0
There’s also for and for_each constructs, and the local-exec provisioner, which allows you to escape any declarative shackles completely and just drop to the (decidedly non-declarative) shell once the resource is provisioned.
It’s often argued that Pulumi is not declarative, and despite protestations to the contrary, if you are using it for its main selling point (that you can use your preferred imperative language to declare your desired state), then Pulumi is effectively an imperative tool. If you talk to the declarative engine under Pulumi’s hood in YAML, then you are declarative all the way down (and more declarative than Terraform, for sure).
The point here is that not being purely declarative is no bad thing, as it may be that your use case demands a more imperative language to generate a state representation. Under the hood, that state representation describes the ‘what’ you want to do, and the Pulumi engine figures out how to achieve that for you.
Some of us at Container Solutions worked some years ago at a major institution that built a large-scale project in Terraform. For various reasons, Terraform was ditched in favour of a python-based boto3 solution, and one of those reasons was that the restrictions of a more declarative language produced more friction than the benefits gained. In other words, more control over the flow was needed. It may be that Pulumi was the tool we needed: A ‘Goldilocks’ tool that was the right blend of imperative and declarative for the job at hand. It could have saved us writing a lot of boto3 code, for sure.
How to respond to ‘but it’s not declarative!’ arguments
Hopefully reading this article has helped clarify the fog around declarative vs imperative arguments. First, we can recognise that purely declarative languages are rare, and even those that exist are often contorted into effectively imperative tooling. Second, the differences between these tools is how easy or natural they make that contortion.
There are good reasons to make it difficult for people to be imperative. Setting up simple Kubernetes clusters can be a more repeatable and portable process due to its declarative configuration. When things get more complex, you have to reach for tools like Helm and kustomize which may make you feel like your life has been made more difficult.
WIth this more nuanced understanding, next time someone uses the “but it’s not declarative” argument to shut you down, you can tell them two things: That that statement is not enough to win the debate; and that their suggested alternative is likely either not declarative, or not useful. The important question is not: “Is it declarative?” but rather: ‘How declarative do we need it to be?”
This article was originally published on Container Solutions’ blog and is reproduced here by permission.
Business strategy is very easy to get wrong. You’re trying to make sure your resources and assets are efficiently deployed and focussed on your end goal, and that’s hard. There’s no magic bullet that can help you both get the right strategy defined, and then successfully deliver on it, but there are many resources we’ve found that can help reduce the risk of failure.
Under the heading ‘The Future of Cloud’, Gartner recently ran a symposium for CIOs and IT executives including much discussion about strategies relating to Cloud and Cloud Native trends. At least two of the main talks (one, two) were centred around a five-year horizon, discussing where cloud adoption will be in 2027 compared to where it is now.
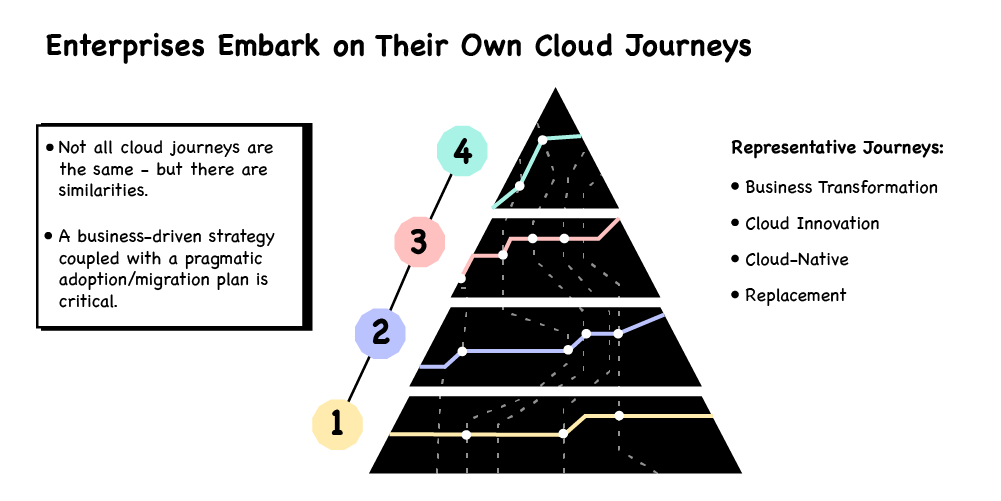
As part of those talks, Gartner referenced a useful pyramid-shaped visualisation of different stages of cloud adoption. It could be viewed as a more schematic version of our Maturity Matrix, which we use as part of our Cloud Native Assessments with clients.
In this article, we’re going to use the Gartner visualisation to talk about one of the biggest mistakes made in Cloud Native transformation strategies.
The pyramid
Gartner’s pyramid depicts four stages of cloud adoption from the perspective of business scope. These stages are shown as a hierarchy where the bottom layer represents the lowest dependency (“Technology Disruptor”) and the top layer represents the highest level business goal (“Business Disruptor”).
The four stages can be briefly summarised as:
Cloud As Technology Disruptor
The new base technology is adopted. For example, containerised applications, or a move to using a cloud service provider instead of a data centre.
Cloud As Capability Enabler
Now you have new technology in place, you can more easily build capabilities that may have been more difficult to achieve before, such as automated testing, or CI/CD.
Cloud As Innovation Facilitator
With new capabilities, you have the right environment to foster innovation in your business. This means you might, for example, leverage your cloud platform to deliver features more quickly, or conduct A/B testing of new features to maximise your return on investment.
Cloud As Business Disruptor
The most advanced stage of cloud adoption, where you can use the previous three stages’ outputs to change your business model by, for example, migrating to a SaaS model, or scaling your client base significantly, or introducing an entirely new product line.
Whilst it is somewhat higher level, this pyramid is similar to our Maturity Matrix in that it helps give you a common visual reference point for a comprehensible and tangible view of both where you are, and where you are trying to get to, in your Cloud Native program. For example, it can help in discussions with technologists to ask them how the changes they are planning relate to stage four. Similarly, when talking to senior leaders about stage four, it can help to clarify whether they and their organisation have thought about the various dependencies below their goal and how they relate to each other.
It can also help you avoid the biggest Cloud Native strategy mistake.
The big mistake
The biggest anti-pattern we see when consulting on Cloud Native strategy is to conflate all four phases of the pyramid into one monolithic entity. This means that participants in strategic discussions treat all four stages as a single stage, and make their plans based on that.
This anti-pattern can be seen at both ends of the organisational spectrum. Technologists, for example, might focus on the technical challenges, and are often minded to consider cloud strategy as simply a matter of technology adoption, or even just technology choice and installation. Similarly, business leaders often see a successful Cloud Native transformation as starting and stopping with a single discrete technical program of work rather than an overlapping set of capabilities that the business needs to build in its own context.
This monolithic strategy also conflates the goals of the strategy with the adoption plan, which in turn can lead to a tacit assumption that the whole program should be outlined in a single static and unchanging document.
For example, a business might document that their ‘move to the cloud’ is being pursued in order to transition their product from a customer installation model to a more scalable SaaS model. This would be the high-level vision for the program, the ‘level four’ of the pyramid. In the same document, there might be a roadmap which sets out how the other three levels will be implemented. For example, it might outline which cloud service provider will be used, which of those cloud service provider’s services will be consumed, which technology will be used as an application platform, and what technologies will be used for continuous integration and delivery.
This mixing of the high-level vision with the adoption plan risks them being treated as a single task to be completed. In reality, the vision and adoption plan should be separated, as while it is important to have clarity and consistency of vision, the adoption plan can change significantly as the other three levels of the pyramid are worked through, and this should be acknowledged as part of the overall strategy. At Container Solutions we call this ‘dynamic strategy’: a recognition that the adoption plan can be iterative and change as the particular needs and capabilities of your business interact with the different stages.
The interacting stages and ‘organisational indigestion’
Let’s dig a little bit deeper into each phase.
In the first ‘Technology Disruptor’ phase, there is uncertainty about how fast the technology teams can adopt new technologies. This can depend on numerous local factors such as the level of experience and knowledge of these technologies among your teams, their willingness to take risks to deliver (or even deliver at all), and external blocks on delivery (such as security or testing concerns). It should also be said that whilst skills shortages are often cited as blocking new technology adoption, it is no longer practical to think of skills as a fixed thing that is hired as part of building a team to run a project based on a specific technology. Rather, technology skills need to be continuously developed by teams of developers exploring new technologies as they emerge and mature. To support this, leaders need to foster a “learning organisation” culture, where new ideas are explored and shared routinely.
The second ‘Capability Enabler’ phase has a basic dependency on the ‘Technology Disruptor’ phase. If those dependencies are not managed well, then organisational challenges may result. For example, whilst CI/CD capabilities can be built independently of the underlying technology, its final form will be determined by its technological enablers. A large-scale effort to implement Jenkins pipelines across an organisation may have to be scrapped and reworked if the business decides that AWS-native services should be used, and therefore the mandated tool for CI is AWS CodePipeline. This conflict between the ‘Technology Disruptor’ phase (the preference for AWS-native services) and ‘Capability Enabler’ phases can be seen as ‘organisational indigestion’ that can cause wasted time and effort as contradictions in execution are worked out.
The third ‘Innovation Facilitator’ phase is also dependent on the lower phases, as an innovation-enabling cloud platform is built for the business. Such a platform (or platforms) cannot be built without the core capabilities being enabled through the lower phases.
In practice, the three base phases can significantly overlap with one another, and could theoretically be built in parallel. However, ignoring the separability of the phases can result in the ‘organisational indigestion’ mentioned above, as the higher phases need to be revisited if the lower phases change. To give another simple example: if a business starts building a deployment platform on AWS CodeDeploy, it would need to be scrapped if the lower level decides to use Kubernetes services on Google Cloud.
The wasted effort and noise caused by this ‘organisational indigestion’ can be better understood and managed through the four phases model.
The treatment of Cloud Native strategy adoption as a single static monolith can also help to downplay or ignore the organisational challenges that lie ahead for any business. One example of this might be that while implementing a Cloud Native approach to automated testing could be a straightforward matter of getting engineers to write tests that previously didn’t exist, or it could equally be a more protracted and difficult process of retraining a manual testing team to now program automated tests.
Finally, the monolithic approach can lead to a collective belief that the project can be completed in a relatively short period of time. What’s a reasonable length of time? It’s worth remembering that Netflix, the reference project for a Cloud Native transformation, took seven years to fully move from their data centre to AWS. And Netflix had several things in their favour that made their transformation easier to implement: a clear business need (they could not scale fast enough and were suffering outages); a much simpler cloud ecosystem; a product clarity (video streaming) that made success easy to define; and a lack of decades of legacy software to maintain while they were doing it.
What to do about it?
We’ve outlined some of the dangers that not being aware of the four stages can bring, so what can you do to protect yourself against them?
Be clear about your path on the pyramid – optimisation or transformation?
The first thing is to ensure you have clarity around what the high-level vision and end goals for the transformation are. Gartner encapsulates this in a train map metaphor, to prompt the question of what your journey is envisaged to be. The ‘Replacement’ path, which goes across the first ‘Technical Disruption’ can also encompass the classic ‘Lift and Shift’ journey, the ‘Cloud Native’ path might cross both the first and second phases, and the ‘Business Transformation’ journey can cross all four phases.
The ‘east-west’ journeys can be characterised as ‘optimisation’ journeys, while the ‘south-north’ journeys can be characterised as ‘transformation’ journeys.
If the desired journey is unclear, then there can be significant confusion between the various parties involved about what is being worked towards. For example, executives driving the transformation may see a ‘Replacement’ approach as sufficient to make a transformation and therefore represent a journey up the pyramid, whilst those more technologically minded will immediately see that such a journey is an ‘optimisation’ one going across the first phase.
A monolithic strategy that encompasses both vision and adoption can result in a misplaced faith in some parties that the plan is clear, static, and linearly achieved. This faith can flounder when faced with the reality of trying to move an organisation across the different phases.
Each organisation is unique, and as it works through the phases the organisation itself changes as it builds its Cloud Native capabilities. This can have a recursive effect on the whole program as the different phases interact with each other and these changing capabilities.
You can help protect against the risk of a monolithic plan by separating your high-level vision from any adoption plan. Where the vision describes why the project is being undertaken and should be less subject to change, the adoption plan (or plans) describes how it should be done, and is more tactical and subject to change. In other words, adoption should follow the dynamic strategy pattern.
Start small and be patient
Given the need for a dynamic strategy, it’s important to remember that if you’re working on a transformation, you’re building an organisational capability rather than doing a simple installation or migration. Since organisational capability can’t be simply transplanted or bought in in a monolithic way, it’s advisable to follow the gradually raising the stakes pattern. This pattern advocates for exploratory experiments in order to cheaply build organisational knowledge and experience before raising the stakes. This ultimately leads up to commitment to the final big bet, but by this point risk of failure will have been reduced by the learnings gained from the earlier, cheaper bets.
As we’ve seen from the Netflix example, it can take a long time even for an organisation less encumbered by a long legacy to deliver on a Cloud Native vision. Patience is key, and a similar approach to organisational learning needs to be taken into account as you gradually onboard teams onto any cloud platform or service you create or curate.
Effective feedback loop
Since the strategy should be dynamic and organisational learning needs to be prioritised, it’s important that an effective and efficient feedback loop is created between all parties involved in the transformation process. This is harder to achieve than it might sound, as there is a ‘Goldilocks effect’ in any feedback loop: too much noise, and leaders get frustrated with the level of detail; too little, and middle management can get frustrated as the reality of delivering on the vision outlined by the leaders hits constraints from within and outside the project team. Similarly, those on the ground can get frustrated by either the perceived bureaucratic overhead of attending multiple meetings to explain and align decisions across departments, or the ‘organisational indigestion’ mentioned above when decisions at different levels conflict with each other and work must be scrapped or re-done.
Using the pyramid
The pyramid is an easily-understood way to visualise the different stages of cloud transformation. This can help align the various parties’ conception of what’s ahead and avoid the most often-seen strategic mistake when undergoing a transformation: the simplification of all stages into one static and pre-planned programme.
Cloud transformation is a complex and dynamic process. Whilst the vision and goals should not be subject to change, the adoption plan is likely to, as you learn how the changes you make to your technology expose further changes that need to be made to the business to support and maximise the benefits gained. It is therefore vital to separate the high level goals of your transformation from the implementation detail, and ensure there is an effective feedback loop
Through all this complexity, the pyramid can help you both conceptualise the vision for your transformation and define and refine the plan for adoption, allowing you to easily connect the more static high level goals to the details of delivery.
This article was originally published on Container Solutions’ blog and is reproduced here by permission.
At Container Solutions, we often work with large enterprises who are at various different stages of adopting cloud technologies. These companies are typically keen to adopt modern Cloud Native software working practices and technologies as itemised in our Maturity Matrix, so come to us for help, knowing that we’ve been through many of these transformation processes before.
Financial services companies are especially keen to adopt DevSecOps, as the benefits to them are obvious given their regulatory constraints and security requirements. This article will focus on a common successful pattern of adoption for getting DevSecOps into large-scale enterprises that have these kinds of constraints on change.
DevSecOps and institutional inertia
The first common misconception about implementing DevSecOps is that it is primarily a technical challenge but, as we’ve explored on WTF before, it is at least as much about enabling effective communication. Whilst we have engineering skills in cutting-edge tooling and cloud services, there is little value in delivering a nifty technical solution if the business it’s delivered for is unable or unwilling to use it. If you read technical blog posts on the implementation of DevSecOps, you might be forgiven for thinking that the only things that matter are the tooling you choose, and how well you write and manage the software that is built on this tooling.
For organisations that were ‘born in the cloud’, where everyone is an engineer and has little legacy organisational scar tissue to consider, this could indeed be true. In such places, where the general approach to DevSecOps is well-grasped and agreed on by all parties, the only things to be fought over are indeed questions of tooling. This might be one reason why such debates take on an almost religious fervour.
The reality for larger enterprises that aren’t born in the cloud is that there are typically significant areas of institutional inertia to overcome. These include (but are not limited to):
Siloed teams that have limited capability in new technologies and processes
Internal policies and process designed for the existing ways of working
Prerequisites for success
Before outlining the pattern for success, it’s worth pointing out two critical prerequisites for enterprise change management success in moving to DevSecOps. As an aside, these prerequisites are not just applicable to DevSecOps but apply to most change initiatives.
The first is that the vision to move to a Cloud Native way of working must be clearly articulated to those tasked with delivering on it. The second is that the management who articulate the vision must have ‘bought into’ the change. This doesn’t mean they just give orders and timelines and then retreat to their offices, it means that they must back up the effort when needed with carrots, sticks, and direction when those under them are unsure how to proceed. If those at the top are not committed in this way, then those under them will certainly not push through and support the changes needed to make DevSecOps a success.
A three-phase approach
At Container Solutions we have found success in implementing DevSecOps in these contexts by taking a three-phase approach:
Introduce tooling
Baseline adoption
Evolve towards an ideal DevSecOps practice
The alternative that this approach is put up against is the ‘build it right first time’ approach, where everything is conceived and delivered in one “big bang” style implementation.
Introduce tooling
In this phase you correlate the security team’s (probably manual) process with the automation tooling you have chosen, and determine their level of capability for automation. At this point you are not concerned with how closely the work being done now matches the end state you would like to reach. Indeed, you may need to compromise against your ideal state. For example, you might skip writing a full suite of tests for your policies.
The point of this initial phase is to create alignment on the technical direction between the different parties involved as quickly and effectively as possible. To repeat: this is a deliberate choice over technical purity, or speed of delivery of the whole endeavour.
The security team is often siloed from both the development and cloud transformation teams. This means that they will need to be persuaded, won over, trained, and coached to self-sufficiency.
Providing training to the staff at this point can greatly assist the process of adoption by emphasising the business’s commitment to the endeavour and setting a minimum baseline of knowledge for the security team. If the training takes place alongside practical implementation of the new skills learned, it makes it far more likely that the right value will be extracted from the training for the business.
The output of this phase should be that:
Security staff are comfortable with (at least some of) the new tooling
Staff are enthused about the possibilities offered by DevSecOps, and see its value
Staff want to continue and extend the efforts towards DevSecOps adoption
Get To baseline adoption
Once you have gathered the information about the existing process, the next step is to automate them as far as possible without disrupting the existing process too much. For example, if security policy adherence is checked manually in a spreadsheet by the security team (not an uncommon occurrence), those steps can be replaced by automation. Tools that might be used for this include some combination of pipelines, Terraform, Inspec, and so on. The key point is to start to deliver benefits for the security team quickly and help them see that this will make them more productive and (most importantly of all) increase the level of confidence they have in their security process.
Again, the goal for this stage is to level up the capabilities of the security team so that the move towards DevSecOps is more self-sustaining rather than imposed from outside. This is the priority over speed of delivery. In practical terms, this means that it is vital to offer both pairing (to elevate knowledge) and support (when things go wrong) from the start to maintain goodwill towards the effort. The aim is to spread and elevate the knowledge as far across the department as possible.
Keep in mind, though, that knowledge transfer will likely slow down implementation. This means that it is key to ensure you regularly report to stakeholders on progress regarding both policy deployment and policy outputs, as this will help sustain the momentum for the effort.
Key points:
Report on progress as you go
Provide (and focus on) help and support for the people who will maintain this in future
Where you can, prioritise spreading knowledge far and wide over delivering quickly
Once you have reached baseline adoption, you should be at a ‘point of no return’ which allows you to push on to move to your ideal target state.
Evolve to pure DevSecOps
Now that you have brought the parties on-side and demonstrated progress, you can start to move towards your ideal state. This begs the question of what that ideal state is, but we’re not going to exhaustively cover that here as that’s not the focus. Suffice it to say that security needs to be baked into every step of the overall development life cycle and owned by the development and operations teams as much as it is by the security team.
Some of the areas you would want to work on from here include:
Introducing/cementing separation of duties
Setting up tests on the various compliance tools used in the SDLC
Approval automation
Automation of policy tests’ efficacy and correctness
Compliance as code
These areas, if tackled too early, can bloat your effort to the point where the business sees it as too difficult or expensive to achieve. This is why it’s important to tackle the areas that maximise the likelihood of adoption of tooling and principles in the early stages.
Once all these things are coming together, you will naturally start to turn to the organisational changes necessary to get you to a ‘pure DevSecOps’ position, where development teams and security teams are working together seamlessly.
Conclusion
Like all formulas for business and technological change, this three-phase approach to introducing DevSecOps can’t be applied in exactly the same way in every situation. However, we’ve found in practice that the basic shape of the approach is very likely to be a successful one, assuming the necessary prerequisites are in place.
Building DevSecOps adoption in your business is not just about speed of delivery, it’s about making steady progress whilst setting your organisation up for success. To do this you need to make sure you are building capabilities and not just code.
This article was originally published on Container Solutions’ blog and is reproduced here by permission.
Occasionally I run dumb stuff in the terminal. Sometimes something unexpected happens and it leads me to wonder ‘how the hell did that work?’
This article is about one of those times and how looking into something like that taught me a few new things about shells. After decades using shells, they still force me to think!
The tl;dr is at the end if you don’t want to join me down this rabbit hole…
The Dumb Thing I Ran
The dumb thing I occasionally ran was:
grep .* *
If you’re experienced in the shell you’ll immediately know why this is dumb. For everyone else, here are some reasons:
The first argument to grep should always be a quoted string – without them, the shell treats the .* as a glob, not a regexp
grep .* just matches every line, so…
you could just get almost the same output by running cat *
Not Quite So Dumb
Actually, it’s not quite as dumb as I’ve made out. Let me explain.
In the bash shell, ‘.*‘ (unquoted) is a glob matching all the files beginning with the dot character. So the ‘grep .* *‘ command above interpreted in this (example) context:
$ ls -a1
. .. .adotfile file1 file2
Would be interpreted as the command in bold below:
$ echo grep .* *
grep . .. .adotfile file1 file2
The .* gets expanded by the shell as a glob to all file or folders beginning with the literal dot character.
Now, remember, every folder contains at least two folders:
The dot folder (.), which represents itself.
The double-dot folder (..), which represents the parent folder
So these get added to the command:
grep . ..
Followed by any other file or folder beginning with a dot. In the example above, that’s .adotfile.
grep . .. .adotfile
And finally, the ‘*‘ at the end of the line expands to all of the files in the folder that don’t begin with a dot, resulting in:
grep . .. .adotfile file1 file2
So, the regular expression that grep takes becomes simply the dot character (which matches any line with a single character in it), and the files it searches are the remaining items in the file list:
..
.adotfile
file1
file2
Since one of those is a folder (..), grep complains that:
grep: ..: Is a directory
before going on to match any lines with any characters in. The end result is that empty lines are ignored, but every other line is printed on the terminal.
Another reason why the command isn’t so dumb (and another way it differs from ‘cat *‘) is that since multiple files are passed into grep, it reports on the filename, meaning the output automatically adds which file the line comes from.
bash-5.1$ grep .* *
grep: ..: Is a directory
.adotfile:content in a dotfile
file1:a line in file1
file2:a line in file2
Strangely, for two decades I hadn’t noticed that this is a very roundabout and wrong-headed (ie dumb) way to go about things, nor had I thought about its output being different from what I might have expected; it just never came up. Running ‘grep .* *‘ was probably a bad habit I picked up when I was a shell newbie last century, and since then I never needed to think about why I did it, or even what it did until…
Why It Made Me Think
The reason I had to think about it was that I started to use zsh as my default terminal on my Mac. Let’s look at the difference with some commands you can try:
bash-5.1$ mkdir rh && cd rh
bash-5.1$ cat > afile << EOF
text
EOF
bash-5.1$ bash
bash-5.1$ grep .* afile
grep: ..: Is a directory
afile:text
bash-5.1$ zsh
zsh$ grep .* afile
zsh:1: no matches found: .*
For years I’d been happily using grep .* but suddenly it was telling me there were no matches. After scratching my head for a short while, I realised that of course I should have quotes around the regexp, as described above.
But I was still left with a question: why did it work in bash, and not zsh?
Google It?
I wasn’t sure where to start, so I googled it. But what to search for? I tried various combinations of ‘grep in bash vs zsh‘, ‘grep without quotes bash zsh‘, and so on. While there was some discussion of the differences between bash and zsh, there was nothing which addressed the challenge directly.
Options?
Since google wasn’t helping me, I looked for shell options that might be relevant. Maybe bash or zsh had a default option that made them behave differently from one another?
In bash, a quick look at the options did not reveal many promising candidates, except for maybe noglob:
bash-5.1$ set -o | grep glob
noglob off
bash-5.1$ set -o noglob
bash-5.1$ set -o | grep glob
noglob on
bash-5.1$ grep .* *
grep: *: No such file or directory
But this is different from zsh‘s output. What noglob does is completely prevent the shell from expanding globs. This means that no file matches the last ‘*‘ character, which means that grep complains that no files are matched at all, since there is no file named ‘*‘ in this folder.
And for zsh? Well, it turns out there are a lot of options in zsh…
zsh% set -o | wc -l
185
Even just limiting to those options with glob in them doesn’t immediately hit a jackpot:
zsh% set -o | grep glob
nobareglobqual off
nocaseglob off
cshnullglob off
extendedglob off
noglob off
noglobalexport off
noglobalrcs off
globassign off
globcomplete off
globdots off
globstarshort off
globsubst off
kshglob off
nullglob off
numericglobsort off
shglob off
warncreateglobal off
While noglob does the same as in bash, after some research I found that the remainder are not relevant to this question.
(Trying to find this out, though, it tricky. First zsh‘s man page is not complete like bash‘s, it’s divided into multiple man pages. Second, concatenating all the zshman pages with man zshall and searching for noglob gest no matches. It turns out that options are documented in caps with underscored separating words. So, in noglob‘s case, you have to search for NO_GLOB. Annoying.)
zsh with xtrace?
Next I wondered whether this was due to some kind of startup problem with my zsh setup, so I tried starting up zsh with the xtrace option to see what’s run on startup. But the output was overwhelming, with over 13,000 lines pushed to the terminal:
bash-5.1$ zsh -x 2> out
zsh$ exit
bash-5.1$ wc -l out
13328
I did look anyway, but nothing looked suspicious.
zsh with NO_RCS?
Back to the documentation, and I found a way to start zsh without any startup files by starting with the NO_RCS option.
There was no change in behaviour, so it wasn’t anything funky I was doing in the startup.
At this point I tried using the xtrace option, but then re-ran it in a different folder by accident:
zsh$ set -o xtrace
zsh$ grep .* *
zsh: no matches found: .*
zsh$ cd ~/somewhere/else
zsh$ grep .* *
+zsh:3> grep .created_date notes.asciidoc
Interesting! The original folder I created to test the grep just threw an error (no matches found), but when there is a dotfile in the folder, it actually runs something… and what it runs does not include the dot folder (.) or parent folder (..)
Instead, the ‘grep .* *‘ command expands the ‘.*‘ into all the files that begin with a dot character. For this folder, that is one file (.created_date), in contrast to bash, where it is three (. .. .created_date). So… back to the man pages…
tl;dr
After another delve into the man page, I found the relevant section in man zshall that gave me my answer:
FILENAME GENERATION
[...]
In filename generation, the character /' must be matched explicitly; also, a '.' must be matched explicitly at the beginning of a pattern or after a '/', unless the GLOB_DOTS option is set. No filename generation pattern matches the files '.' or '..'. In other instances of pattern matching, the '/' and '.' are not treated specially.
So, it was as simple as: zsh ignores the ‘.‘ and ‘..‘ files.
But Why?
But I still don’t know why it does that. I assume it’s because the zsh designers felt that that wrinkle was annoying, and wanted to ignore those two folders completely. It’s interesting that there does not seem to be an option to change this behaviour in zsh.
Working in Cloud Native consulting, I’m often asked about who should do various bits of ‘the platform work‘.
I’m asked this in various forms, and at various levels, but the title’s question (‘Who should write the Terraform?) is a fairly typical one. Consultants are often asked simple questions that invite simple answers, but it’s our job to frustrate our clients, so I invariably say “it depends”.
The reason it depends is that the answers to these seemingly simple questions are very context-dependent. Even if there is an ‘ideal’ answer, the world is not ideal, and the best thing for a client at that time might not be the best thing for the industry in general.
So here I attempt to lay out the factors that help me answer that questions as honestly as possible. But before that, we need to lay out some background.
Here’s an overview of the flow of the piece:
What is a platform?
How we got here
Coders and Sysadmins became…
Dev and Ops, but silos and slow time to market, so…
DevOps, but not practical, so…
SRE and Platforms
The factors that matter
Non-negotiable standards
Developer capability
Management capability
Platform capability
Time to market
What is a Platform?
Those old enough to remember when the word ‘middleware’ was everywhere will know that many industry terms are so vague or generic as to be meaningless. However, for ‘platform’ work we have a handy definition, courtesy of Team Topologies:
The purpose of a platform team is to enable stream-aligned teams to deliver work with substantial autonomy. The stream-aligned team maintains full ownership of building, running, and fixing their application in production. The platform team provides internal services to reduce the cognitive load that would be required from stream-aligned teams to develop these underlying services.
Team Topologies, Matthew Skelton and Manuel Pais
A platform team, therefore, (and putting it crudely) builds the stuff that lets others build and run their stuff.
So… is the Terraform written centrally, or by the stream-aligned teams?
To explain how I would answer that, I’m going to have to do a little history.
How We Got Here
Coders and Sysadmins
In simpler times – after the Unix epoch and before the dotcom boom – there were coders and there were sysadmins. These two groups speciated from the generic ‘computer person’ that companies found they had to have on the payroll (whether they liked it or not) in the 1970s and 80s.
As a rule, the coders liked to code and make computers do new stuff, and the sysadmins liked to make sure said computers worked smoothly. Coders would eagerly explain that with some easily acquired new kit, they could revolutionise things for the business, while sysadmins would roll their eyes and ask how this would affect user management, or interoperability, or stability, or account management, or some other boring subject no-one wanted to hear about anymore.
I mention this because this pattern has not changed. Not one bit. Let’s move on.
Dev and Ops
Time passed, and the Internet took over the world. Now we had businesses running websites as well as their internal machines and internal networks. Those websites were initially given to the sysadmins to run. Over time, these websites became more and more important for the bottom line, so eventually, the sysadmins either remained sysadmins and looked after ‘IT’, or became ‘operations’ (Ops) staff and looked after the public-facing software systems.
Capable sysadmins had always liked writing scripts to automate manual tasks (hence the t-shirt), and this tendency continued (sometimes) in Ops, with automation becoming the defining characteristic of modern Ops.
Eventually a rich infrastructure emerged around the work. ‘Pipelines’ started to replace ‘release scripts’, and concepts like ‘continuous integration’, and ‘package management’ arose. But we’re jumping ahead a bit; this came in the DevOps era.
Coders, meanwhile, spent less and less time doing clever things with chip registers and more and more time wrangling different software systems and APIs to do their business’s bidding. They stopped being called ‘coders’ and started being called ‘developers’.
So ‘Devs’ dev’d, and ‘Ops’ ops’ed.
These groups grew in size and proportion of the payroll as software started to ‘eat the world’.
In reality, of course, there was a lot of overlap between the two groups, and people would often move from one side of the fence to the other. But the distinction remained, and become organisational orthodoxy.
Dev and Ops Inefficiencies
As the Dev and Ops this pattern became bedded into organisation, people noted some inefficiencies with this state of affairs:
Release overhead
Misplaced expertise
Cost
First, there was a release overhead as Dev teams passed changes to Ops. Ops teams typically required instructions for how to do releases, and in a pre-automation age these were often prone to error without app- or even release-specific knowledge. I was present about 15 years in a very fractious argument between a software supplier and its client’s Ops team after an outage. The Ops team attempted to follow instructions for a release, which resulted in an outage, as instructions were not followed correctly. There was much swearing as the Ops team remonstrated that the instructions were not clear enough, while the Devs argued that if the instructions had been followed properly then it would have worked. Fun.
Second, Ops teams didn’t know in detail what they were releasing, so couldn’t fix things if they went wrong. The best they could do was restart things and hope they worked.
Third, Ops teams looked expensive to management. They didn’t deliver ‘new value’, just farmed existing value, and appeared slow to respond and risk-averse.
I mention this because this pattern has not changed. Not one bit. Let’s move on.
These and other inefficiencies were characterised as ‘silos’ – unhelpful and wasteful separations of teams for (apparently) no good purpose. Frictions increased as these mismatches were exacerbated by embedded organisational separation.
The solution was clearly to get rid of the separation: no more silos!
Enter DevOps
The ‘no more silos’ battle cry got a catchy name – DevOps. The phrase was usefully vague and argued over for years, just as Agile was and is (see here). DevOps is defined by Wikipedia as ‘a set of practices that combines software development (Dev) and IT operations (Ops)’.
At the purest extreme, DevOps is the movement of all infrastructure and operational work and responsibilities (ie ‘delivery dependencies’) into the development team.
This sounded great in theory. It would:
Place the operational knowledge within the development team, where its members could more efficiently collaborate in tighter iterations
Deliver faster – no more waiting weeks for the Ops team to schedule a release, or waiting for Ops to provide some key functionality to the development team
Bring the costs of operations closer to the value (more exactly: the development team bore the cost of infrastructure and operations as part of the value stream), making P&L decisions closer to the ‘truth’
DevOps Didn’t
But despite a lot of effort, the vast majority of organisations couldn’t make this ideal work in practice, even if they tried. The reasons for this were systemic, and some of the reasons are listed below:
Absent an existential threat, the necessary organisational changes were more difficult to make. This constraint limited the willingness or capability to make any of the other necessary changes
The organisational roots of the Ops team were too deep. You couldn’t uproot the metaphorical tree of Ops without disrupting the business in all sorts of ways
There were regulatory reasons to centralise Ops work which made distribution very costly
The development team didn’t want to – or couldn’t – do the Ops work
It was more expensive. Since some work would necessarily be duplicated, you couldn’t simply distribute the existing Ops team members across the development teams, you’d have to hire more staff in, increasing cost
I said ‘the vast majority’ of organisations couldn’t move to DevOps, but there are exceptions. The exceptions I’ve seen in the wild implemented a purer form of DevOps when there existed:
Strong engineering cultures where teams full of T-shaped engineers want to take control of all aspects of delivery AND
No requirement for centralised control (eg regulatory/security constraints)
and/or,
A gradual (perhaps guided) evolution over time towards the breaking up of services and distribution of responsibility
and/or,
Strong management support and drive to enable
The most famous example of the ‘strong management support’ is Amazon, where so-called pizza teams must deliver and support their products independently. (I’ve never worked for Amazon so I have no direct experience of the reality of this). This, notably, was the product of a management edict to ensure teams operated independently.
When I think of this DevOps ideal, I think of a company with multiple teams each independently maintaining their own discrete marketing websites in the cloud. Not many businesses have that kind of context and topology.
Enter SRE and Platforms
One of the reasons listed above for the failure of DevOps was the critical one: expense.
Centralisation, for all its bureaucratic and slow-moving faults, can result in vastly cheaper and more scalable delivery across the business. Any dollar spent at the centre can save n dollars across your teams, where n is the number of teams consuming the platform.
The most notable example of this approach is Google, who have a few workloads to run, and built their own platform to run them on. Kubernetes is a descendant of that internal platform.
It’s no coincidence that Google came up with DevOps’s fraternal concept: SRE. SRE emphasised the importance of getting Dev skills into Ops rather than making Dev and Ops a single organisational unit. This worked well at Google primarily because there was an engineering culture at the centre of the business, and an ability to understand the value of investing in the centre rather than chasing features. Banks (who might well benefit from a similar way of thinking) are dreadful at managing and investing in centralised platforms, because they are not fundamentally tech companies (they are defenders of banking monopoly licences, but that’s a post for another day, also see here).
So across the industry, those that might have been branded sysadmins first rebranded themselves as Ops, then as DevOps, and finally SREs. Meanwhile they’re mostly the same people doing similar work.
Why the History Lesson?
What’s the point of this long historical digression?
Well, it’s to explain that, with a few exceptions, the division between Dev and Ops, and between centralisation and distribution of responsibility has never been resolved. And the reasons why the industry seems to see-saw are the same reasons why the answer to the original question is never simple.
Right now, thanks to the SRE movement (and Kubernetes, which is a trojan horse leading you away from cloud lock-in), there is a fashion-swing back to centralisation. But that might change again in a few years.
And it’s in this historical milieu that I get asked questions about who should be responsible for what with respect to work that could be centralised.
The Factors
Here are the factors that play into the advice that I might give to these questions, in rough order of importance.
Factor One: Non-Negotiable Standards
If you have standards or practices that must be enforced on teams for legal, regulatory, or business reasons, then at least some work needs to be done at the centre.
Examples of this include:
Demonstrable separation of duties between Dev and Ops
User management and role-based access controls
Performing an audit on one team is obviously significantly cheaper than auditing a hundred teams. Further, with an audit, the majority of expense is not in the audit but the follow-on rework. The cost of that can be reduced significantly if a team is experienced at knowing from the start what’s required to get through an audit. For these reasons, the cost of an audit across your 100 dev teams can be more than 100x the cost of a single audit at the centre.
Factor Two: Engineer Capability
Development teams vary significantly in their willingness to take on work and responsibilities outside their existing domain of expertise. This can have a significant effect on who does what.
Anecdote: I once worked for a business that had a centralised DBA team, who managed databases for thousands of teams. There were endless complaints about the time taken to get ‘central IT’ to do their bidding, and frequent demands for more autonomy and freedom.
A cloud project was initiated by the centralised DBA team to enable that autonomy. It was explained that since the teams could now provision their own database instances in response to their demands, they would no longer have a central DBA team to call on.
Cue howls of despair from the development teams that they need a centralised DBA service, as they didn’t want to take this responsibility on, as they don’t have the skills.
Another example is embedded in the title question about Terraform. Development teams often don’t want to learn the skills needed for a change of delivery approach. They just want to carry on writing in whatever language they were hired to write in.
This is where organisational structures like ‘cloud native centres of excellence’ (who just ‘advise’ on how to use new technologies), or ‘federated devops teams’ (where engineers are seconded to teams to spread knowledge and experience) come from. The idea with these ‘enabling teams’ is that once their job is done they are disbanded. Anyone who knows anything about political or organisational history knows that these plans to self-destruct often don’t pan out that way, and you’re either stuck with them forever, or some put-upon central team gets given responsibility for the code in perpetuity.
Factor Three: Management Capability
While the economic benefits of having a centralised team doing shared work may seem intuitively obvious, senior management in various businesses are often not able to understand its value, and manage it as a pure cost centre.
This is arguably due to assumptions arising out of internal accounting assumptions. Put simply, the value gained from centralised work is not traced back to profit calculations, so is seen as pure cost. (I wrote a little about non-obvious business value here.)
In companies with competent technical management, the value gained from centralised work is (implicitly, due to an understanding of the actual work involved) seen as valuable. This is why tech firms such as Google can successfully manage a large-scale platform, and why it gave birth to SRE and Kubernetes, two icons of tech org centralisation. It’s interesting that Amazon – with its roots in retail, distribution, and logistics – takes a radically different distributed approach.
If your organisation is not capable of managing centralised platform work, then it may well be more effective to distribute the work across the feature teams, so that cost and value can be more easily measured and compared.
Factor Four: Platform Team Capability
Here we are back to the old fashioned silo problem. One of the most common complaints about centralised teams is that they fail to deliver what teams actually need, or do so in a way that they can’t easily consume.
Often this is because of the ‘non-negotiable standards’ factor above resulting in security controls that stifle innovation. But it can also be because the platform team is not interested, incentivised, or capable enough to deliver what the teams need. In these latter cases, it can be very inefficient or even harmful to get them to do some of the platform work.
This factor can be mitigated with good management. I’ve seen great benefits from moving people around the business so they can see the constraints other people work under (a common principle in the DevOps movement) rather than just complain about their work. However, as we’ve seen, poor management is often already a problem, so this can be a non-starter.
Factor Five: Time to Market
Another significant factor is whether it’s important to keep the time to delivery low. Retail banks don’t care about time to delivery. They may say they do, but the reality is that they care far more about not risking their banking licence, not causing outages that attract the interest of regulators. In the financial sector, hedge funds, by contrast, might care very much about time to market as they are unregulated and wish to take advantage of any edge they might have as quickly as possible. Retail banks tend towards centralised organisational architectures, while hedge funds devolve responsibility as close to the feature teams as possible.
So, Who Should Write the Terraform?
Returning to the original question, the question of ‘who should write the Terraform?’ can now be more easily answered, or at least approached. Depending on the factors discussed above, it might make sense for them to be either centralised or distributed.
More importantly, by not simply assuming that there is a ‘right’ answer, you can make decisions about where the work goes with your eyes open about what the risks, trade-offs, and systemic preferences of your business are.
Whichever way you go, make sure that you establish which entity will be responsible for maintaining the resulting code as well as producing it. Code, it is important to remember, is an asset that needs maintenance to remain useful and if this is ignored there could be great confusion in the future.
Having the privilege of working in software in the 2020s, I hear variations on the following ideas expressed frequently:
‘There must be some direct relationship between your work and customer value!’
‘The results of your actions must be measurable!’
These ideas manifest in statements like this, which sound very sensible and plausible:
‘This does not benefit the customer. This is not a feature to the customer. So we should not do it.’
‘We are not in the business of doing X, so should not focus on it. We are in the business of serving the customer’
‘This does not improve any of the key metrics we identified’
I want to challenge these ideas. In fact, I want to turn them on their head:
Many peoples’ work generate value by focussing on things that appear to have no measurable or apparently justifiable customer benefit.
Moreover, judgements on these matters are what people are (and should be) paid to exercise.
Alex Ferguson and Canteen Design
To encapsulate these ideas I want to use an anecdote from the sporting world, that unforgiving laboratory of success and failure. In that field, the record of Alex Ferguson, manager of Manchester United (a UK football, or soccer team) in one of their ‘golden eras’ from 1986 to 2013, is unimpeachable. During those 27 years, he took them from second-from-bottom in the UK premier league table in 1986 to treble trophy winners in Europe in 1998-1999.
Fortunately, he’s recorded his recollections and lessons in various books, and these books provide a great insight into how such a leader thinks, and what they’re paid to do.
Alex Ferguson demonstrating how elite-level sports teams can be coached to success
Now, to outsiders, the ‘business value’ he should be working towards is obvious. Some kind of variation of ‘make a profit’, or ‘win trophies’, or ‘score more goals than you concede in every match’ is the formulation most of us would come up with. Obviously, these goals break down to sub-goals like:
Buy players cheaply and extract more value from them than you paid for
Optimise your tactics for your opponents
Make players work hard to maintain fitness and skills
Again, we mortals could guess these. What’s really fascinating about Ferguson’s memoirs is the other things he focusses on, which are less obvious to those of us that are not experts in elite-level soccer.
Sometimes if I saw a young player, a lad in the academy, eating by himself, I would go and sit beside him. You have to make everyone feel at home. That doesn’t mean you’re going to be soft on them–but you want them to feel that they belong. I’d been influenced by what I had learned from Marks & Spencer, which, decades ago in harder times, had given their staff free lunches because so many of them were skipping lunch so they could save every penny to help their families. It probably seems a strange thing for a manager to be getting involved in–the layout of a canteen at a new training ground–but when I think about the tone it set within the club and the way it encouraged the staff and players to interact, I can’t overstate the importance of this tiny change.
Alex Ferguson, Leading
Now, I invite you to imagine a product owner, or scrum master for Manchester United going over this ‘update’ with him:
How does spending your time with junior players help us score more goals on Saturday?
Are we in the business of canteen architecture or soccer matches?
How do you measure the benefit of these peripheral activities?
Why are you micromanaging building design when we have paid professionals hired in to do that?
How many story points per sprint should we allocate to your junior 1-1s and architectural oversight?
It is easy to imagine how that conversation would have gone, especially given Ferguson’s reputation for robust plain speaking. (The linked article is also a mini-goldmine of elite talent management subtleties hiding behind a seemingly brutish exterior.)
Software and Decision Horizons
It might seem like managing a soccer team and working in software engineering are worlds apart, but there’s significant commonality.
Firstly, let’s look at the difference of horizon between our imagined sporting scrum master and Alex Ferguson.
The scrum master is thinking in:
Very short time periods (weeks or months)
Specific and measurable goals (score more goals!)
Alex Ferguson, by contrast, is thinking in decades-long horizons, and (practically) unmeasurable goals:
If I talk to this player briefly now, they may be motivated to work for us for the rest of their career
I may encourage others to help their peers by being seen to inculcate a culture of mutual support
I can think of a specific example of such a clash of horizons that resulted in a questionable decision in a software business.
Twenty years ago I worked for a company that had an ‘internal wiki’ – a new thing then. Many readers of this piece will know of the phenomenon of ‘wiki-entropy’ (I just made that word up, but I’m going to use it all the time now) whereby an internal documentation system gradually degrades to useless whatever the value of some of the content on there due to it getting overwhelmed by un-maintained information.
Well, twenty years ago we didn’t have that problem. We decided to hire a young graduate with academic tendencies to maintain our wiki. He assiduously ranged across the company, asking owners of pages whether the contents were still up to date, whether information was duplicated, complete, no longer needed, and so on.
The result of this was a wiki that was extremely useful, up to date, where content was easily found and minimal time was wasted getting information. The engineers loved it, and went out of their way to praise his efforts to save them from their own bad habits.
Of course, the wiki curator was first to be let go when the next opportunity arose. While everyone on the ground knew of the high value of this in saving lost time and energy chasing around bad information across hundreds of engineers, the impact was difficult or never measured, and in any case, shouldn’t the engineers be doing that themselves?
For years afterwards, whenever we engineers were frustrated with the wiki, we always cursed whoever it was that made the short-sighted decision to let his position go.
So-called ‘business people’, such as shareholders, executives, project managers, and product owners are strongly incentivised to deliver short term, which most often meant prioritise short-term goals (‘mission accomplished’) over longer-term value. Those that don’t think short-term often have a strong background in engineering and have succeeded in retaining their position despite this handicap.
What To Do? Plan A – The Scrum Courtroom
So your superiors don’t often think long term about the work you are assigned, but you take pride in what you do, and want the value of your work to be felt over a longer time than just a sprint or a project increment. And you don’t want people cursing your name as they suffer from your short-term self-serving engineering choices.
Fortunately, a solution has arisen that should handle this difference of horizon: scrum. This methodology (in theory, but that’s a whole other story) strictly defines project work to be done within a regular cadence (eg two weeks). At the start of this cadence (the sprint), the team decides together what items should go in it.
At the beginning of each cadence, therefore, you get a chance to argue the case for the improvement, or investment you want to make in the system you are working on being included in the work cadence.
The problem with this is that these arguments mostly fail because the cards are still stacked against you, in the following ways:
The cadence limit
Uncertainty of benefit
Uncertainty of completion
Uncertainty of value
Plan A Mitigators – The Cadence Limit
First, the short-term nature of the scrum cadence has an in-built prejudice against larger-scale and more speculative/innovative ideas. If you can’t get your work done within the cadence, then it’s more easily seen as impractical or of little value.
The usual counter to this is that the work should be ‘broken down’ in advance to smaller chunks that can be completed within the sprint. This often has the effect of making the work seem either profoundly insignificant (‘talk to a young player in the canteen’), and of losing sight of the overall picture of the work being proposed (‘change/maintain the culture of the organisation’).
Plan A Mitigators – Uncertainty of Benefit
The scrum approach tries to increment ‘business value’ in each sprint. Since larger-scale and speculative/innovative work is generally riskier, it’s much harder to ‘prove’ the benefit for the work you do in advance, especially within the sprint cadence.
The result is that such riskier work is less likely to be sanctioned by the scrum ‘court’.
Plan A Mitigators – Uncertainty of Completion
Similarly, there is an uncertainty as to whether the work will get completed within the sprint cadence. Again, this makes the chances of success arguing your case less likely.
Plan A Mitigators – Uncertainty of Value
‘Business Value’ is a very slippery concept the closer you look at it. Mark Schwartz wrote a book I tell everyone to read deconstructing the very term, and showing how no-one really knows what it means. Or, at the very least, it means very different things to different people.
The fact is that almost anything can be justified in terms of business value:
Spending a week on an AWS course
As an architect, I need to ensure I don’t make bad decisions that will reduce the flow of features for the product
Spending a week optimising my dotfiles
As a developer, I need to ensure I spend as much time coding efficiently as possible so I can produce more features for the product
Tidying up the office
As a developer, I want the office to be tidier so I can focus more effectively on writing features for the product
Hiring a Michelin starred chef to make lunch
As a developer, I need my attention and nutrition to be optimised so I can write more features for the product without being distracted by having to get lunch
The problem with all these things is that they are effectively impossible to measure.
There’s generally no objective way to prove customer value (even if we can be sure what it is). Some arguments just sound rhetorically better to some ears than others.
If you try and justify them within some of business framework (such as improving a defined and pre-approved metric), you get bogged down in discussions that you effectively can’t win.
How long will this take you?
“I don’t know, I’ve never done this before”
What is the metric?
“Um, culture points? Can we measure how long we spend scouring the wiki and then chasing up information gleaned from it? [No, it’s too expensive to do that]”
‘Plan A’ Mitigators Do Have Value
All this is not to say that these mitigators should be removed, or have no purpose. Engineers, as any engineer knows, can have a tendency to underestimate how hard something will be to build, how much value it will bring, and even do ‘CV-driven development’ rather than serve the needs of the business.
The same could be said of soccer managers. But we still let soccer managers decide how to spend their time, and more so the more the more experienced they are, and the more success they have demonstrated.
But…
In any case, I have been involved in discussions like this at numerous organisations that end up taking longer than actually doing the work, or at least doing the work necessary to prove the value in proof of concept form.
So I mostly move to Plan B…
What To Do? Plan B – Skunkworks It
Plan B is to skip court and just do the work necessary to be able to convince others that yours is the way to go without telling anyone else. This is broadly known as ‘skunkworks‘.
The first obvious objection to this approach is something like this:
‘How can this be done? Surely the the time taken for work in your sprint has been tightly defined and estimated, and you therefore have no spare time?’
Fortunately this is easily solved. The thing about leaders who don’t have strong domain knowledge is that their ignorance is easily manipulated by those they lead. So the workers simply bloat their estimates, telling them that the easy official tasks they have will take longer than they actually will take, leaving time left over for them to work on the things they think are really important or valuable to the business.
Yes, that’s right: engineers actually spend time they could be spending doing nothing trying to improve things for their business in secret, simply because they want to do the right thing in the best way. Just like Alex Ferguson spent time chatting to juniors, and micromanaging the design of a canteen when he could have enjoyed a longer lunch alone, or with a friend.
Yes, that’s right: engineers actually spend time they could be spending doing nothing trying to improve things for their business in secret, simply because they want to do the right thing in the best way.
Good leaders know this happens, even encourage it explicitly. A C-level leader (himself a former engineer) once said to me “I love that you hide things from me. I’m not forced to justify to my peers why you’re spending time on improvements if I don’t know about them and just get presented with a solution for free.”
The Argument
When you get paid to make decisions, you are being paid to exercise your judgement exactly in the ways that can’t be justified within easily measurable and well-defined metrics of value.
If your judgement could be quantified and systematised, then there would be no need for you to be there to make those judgements. You’d automate it.
This is true whether you are managing a soccer team, or doing software engineering.
Making software is all about making classes of decision that are the same in shape as Alex Ferguson’s. Should I:
Fix or delete the test?
Restructure the pipeline because its foundations are wobbly, or just patch it for now?
Mentor a junior to complete this work over a few days, or finish the job myself in a couple of hours?
Rewrite this bash script in Python, or just add more to it?
Spend the time to containerise the application and persuade everyone else to start using Docker, or just muddle along with hand-curated environments as we’ve always done?
Spend time getting to know the new joiner on the team, or focus on getting more tickets in the sprint done?
Each of these decisions has many consequences which are unclear and unpredictable. In the end, someone needs to make a decision where to spend the time based on experience as the standard metrics can’t tell you whether they’re a good idea.
Conclusion
At the heart of this problem in software is what I call the ‘bricklayer fallacy’. Many view software engineering as a series of tasks analogous to laying bricks: once you are set up, you can say roughly how long it will take to do something, because laying one brick takes a predictable amount of time.
This fallacy results in the treatment of software engineering as readily convertible to what business leaders want: a predictable graph of delivery over time. Attempts to maintain this illusion for business leaders results in the fairy stories of story points, velocity, and burn-down charts. All of these can drive the real value work underground.
If you want evidence of this not working, look here. Scrum is conspicuously absent as a software methodology at the biggest tech companies. They don’t think of their engineers as bricklayers.
Soccer managers don’t suffer as much from this fallacy because we intuitively understand that building a great soccer team is not like building a brick wall.
But software engineering is also a mysterious and varied art. It’s so full of craft and subtle choices that the satisfaction of doing the job well exceeds the raw compensation for attendance and following the rules. Frequently, I’ve observed that ‘working to rule’ gets the same pay and rewards as ‘pushing to do the right thing for the long term’, but results in real human misery. At a base level, your efforts and their consequences are often not even noticed by anyone.
If you remove this judgement from people, you remove their agency.
This is a strange novelty of knowledge work that didn’t exist in the ‘bricklayer’, or age of piece-work and Taylorism. In the knowledge work era, the engineers who like to actually deliver the work of true long term value get dissatisfied and quit. And paying them more to put with it doesn’t necessarily help, as the ones that stay are the ones that have learned to optimise for getting more money rather than better work. These are exactly the people you don’t want doing the work.
If you want to keep the best and most innovative staff – the ones that will come up with 10x improvements to your workflows that result in significant efficiencies, improvements, and savings – you need to figure out who the Alex Fergusons are, and give them the right level autonomy to deliver for you. That’s your management challenge.
If you enjoyed this, then please consider buying me a coffee to encourage me to do more.













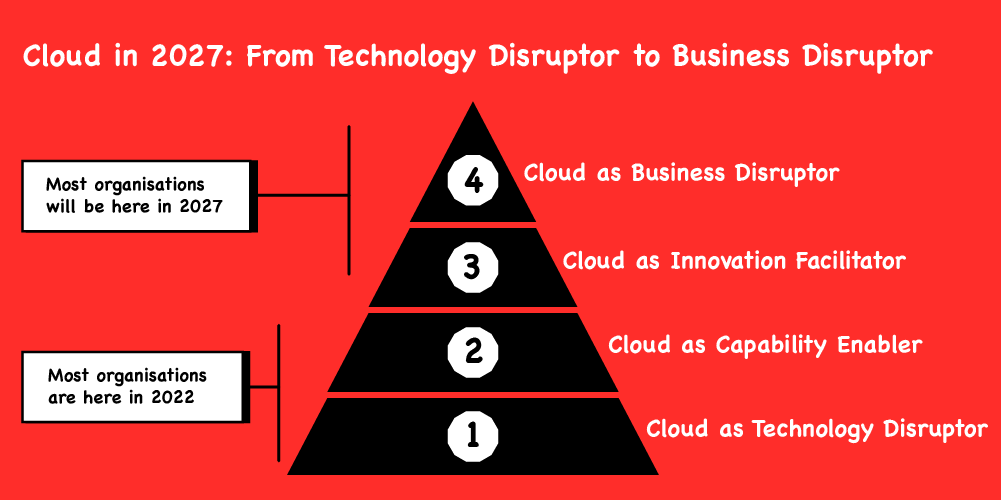 Whilst it is somewhat higher level, this pyramid is similar to our Maturity Matrix in that it helps give you a common visual reference point for a comprehensible and tangible view of both where you are, and where you are trying to get to, in your Cloud Native program. For example, it can help in discussions with technologists to ask them how the changes they are planning relate to stage four. Similarly, when talking to senior leaders about stage four, it can help to clarify whether they and their organisation have thought about the various dependencies below their goal and how they relate to each other.
Whilst it is somewhat higher level, this pyramid is similar to our Maturity Matrix in that it helps give you a common visual reference point for a comprehensible and tangible view of both where you are, and where you are trying to get to, in your Cloud Native program. For example, it can help in discussions with technologists to ask them how the changes they are planning relate to stage four. Similarly, when talking to senior leaders about stage four, it can help to clarify whether they and their organisation have thought about the various dependencies below their goal and how they relate to each other.